版权声明:本文为博主原创文章,欢迎交流分享,未经博主允许不得转载。 https://blog.csdn.net/qjf42/article/details/82150923
从Gradient Descent(梯度下降) 到Gradient Boosting(梯度提升)
首先说明,中文看起来是反义,但实际上是两个东西,和Gradient Descent类似的那个叫Gradient Ascent(梯度上升)
梯度下降和牛顿法
优化中有两种常见的方法,梯度下降(GD)和牛顿法,可以分别认为是目标函数基于泰勒展开的一阶和二阶版本,简单说一下:
- 目标:
argminxf(x) (以一元函数为例)(这里写
x,实际机器学习优化中是参数
w)
- 通用思路:找一个
方向
Δx,再找一个步长
η,
x←x+ηΔx
- 求方向的两种方法
- 梯度下降
一阶展开:
f(x)≈f(x0)+f′(x0)(x−x0)=f(x0)+f′(x0)Δx
可以发现要达到min需要的 方向
Δx=−f′(x0)
- 牛顿法
二阶展开:
f(x)≈f(x0)+f′(x0)Δx+21f′′(x0)(Δx)2
二次函数优化可以得到 方向
Δx=−f′′(x0)f′(x0)
- 步长可以通过line search进一步得到,但因为需要解另一个优化问题,比较麻烦,所以更常见的做法是人为指定一个
学习率(learning rate),具体的方法有很多,尤其在DL领域
- 最终收敛后,通过前面一系列的迭代,
x∗=x0+∑k=1MηkΔxk,其中
M为迭代次数,
x0是初始值
加法模型
上面提到的函数优化方法 是在已知函数的具体形式,如
f(w)=wTx时,
那么如果函数的具体形式未知,怎么办呢?
-
假设我们学习的目标
y=F(x),其中
F(x)的具体形式未知,损失函数为
L(x,F(x)),我们把损失函数“脱离”
x来看一下,即
L(F),这时损失函数就是
F的函数了,而F假设是一个函数的函数(这时优化问题就变成了一个泛函求极值的问题,需要用变分?(我也不懂我在说什么))
-
套用上面的思路,我们认为函数是一类特殊的变量(类似求导的链式法则中,中间变量其实都是函数值),那么方法就是(仿上面的写法):
- 目标:
argminFL(F)
- 思路:找一个
方向
f(也是一个函数,可以认为是函数F的变量),再找一个步长
η,
F←F+ηf
- 最终收敛后,
F也可以写为一系列函数之和,即
F∗(x)=f0(x)+∑k=1Mηkfk(x),其中
M为迭代次数,
f0是初始值,我们称这种形式为
加法模型(additive model)
-
f的形式可以是任意已知的模型,如:决策/回归树,逻辑回归等
- 这里的每一步方向都是一个函数,这种思路称之为
boosting,每一个
f称之为base/weak learner,下面我们看gradient是怎么回事
- 求方向的两种方法
- 梯度下降
一阶展开:
L(F)≈L(Fm−1)+(∂F∂L(F)∣∣∣F=Fm−1)fm
此时方向就是负导数
−L′=−∂F∂L(F)∣∣∣F=Fm−1
其中,
Fm−1=f0(x)+∑k=1m−1ηkfk(x)
- 牛顿法
二阶展开:
L(F)≈L(Fm−1)+L′∣F=Fm−1fm+21L′′∣F=Fm−1fm2
可得 方向是
−F′′F’∣F=Fm−1
- 其中的梯度
L′=∂F∂L(F)是什么呢?
- 这里我们把
F看做一般的变量(当做
x看)
- 例如,当损失函数
L是平方误差时,
L=21(y−F)2→−L′=y−F
- 这里就解释了为什么很多地方都说GB是在***拟合残差***,因为在损失函数为平方误差这种特殊情况下,残差和梯度
−L′是一样的,即
−L′∣F=Fm−1=y−Fm−1(x)
- 当损失函数是其他形式时,如:Logistic loss, Huber loss,方法也是如此,只用求个导,再把当前拟合的
Fm−1(x)代进去就好了
- 二阶导也是这么算
- 刚才我们计算的都是
L′(F(xtrain))或者
L′′(F(xtrain)),其中
xtrain是训练集中的值,是有限集,而我们真正要求的是
fk(x)这个函数的形式
- 那么,套用supervised learning的思路,
ytrain就是刚才求的方向,如:
−F′′F’∣F=Fm−1(xtrain)(可以叫这个pseudo y:
y~)
- 之后,就可以利用我们知道的各种有监督学习的方法来拟合,如:回归,决策树等
- 步长依然通过line search或设定学习率得到
-
以上就完成了从gradient descent到gradient boosting的转变,核心变化是优化的变量从
x变成了
F(x)(boosting),要求的梯度从
f′(x)变成了
F′∣Fm−1(gradient,而且是个函数,需要拟合)
-
这类方法叫做Gradient Boosting Machine(GBM),当上面提到的方向函数是决策/回归树时,就是Gradient Boosting Decisison/Regression Tree(GBDT)了
-
原始的GBM paper[1] 中,只用到了一阶信息,在XGBoost和LightGBM中,都用到了二阶的信息来加快收敛,并且加入了正则项减少过拟合,同时优化了树模型的构建
-
附GBM的一阶方法的思路(from [1])
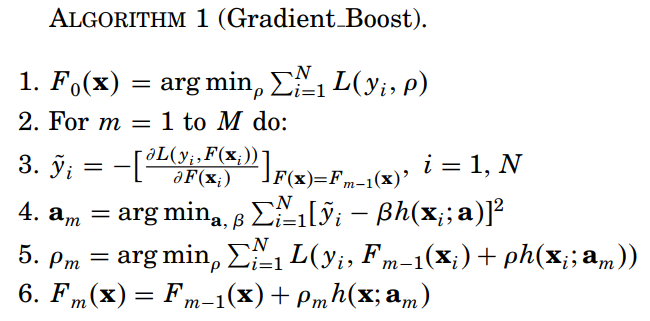
其中,第4行拟合
fk(x)时用了均方误差,第5行是line search
LightGBM和XGBoost 区别
|
lightgbm |
xgboost |
| 数据排序分组方式 |
histogram-based
1. 构建时遍历O(#data)分桶,使用时O(#bin)
2. 离散化减小内存消耗和并行时通信消耗 |
pre-sort-based
1. 始终是O(#data)(看参数也有基于直方图的,但是paper没有仔细说明,而且应该是只在split时才会构建,开销并未减少?) |
| Tree growth |
Leaf-wise (best-first):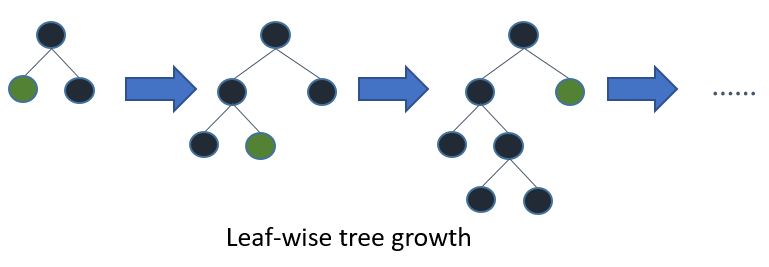
1. lower loss
2. 可能overfit,所以加max depth参数 |
Level-wise: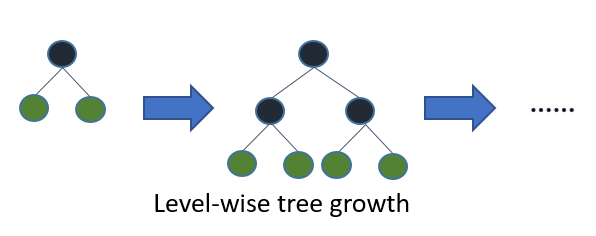 |
| Categorical特征 |
支持 |
不支持,要先做onehot encoding |
Reference
- J. Friedman. Greedy function approximation: a gradient
boosting machine. 2001