版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012266559/article/details/65639171
先上源码
参数说名:
- source :gzip格式流内容。
- len: gzip流长度
- dest: 解压后字符流指针
- gzip: 压缩标志,非0时解压gzip格式,否则按照zip解压
说明:代码经过测试。解压后内容printf或者cout出来是乱码的,保存为文件是可以的,如果文件还是乱码,以utf-8打开就能正常显示(Windows默认Ansi编码,编码区别自己百度)。
#ifndef __GUNZIP_H__
#define __GUNZIP_H__
#include "zlib.h"
#include "stdlib.h"
#include "string.h"
#define CHUNK 64
int inflate_read(unsigned char *source, int len, unsigned char **dest, int gzip)
{
int ret;
unsigned have;
z_stream strm;
unsigned char out[CHUNK];
int totalsize = 0;
/* allocate inflate state */
strm.zalloc = Z_NULL;
strm.zfree = Z_NULL;
strm.opaque = Z_NULL;
strm.avail_in = 0;
strm.next_in = Z_NULL;
if(gzip)
ret = inflateInit2(&strm, 47);
else
ret = inflateInit(&strm);
if (ret != Z_OK)
return ret;
strm.avail_in = len;
strm.next_in = source;
/* run inflate() on input until output buffer not full */
do {
strm.avail_out = CHUNK;
strm.next_out = out;
ret = inflate(&strm, Z_NO_FLUSH);
//assert(ret != Z_STREAM_ERROR); /* state not clobbered */
switch (ret) {
case Z_NEED_DICT:
ret = Z_DATA_ERROR; /* and fall through */
case Z_DATA_ERROR:
case Z_MEM_ERROR:
inflateEnd(&strm);
return ret;
}
have = CHUNK - strm.avail_out;
totalsize += have;
*dest = (unsigned char*)realloc(*dest,totalsize);
memcpy(*dest + totalsize - have, out, have);
} while (strm.avail_out == 0);
/* clean up and return */
(void)inflateEnd(&strm);
return ret == Z_STREAM_END ? Z_OK : Z_DATA_ERROR;
}
#endif说明:上树源码并不验证文件内容完整性。
编译需要zlib库支持,连接选项’-lz’,如果提示错误安装zlib1g, zlib1g-dev.
解压网页
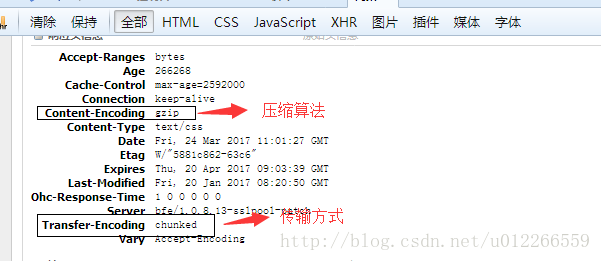
现在网站为了减小带宽占用,会对传输内容做压缩。nginx就默认开启gzip压缩。通过浏览器(火狐,chrome)f12可以查看当前页面传输格式。’Content-Encoding’ 头域指明文件的压缩算法;’Content-Length’指明传输文件的长度;’Transfer-Encoding’指明传输形式,如图中的‘chunked’表示块传输(具体自己百度)。其中’Content-Length’与’Transfer-Encoding’是一对矛盾的存在,而这只能有其一。块传输允许服务器再不知道要回应多少内容时候先传输一部分,在结束时候明显标记技术。
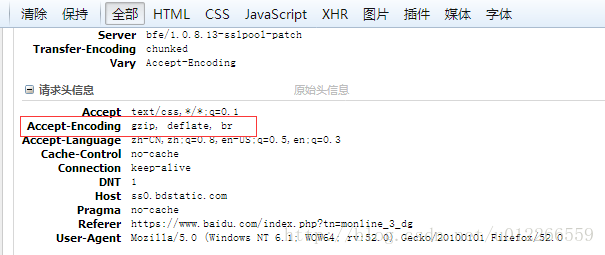
网站会根据客户端的请求决定是否对内容进行压缩,浏览器HTTP请求头有’Accept-Encoding’ 头域指定可以接受的内容形式。
步骤
- 解压缩网页需要判断压缩内容开始的位置,压缩内容开始是在http头部结束位置,HTTP协议规定HTTP头域每一个标签结束需要以’\r\n’结束,在头结束位置以’\r\n’与内容分割。也就是http头结束是’\r\n\r\n’,在这之后就是压缩内容。
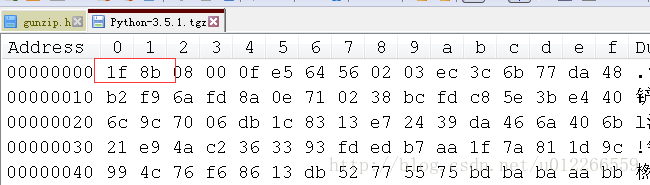
- gzip格式是以’0x1f 0x8b’开始的。
- 文件长度:如果未采取块传输,HTTP 响应的 ‘Content-Length’就是压缩内容的长度。如果采取块传输需要缓存每一部分,直到结束。因为压缩不是按块压缩的,而是分块传输的gzip实体。
最后建议:如果采用本代码进行解压网页,不是很建议,自己需要做的工作比较多,需要缓存,重组,解压。有另一种简单方式是利用’libcurl’,libcurl 支持自解压,只需要设置 CURLOPT_ENCODING 选项。