《Fast R-CNN》论文解读
本文作者是Ross Girshick,和R-CNN作者一样。
概述
前面提到端到端的检测框架是很难实现的,那么先把除了region proposal的部分统一起来。Fast R-CNN贡献就在于把特征提取,SVM,Bounding box regression统一到一个框架里面了。
Fast R-CNN
先说点题外话,如何阅读一篇论文?对于深度学习方面的论文,我觉得要关注以下几个问题:1、网络结构是什么样子的,也就是说前向传播的路径是什么样的;2、如何进行训练,包括训练的样本是什么,使用了什么样的训练方法,如何选择超参数。对于一些细枝末节的问题,如果不打算重现的话也没有必要深入去研究。从这个角度来说,网上很多的资料质量实在不怎么样,写的没有条理。回到本文来看,我从我的角度给出这篇论文的解读。
网络结构
在Fast R-CNN中,候选区域生成(region proposal)仍然是独立于系统的,本文的贡献在于将特征提取、目标分类、边框回归统一到了一个框架下面。
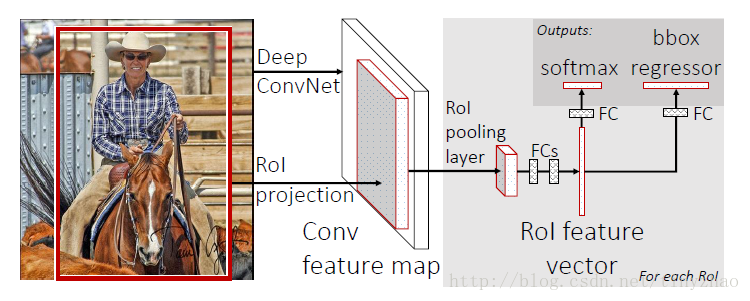
这个网络的输入是原始图片和候选区域RoI位置,输出是分类类别和bbox回归值。将原始图片输入到网络中,在网络的最后一个卷积层根据RoI位置获得对应RoI的特征图,然后输入到Roi pooling layer,可以得到一个固定大小的特征图。将这个特征图经过2个全连接层以后得到RoI的特征,然后将特征经过全连接层,使用softmax得到分类,使用回归得到边框回归。CNN的主体结构可以来自于AlexNet,也可以来自于VGGNet。
这里唯一需要解释的就是RoI pooling layer。如果特征图上的RoI大小是
训练
网络的训练需要从下面几个方向考虑:1、训练样本是什么;2、损失函数是什么;3、如果提出了新的网络结构,网络结构的反向传播怎么做。此外,还可以关注一下超参数的选取方法,看看作者在超参数选取上有什么好的思路可以借鉴。
训练样本
从网络的前向传播可以看到,网络需要的输入是图片和RoI,输出是类别和bbox,那么训练的图片每个RoI需要提前标注好类别和bbox。
作者使用层次抽样来选取训练图片。对应每个mini-batch而言,大小为128个RoI。先从训练图片中选取2张图片,每个图片的RoI中选取64个RoI,形成这128个RoI。这样网络前面的卷积计算是可以共享的,降低了训练的复杂度。64个RoI中,25%是有类别的(
损失函数
既然这个网络是个任务的网络,前面在TCDCN上也看到过这样的多任务网络,一般就是把两个损失加权相加。这篇文章也是这样的:
损失函数第一部分是softmax的损失,第二部分是bbox regression的损失。其中
其他
关于RoI层如何反向传播的,这个其实并不需要做太多关注,毕竟现在大多数深度学习框架可以自动求导。
作者又提到如何解决不同尺度不变的问题,关于尺度不变我的理解是不同尺度下目标的特征不会发生明显变化,在不同尺度都能检测到目标。作者提出两张办法:一种是brute-force approach,将所有的图片缩放到相同尺度,网络直接学习尺度不变的检测;还有一种是构建图像金字塔,测试时候使用图像金字塔近似对每个RoI归一化,就是从金字塔里面寻找一个尺度,使得RoI大小接近224*224,训练的时候随机从金字塔中选取一个尺度作为数据增强的手段,也可以看做是不同大小的RoI使用不同尺度的图片进行特征提取。本文发现深度网络能够直接提取尺度不变的特征,没有必要使用金字塔。
作者还提到使用SVD压缩全连接层的方法,这个方法可以加速全连接层的运算。SVD可以把一个大的权重矩阵拆分成两个小的矩阵,从而降低运算量。
总结
Fast R-CNN将特征提取、分类、边框回归纳入到同一个框架,使得这部分的运算速度大大提高。现在系统的瓶颈终于到了Region proposal了,Faster R-CNN将对这一步做出改进。