数据集下载地址:
链接:https://pan.baidu.com/s/1iWzxK8hlxRHh8pz46576pg 密码:tsu5
当我们完成了数据的预处理环节后,我们可以先对数据进行可视化,根据图像可以初步的判断我们的模型应该是怎么样的,如何更好地拟合,请看下面的例子:
数据集:
| Position | Level | Salary |
|---|---|---|
| Business Analyst | 1 | 45000 |
| Junior Consultant | 2 | 50000 |
| Senior Consultant | 3 | 60000 |
| Manager | 4 | 80000 |
| Country Manager | 5 | 110000 |
| Region Manager | 6 | 150000 |
| Partner | 7 | 200000 |
| Senior Partner | 8 | 300000 |
| C-level | 9 | 500000 |
| CEO | 10 | 1000000 |
#首先还是导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
import statsmodels.formula.api as sm#加载数据,由于数据样本少,不做分片
dataset = pd.read_csv('Position_Salaries.csv')
# X = dataset.iloc[:,1].values #shape -- (10,)是个向量,可是我们需要进入训练的变量需要是一个矩阵
X = dataset.iloc[:,1:2].values #shape -- (10, 1) 矩阵
Y = dataset.iloc[:,2].values #shape -- (10,)是个向量#可视化数据
plt.figure(figsize=(10,14))
plt.subplot(211)
plt.scatter(X,Y)
plt.savefig('scatter.png')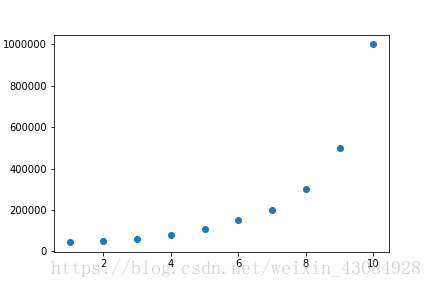
数据描点完成了,根据图像容易得出一元方程拟合效果不会太好。
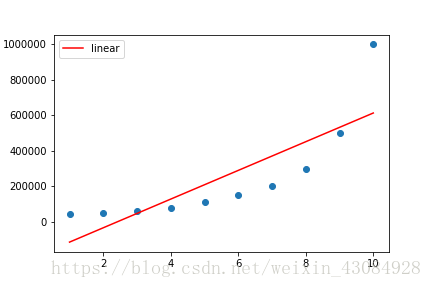
实际也正如我们料想的一致
观察图一,我们可以选用多项式来解决这个回归问题
- 对自变量进行矩阵转化,转化为有不同次数的矩阵
# 对X进行多次项处理
Poly = PolynomialFeatures(degree=2) #参数degree是限定生成的X矩阵的最高次数
X_poly = Poly.fit_transform(X)输出X_poly结果如下:
#这个操作自动添加了常数项的系数(第一列)第二列是一次项,第二列是二次项
[[ 1. 1. 1.]
[ 1. 2. 4.]
[ 1. 3. 9.]
[ 1. 4. 16.]
[ 1. 5. 25.]
[ 1. 6. 36.]
[ 1. 7. 49.]
[ 1. 8. 64.]
[ 1. 9. 81.]
[ 1. 10. 100.]]poly_reg = sm.OLS(endog=Y,exog=X_poly).fit()
Y_pre2 = poly_reg.predict(X_poly)
plt.plot(X,poly_reg.predict(X_poly) ,color = 'black',label = 'poly_degree=2')
plt.legend()
plt.savefig('lin&poly.png')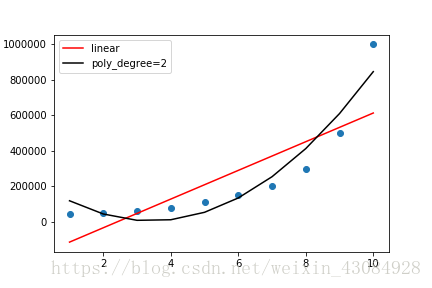
显然拟合也不是特别好。可以通过 提高多项式次数来达到更好的拟合度,小心 过度拟合问题
Poly = PolynomialFeatures(degree=3) #参数degree是限定生成的X矩阵的最高次数
X_poly = Poly.fit_transform(X)
poly_reg = sm.OLS(endog=Y,exog=X_poly).fit()
Y_pre2 = poly_reg.predict(X_poly)
plt.plot(X,poly_reg.predict(X_poly) ,color = 'green',label = 'poly_degree=3')
plt.legend() #提高到3次基本拟合效果很好了
plt.savefig('lin&poly3.png')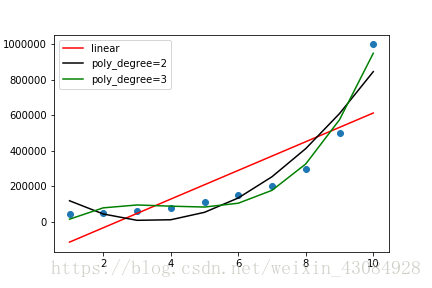
提高到3次基本拟合效果很好了
最后对图像进行优化处理,上述图像由于自变量的间距相对较大,图像不够平滑。我们可以有如下操作:
X_grid = np.arange(min(X),max(X),0.1)
X_grid = X_grid.reshape(len(X_grid),1)
plt.plot(X_grid, poly_reg.predict(Poly.fit_transform(X_grid)) ,color = 'green',label = 'poly_degree=3')
plt.legend()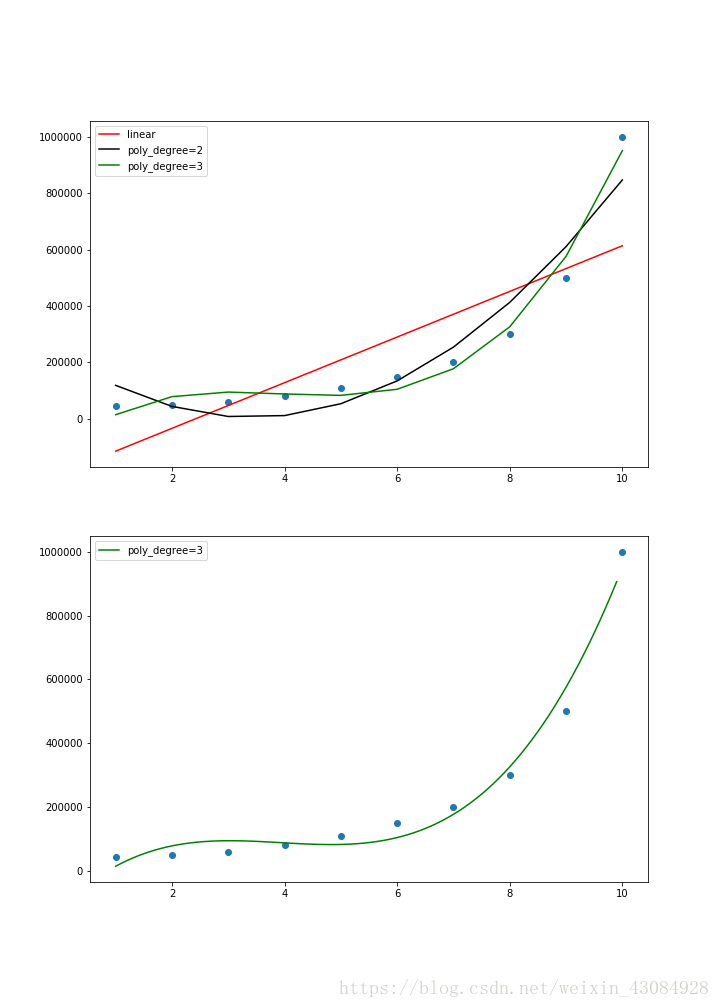
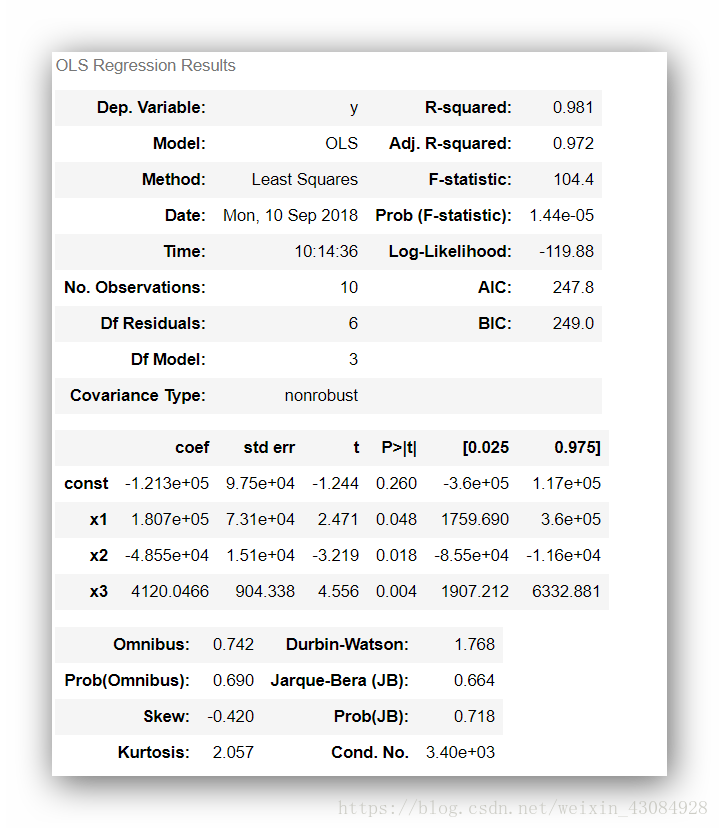
回归器信息: