使用前先安装两个库:python3 -m pip install numpy pandas
注意因为我把我自己的python.exe命令成了python3.exe(因为系统里有多个版本的python存在),所以上面的命令里用的是python3。
numpy库:
NumPy是高性能科学计算和数据分析的基础包。
numpy的优势是矩阵运算,最大的特点是引入了ndarray-多维数组的概念。在ndarray中,每个[]就代表1维。这里和matlab或者C++或者fortran都很不一样,没有行优先或者列优先的概念。numpy还有一个数据结构是mat。例如mat结构可以非常方便地做转置(matName.T),求逆(matName.I),求伴随矩阵(matName.A)。
numpy的基本属性:
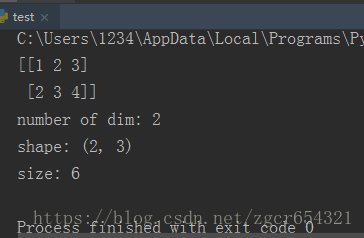
import numpy as np
array = np.array([[1, 2, 3], [2, 3, 4]])
print(array)
print('number of dim:', array.ndim)
# array.ndim可以知道array的行数
print('shape:', array.shape)
# array.shapre可以知道array的行数和列数
print('size:', array.size)
# array的元素数运行截图如下:
创建array:
import numpy as np
a = np.array([2, 23, 4], dtype=np.int)
# 定义一个数组和其元素类型,可以定义int,int64,float,float64等
print(a)
print(a.dtype)
b = np.array([[2, 23, 4], [2, 32, 4]])
# 定义一个矩阵
print(b)
c = np.zeros((3, 4))
# 定义一个三行四列的零矩阵
print(c)
d = np.ones((3, 4))
# 定义一个三行四列全为1的矩阵
print(d)
e = np.arange(10, 20, 2)
# 生成一个有序数组,从10开始,间隔为2,到20截止(不包括20)
print(e)
f = np.arange(12).reshape((3, 4))
print(f)
# 生成一个有序序列,0到11,但重新定义行和列为3行4列
g = np.linspace(1, 10, 5)
# 生成一个从1到10分成5段的数列,也可以用reshape
print(g)运行结果如下:
[ 2 23 4]
int32
[[ 2 23 4]
[ 2 32 4]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[10 12 14 16 18]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[ 1. 3.25 5.5 7.75 10. ]numpy的基础运算:
import numpy as np
a = np.array([10, 20, 30, 40])
b = np.arange(4)
print(a, b)
c = a - b
print(c)
# 两个元素数量相同的数组相对应的元素相减并得到新数组
d = a + b
print(d)
# 两个元素数量相同的数组相对应的元素相加并得到新数组
e = b ** 2
print(e)
# 数组b每个元素平方并得到新数组
f = 10 * np.sin(a)
print(f)
# 对a的每个元素求其sin值再乘10并得到新数组,cos和tan类似
print(b)
print(b < 3)
# 判断b中哪些元素小于3,>和==类似
g = np.array([[1, 1], [0, 1]])
h = np.arange(4).reshape((2, 2))
print(g)
print(h)
# 创建两个二维数组
i = g * h
i_dot = np.dot(g, h)
print(i)
print(i_dot)
# 两种矩阵乘法,i是各个对应元素逐个相乘的结果,i_dot是矩阵乘法的结果运行结果如下:
[10 20 30 40] [0 1 2 3]
[10 19 28 37]
[10 21 32 43]
[0 1 4 9]
[-5.44021111 9.12945251 -9.88031624 7.4511316 ]
[0 1 2 3]
[ True True True False]
[[1 1]
[0 1]]
[[0 1]
[2 3]]
[[0 1]
[0 3]]
[[2 4]
[2 3]]生成一个随机数列并求随机数列的和、最大值、最小值:
import numpy as np
a = np.random.random((2, 4))
print(a)
# 生成一个随机数列
print(np.sum(a))
print(np.min(a))
print(np.max(a))
# 找出随机数列的和、最小值、最大值
print(np.sum(a, axis=1))
# axis=1表示在行中求和。axis=0表示在列中求和。也可以用在min和max中。运行结果如下:
[[0.24095164 0.05673842 0.43618037 0.6945017 ]
[0.32606988 0.86297934 0.68559744 0.29434735]]
3.5973661293334143
0.05673841957595571
0.862979341363446
[1.42837212 2.168994 ]找出最小值和最大值的索引、计算平均值和中位数、数组排序、矩阵乘法等:
import numpy as np
A = np.arange(2, 14).reshape((3, 4))
print(A)
print(np.argmin(A))
# 找出最小值的下标索引
print(np.argmax(A))
# 找出最大值的下标索引
print(np.mean(A))
print(A.mean())
print(np.average(A))
# 三种计算平均值的方法
print(np.median(A))
# 求中位数
print(A)
print(np.cumsum(A))
# 求出并显示出逐步累加的结果
print(np.diff(A))
# 求出并显示出每两个相邻元素的差的结果
print(np.nonzero(A))
# 找出非零元素对应的行数和列数,行数和列数分别用一个数组表示
B = np.arange(14, 2, -1).reshape((3, 4))
print(B)
print(np.sort(B))
# 数组排序,注意是逐行排序
print(np.transpose(A))
print(A.T)
# 两种矩阵转置的方法
print((A.T).dot(A))
# A矩阵的转置和A矩阵做矩阵乘法
print(np.clip(A, 5, 9))
# A矩阵中所有小于5的数都等于5,所有大于9的数都等于9运行结果如下:
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
0
11
7.5
7.5
7.5
7.5
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
[ 2 5 9 14 20 27 35 44 54 65 77 90]
[[1 1 1]
[1 1 1]
[1 1 1]]
(array([0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], dtype=int32), array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int32))
[[14 13 12 11]
[10 9 8 7]
[ 6 5 4 3]]
[[11 12 13 14]
[ 7 8 9 10]
[ 3 4 5 6]]
[[ 2 6 10]
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]]
[[ 2 6 10]
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]]
[[140 158 176 194]
[158 179 200 221]
[176 200 224 248]
[194 221 248 275]]
[[5 5 5 5]
[6 7 8 9]
[9 9 9 9]]numpy的索引查找:
import numpy as np
A = np.arange(3, 15)
print(A)
print(A[3])
# 在一维数组中,下标与列表中的下标一样
B = np.arange(3, 15).reshape(3, 4)
print(B)
print(B[2])
# 在二维数组中,下标2则表示是行号2的所有元素
print(B[1][1])
print(B[1, 1])
# 上面两种方法索引出的是行号1,列号1的元素
print(B[2, :])
print(B[:, 1])
# 索引出的是行号2的所有元素,列也可以类似操作
print(B[1, 1:3])
# 索引的是行号1 列号1到列号3(不包括列号3那列)的元素
for row in B:
print(row)
# 迭代输出B中的每一行元素
for column in B.T:
print(column)
# 迭代输出B中的每一列元素
print(B.flatten())
# 打印出返回出被改成一行的序列
for item in B.flat:
print(item)
# 迭代输出B中的每一个元素运行结果如下:
[ 3 4 5 6 7 8 9 10 11 12 13 14]
6
[[ 3 4 5 6]
[ 7 8 9 10]
[11 12 13 14]]
[11 12 13 14]
8
8
[11 12 13 14]
[ 4 8 12]
[8 9]
[3 4 5 6]
[ 7 8 9 10]
[11 12 13 14]
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]
[ 6 10 14]
[ 3 4 5 6 7 8 9 10 11 12 13 14]
3
4
5
6
7
8
9
10
11
12
13
14numpy中的array的合并:
import numpy as np
A = np.array([1, 1, 1])
B = np.array([2, 2, 2])
print(np.vstack((A, B)))
# 上下合并。A在上面一行,B在下面一行。vertical stack
print(np.hstack((A, B)))
# 左右合并。A在一行的前面,B在同一行的后面。horizontal stack
C = A[:, np.newaxis]
D = B[:, np.newaxis]
# np.newaxis,加在:前面表示在行上加了一个维度,如果在:后面表示在列后面加了一个维度
print(np.vstack((C, D)))
print(np.hstack((C, D)))
E = np.concatenate((A, B, B, A), axis=0)
# 可以进行多个array的合并,可以要求在列上合并axis=0,或要求在行上合并axis=1运行结果如下:
[[1 1 1]
[2 2 2]]
[1 1 1 2 2 2]
[[1]
[1]
[1]
[2]
[2]
[2]]
[[1 2]
[1 2]
[1 2]]numpy中array的分割:
import numpy as np
A = np.arange(12).reshape((3, 4))
print(A)
print(np.split(A, 2, axis=1))
# 每两列分割出来,axis=1表示分割列,注意split只能进行等分
print(np.array_split(A, 3, axis=1))
# array_split进行不等分割
print(np.vsplit(A, 3))
print(np.hsplit(A, 2))
# vsplit也可以进行纵向不等分割,hsplit也可以进行横向不等分割运行结果如下:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2],
[ 6],
[10]]), array([[ 3],
[ 7],
[11]])]
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]numpy copy&deep copy:
先看我们普通赋值。把arange()产生的数列赋给其他变量后。任意一个指向该数列的变量对数列进行了修改。则其他变量打印出的该数列也被修改了。
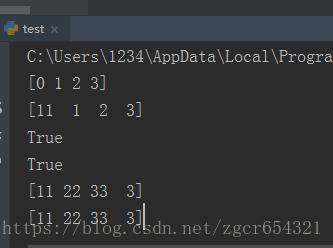
import numpy as np
a = np.arange(4)
print(a)
b = a
c = a
d = b
# b,c,d原始赋值都是数列a
a[0] = 11
# 现在把a[0]修改为11,数列a也变了
print(a)
# 改变了A中的某项,则b、c也被改变了,因为b=a,c=a
print(b is a)
# d=b,b=a,可以看到a中某项改变了,d也改变了
print(d is a)
# 现在我们改变d
d[1:3] = [22, 33]
print(d)
print(a)
# 可以看到a也随着d一起改变了,因为a就是b,c,d。运行结果如下:
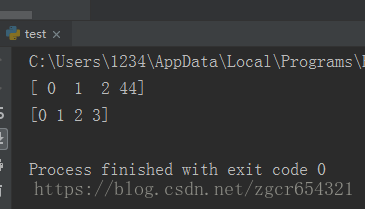
如果我们想把a数列的值赋给b,但是不想修改a或者修改b后导致另一个也一起被改动了,该怎么办呢?
import numpy as np
# 如果想把a的值赋给b,但是又不想关联起来(即修改a或修改b会影响另外一个数列)
a = np.arange(4)
b = a.copy()
# 这种copy方式又叫deep copy
a[3]=44
print(a)
print(b)
# 可以看到此时b没有被改变了运行结果如下:
pandas库:
pandas 是基于NumPy 的一种工具。
numpy可以从来创建一个序列或者矩阵,而pandas更像是一个字典,pandas可以给numpy生成的序列或矩阵的行或列建立索引。
pandas生成索引:
import numpy as np
import pandas as pd
s = pd.Series([1, 3, 6, np.nan, 44, 1])
print(s)
# 可以看到打印出来的结果中每个元素前面都加上了序号,并且最后打印了数据类型。
dates = pd.date_range('20160101', periods=6)
# 创建一个索引,没有创建索引,则默认是类似上面的0,1,2,3...
print(dates)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['a', 'b', 'c', 'd'])
# 我们创建一个DataFrame,里面包含一个二维的numpy数组,行索引用刚才创建的dates,列索引定义为a,b,c,d
print(df)
# 打印出来可以看到行和列的索引
df1 = pd.DataFrame(np.arange(12).reshape((3, 4)))
print(df1)
# 我们再创建一个默认索引的DataFrame,打印一下,可以看到行和列都生成了默认的索引,从零开始递增,每次递增1
df2 = pd.DataFrame({'A': 1., 'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)
# 上面是另一种DataFrame的创建方法,A到F为列索引,A到F后跟的一串为该列的元素,行索引为默认的
print(df2.dtypes)
# 可以打印出每列的数据的类型
print(df2.index)
print(df2.columns)
# 我们还可以分别打印出其行索引和列索引即索引数据的类型
print(df1.describe())
# describe()方法可以用来对数字的数据进行一些统计
print(df2.T)
# 把矩阵转置
print(df2.sort_index(axis=1,ascending=False))
# 对列axis=1,进行倒序排序ascending=False
print(df2.sort_values(by='E'))
# 根据值进行排序运行结果如下:
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
a b c d
2016-01-01 -1.102940 1.156601 1.165625 1.186623
2016-01-02 1.116321 -0.003329 -1.551529 -0.362062
2016-01-03 0.056525 0.813531 -0.224231 1.993355
2016-01-04 -0.482142 -0.108111 -0.434417 -0.142115
2016-01-05 -0.554487 -0.099487 1.709231 -0.615497
2016-01-06 0.535067 1.041367 2.270268 0.648481
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Int64Index([0, 1, 2, 3], dtype='int64')
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
0 1 2 3
count 3.0 3.0 3.0 3.0
mean 4.0 5.0 6.0 7.0
std 4.0 4.0 4.0 4.0
min 0.0 1.0 2.0 3.0
25% 2.0 3.0 4.0 5.0
50% 4.0 5.0 6.0 7.0
75% 6.0 7.0 8.0 9.0
max 8.0 9.0 10.0 11.0
0 ... 3
A 1 ... 1
B 2013-01-02 00:00:00 ... 2013-01-02 00:00:00
C 1 ... 1
D 3 ... 3
E test ... train
F foo ... foo
[6 rows x 4 columns]
F E D C B A
0 foo test 3 1.0 2013-01-02 1.0
1 foo train 3 1.0 2013-01-02 1.0
2 foo test 3 1.0 2013-01-02 1.0
3 foo train 3 1.0 2013-01-02 1.0
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 train foopandas选择数据:
import numpy as np
import pandas as pd
dates = pd.date_range('20160101', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D'])
# 我们创建一个DataFrame,里面包含一个二维的numpy数组,行索引用刚才创建的dates,列索引定义为a,b,c,d
print(df)
print(df['A'], df.A)
# 选择A这一列,df['A']与df.A的效果基本相同,除了第一行稍微不同
print(df[0:3])
# 选择行号0到行号2的三行
print(df['20160102':'20160104'])
# 选择20160102到20160104这几行(包括20160104这行)
print(df.loc['20160102'])
# 以标签来选择某行
print(df.loc[:, ['A', 'B']])
# 以标签来选择某几列
print(df.loc['20160102', ['A', 'B']])
# 打印选择的行的某几列
print(df.iloc[3, 1])
# 打印行号3列号1的数据
print(df.iloc[3:5, 1:3])
# 打印选择的连续的几行和几列
print(df.iloc[[1, 3, 5], 1:3])
# 打印选择的某几行和几列(行不连续)
print(df.ix[:3, ['A', 'C']])
# 序号和标签混合筛选
print(df[df.A > 8])
# 条件筛选,筛选出A中数值>8的行运行结果如下:
A B C D
2016-01-01 0 1 2 3
2016-01-02 4 5 6 7
2016-01-03 8 9 10 11
2016-01-04 12 13 14 15
2016-01-05 16 17 18 19
2016-01-06 20 21 22 23
2016-01-01 0
2016-01-02 4
2016-01-03 8
2016-01-04 12
2016-01-05 16
2016-01-06 20
Freq: D, Name: A, dtype: int32 2016-01-01 0
2016-01-02 4
2016-01-03 8
2016-01-04 12
2016-01-05 16
2016-01-06 20
Freq: D, Name: A, dtype: int32
A B C D
2016-01-01 0 1 2 3
2016-01-02 4 5 6 7
2016-01-03 8 9 10 11
A B C D
2016-01-02 4 5 6 7
2016-01-03 8 9 10 11
2016-01-04 12 13 14 15
A 4
B 5
C 6
D 7
Name: 2016-01-02 00:00:00, dtype: int32
A B
2016-01-01 0 1
2016-01-02 4 5
2016-01-03 8 9
2016-01-04 12 13
2016-01-05 16 17
2016-01-06 20 21
A 4
B 5
Name: 2016-01-02 00:00:00, dtype: int32
13
B C
2016-01-04 13 14
2016-01-05 17 18
B C
2016-01-02 5 6
2016-01-04 13 14
2016-01-06 21 22
A C
2016-01-01 0 2
2016-01-02 4 6
2016-01-03 8 10
A B C D
2016-01-04 12 13 14 15
2016-01-05 16 17 18 19
2016-01-06 20 21 22 23pandas设置值:
import numpy as np
import pandas as pd
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D'])
# 我们创建一个DataFrame,里面包含一个二维的numpy数组,行索引用刚才创建的dates,列索引定义为a,b,c,d
df.iloc[2, 2] = 1111
# 用行号和列号修改指定位置的元素的值
print(df)
df.loc['20130101', 'B'] = 2222
# 用标签修改指定位置的元素的值
print(df)
# df[df.A > 0] = 0
# # A>0的行的所有元素都改成0
# print(df)
df.A[df.A > 4] = 0
# A>4的项的A值全改成0
print(df)
df['F'] = np.nan
# 添加一列F
print(df)
df['G']=pd.Series([1,2,3,4,5,6],index=pd.date_range('20130101',periods=6))
# 添加一个不是空值的列,添加的值为1到6,index和原有的一样
print(df)运行结果如下:
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 1111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-01 0 2222 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 1111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-01 0 2222 2 3
2013-01-02 4 5 6 7
2013-01-03 0 9 1111 11
2013-01-04 0 13 14 15
2013-01-05 0 17 18 19
2013-01-06 0 21 22 23
A B C D F
2013-01-01 0 2222 2 3 NaN
2013-01-02 4 5 6 7 NaN
2013-01-03 0 9 1111 11 NaN
2013-01-04 0 13 14 15 NaN
2013-01-05 0 17 18 19 NaN
2013-01-06 0 21 22 23 NaN
A B C D F G
2013-01-01 0 2222 2 3 NaN 1
2013-01-02 4 5 6 7 NaN 2
2013-01-03 0 9 1111 11 NaN 3
2013-01-04 0 13 14 15 NaN 4
2013-01-05 0 17 18 19 NaN 5
2013-01-06 0 21 22 23 NaN 6pandas处理丢失的数据:
import numpy as np
import pandas as pd
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D'])
# 我们创建一个DataFrame,里面包含一个二维的numpy数组,行索引用刚才创建的dates,列索引定义为a,b,c,d
df.iloc[0, 1] = np.nan
df.iloc[1, 2] = np.nan
# 定义两个元素的值是NaN,假设这两个是丢失的数据
print(df)
print(df.dropna(axis=0, how='any'))
print(df.dropna(axis=1, how='any'))
# 如果某行某项里含有NaN值,则不打印这行所有元素,你也可以设axis=1,那就是按列来。
# how='any’则一行有至少一个为NaN值就丢弃,how='all'则一行全部为NaN值才丢弃。
print(df.fillna(value=0))
# 把NaN值的元素全部填充成0
print(df.isnull())
# 查询表格内所有值是否是NaN值,是则是True
print(np.any(df.isnull()) == True)
# 查询表格内是否至少有一个是NaN值,是则是True运行结果如下:
A B C D
2013-01-01 0 NaN 2.0 3
2013-01-02 4 5.0 NaN 7
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
A B C D
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
A D
2013-01-01 0 3
2013-01-02 4 7
2013-01-03 8 11
2013-01-04 12 15
2013-01-05 16 19
2013-01-06 20 23
A B C D
2013-01-01 0 0.0 2.0 3
2013-01-02 4 5.0 0.0 7
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
A B C D
2013-01-01 False True False False
2013-01-02 False False True False
2013-01-03 False False False False
2013-01-04 False False False False
2013-01-05 False False False False
2013-01-06 False False False False
Truepandas导入导出数据:
import pandas as pd
data = pd.read_csv('student.csv')
print(data)
# 可以看到行自动加了从0开始的索引
data.to_pickle('student.pickle')
# 可以看到数据保存生成了student.pickle文件运行结果如下:
Student ID name age gender
0 1100 Kelly 22 Female
1 1101 Clo 21 Female
2 1102 Tilly 22 Female
3 1103 Tony 24 Male
4 1104 David 20 Male
5 1105 Catty 22 Female
6 1106 M 3 Female
7 1107 N 43 Male
8 1108 A 13 Male
9 1109 S 12 Male
10 1110 David 33 Male
11 1111 Dw 3 Female
12 1112 Q 23 Male
13 1113 W 21 Female
Nonepandas合并concat:
DataFrame之间的合并。
import pandas as pd
import numpy as np
# concatenating
df1 = pd.DataFrame(np.ones((3, 4)) * 0, columns=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame(np.ones((3, 4)) * 1, columns=['a', 'b', 'c', 'd'])
df3 = pd.DataFrame(np.ones((3, 4)) * 2, columns=['a', 'b', 'c', 'd'])
print(df1)
print(df2)
print(df3)
# 我们进行上下合并,axis=0,横向合并axis=1
res = pd.concat([df1, df2, df3], axis=0)
print(res)
# 但是我们注意索引变成了012012012,怎么变成新的有序的行索引呢?
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
print(res)
# ignore_index=True忽略了原有的行索引,程序自动给合并后的结果自动安排新的默认的行索引
# 第二种方法:
df4 = pd.DataFrame(np.ones((3, 4)) * 0, columns=['a', 'b', 'c', 'd'], index=[1, 2, 3])
df5 = pd.DataFrame(np.ones((3, 4)) * 1, columns=['b', 'c', 'd', 'e'], index=[2, 3, 4])
print(df4)
print(df5)
# 新建了两个行索引和列索引都不一样的DataFrame。如何合并它们呢?
# res2 = pd.concat([df4, df5],join='outer')
# print(res2)
# # 如果还按第一种方法合并,则出现了许多NaN值(只有一个DataFrame有的索引的部分)
res2 = pd.concat([df4, df5], join='inner', ignore_index=True)
print(res2)
# join='inner'则合并时只考虑两个DataFrame中都有的索引的部分,ignore_index=True处理行索引
df6 = pd.DataFrame(np.ones((3, 4)) * 0, columns=['a', 'b', 'c', 'd'], index=[1, 2, 3])
df7 = pd.DataFrame(np.ones((3, 4)) * 1, columns=['b', 'c', 'd', 'e'], index=[2, 3, 4])
res3 = pd.concat([df6, df7], axis=1, join_axes=[df6.index])
print(res3)
# axis=1是列合并, join_axes=[df6.index]即按照df6的index进行合并,df6没有的index部分填充NaN
# 不添加join_axes=[df6.index],则两者中只有其中一方拥有的索引的部分都会填充NaN
df8 = pd.DataFrame(np.ones((3, 4)) * 0, columns=['a', 'b', 'c', 'd'])
df9 = pd.DataFrame(np.ones((3, 4)) * 1, columns=['a', 'b', 'c', 'd'])
df10 = pd.DataFrame(np.ones((3, 4)) * 1, columns=['b', 'c', 'd', 'e'], index=[2, 3, 4])
# DataFrame中整个数据是一行一行为单位的列表。column是它的属性。append就是在下面增加新行数据。
res4 = df8.append(df9, ignore_index=True)
# 把df9的行排在df8下面,行索引重新排
res5 = df8.append([df9, df10], ignore_index=True, sort=False)
# df9,df10的行排在df8后面,行索引重新排,不排序
s1 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
res6 = df8.append(s1, ignore_index=True)
# df8后面添加一个新行s1
print(res4)
print(res5)
print(res6)运行结果如下:
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
a b c d
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
a b c d
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
a b c d b c d e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
a b c d e
0 0.0 0.0 0.0 0.0 NaN
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 1.0 1.0 1.0 1.0 NaN
4 1.0 1.0 1.0 1.0 NaN
5 1.0 1.0 1.0 1.0 NaN
6 NaN 1.0 1.0 1.0 1.0
7 NaN 1.0 1.0 1.0 1.0
8 NaN 1.0 1.0 1.0 1.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0pandas合并merge:
import pandas as pd
import numpy as np
left = pd.DataFrame(dict(key=['K0', 'K1', 'K2', 'K3'], A=['A0', 'A1', 'A2', 'A3'], B=['B0', 'B1', 'B2', 'B3']))
right = pd.DataFrame(dict(key=['K0', 'K1', 'K2', 'K3'], C=['C0', 'C1', 'C2', 'C3'], D=['D0', 'D1', 'D2', 'D3']))
print(left)
print(right)
res = pd.merge(left, right, on='key')
# on='key'基于'key'标签合并
print(res)
# 如果有两个key呢?
left1 = pd.DataFrame(dict(key1=['K0', 'K0', 'K1', 'K2'], key2=['K0', 'K1', 'K0', 'K1'], A=['A0', 'A1', 'A2', 'A3'],
B=['B0', 'B1', 'B2', 'B3']))
right1 = pd.DataFrame(dict(key1=['K0', 'K1', 'K1', 'K2'], key2=['K0', 'K0', 'K0', 'K0'], C=['C0', 'C1', 'C2', 'C3'],
D=['D0', 'D1', 'D2', 'D3']))
print(left1)
print(right1)
res1 = pd.merge(left1, right1, on=['key1', 'key2'], how='inner')
# 注意merge的默认参数是inner,即只把这两标签中数据相同的行留下来
print(res1)
# how有四种方式:left、right、outer、inner
res2 = pd.merge(left1, right1, on=['key1', 'key2'], how='right')
print(res2)
# 即left1和right1中以后面的表的key1和key2为基准合并
# 类似数据库的左连接、右连接、内连接、外连接
# merged by index
left2 = pd.DataFrame(dict(A=['A0', 'A1', 'A2'],
B=['B0', 'B1', 'B2']),
index=['K0', 'K1', 'K2'])
right2 = pd.DataFrame(dict(C=['C0', 'C1', 'C2'],
D=['D0', 'D1', 'D2'],
index=['k0', 'k2', 'k3']))
print(left2)
print(right2)
res3 = pd.merge(left2, right2, left_index=True, right_index=True, how='outer')
res4 = pd.merge(left2, right2, left_index=True, right_index=True, how='inner')
# 现在合并时同时考虑left和right中的index
print(res3)
print(res4)
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
res5 = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res5)
# inner时只考虑相同的key要注意一点的是merge里的参数how的四个选择:left、right、outer、inner与数据库中的左连接、右连接、外连接、内连接很相似。
运行结果如下:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 B3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
3 K3 C3 D3
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
C D index
0 C0 D0 k0
1 C1 D1 k2
2 C2 D2 k3
A B C D index
K0 A0 B0 NaN NaN NaN
K1 A1 B1 NaN NaN NaN
K2 A2 B2 NaN NaN NaN
0 NaN NaN C0 D0 k0
1 NaN NaN C1 D1 k2
2 NaN NaN C2 D2 k3
Empty DataFrame
Columns: [A, B, C, D, index]
Index: []
k age_boy age_girl
0 K0 1 4
1 K0 1 5pandas plot图表:
我们为一个列表作图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 数据可视化必须的模块
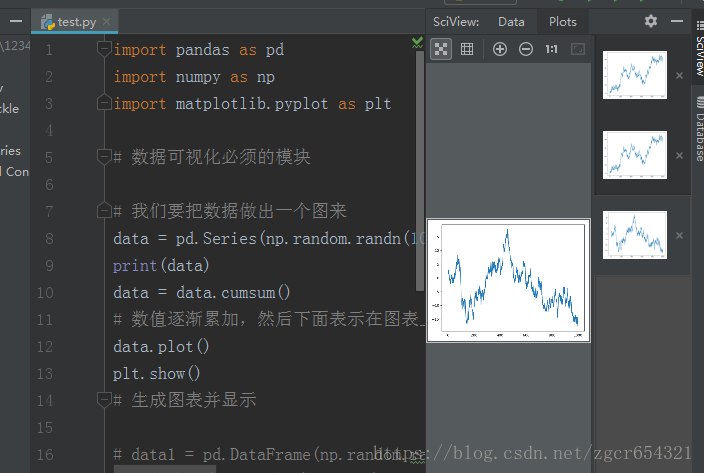
# 我们要把数据做出一个图来
data = pd.Series(np.random.randn(1000), index=np.arange(1000))
print(data)
data = data.cumsum()
# 数值逐渐累加,然后下面表示在图表上
data.plot()
plt.show()
# 生成图表并显示运行截图如下:
我们再创建一个矩阵,为矩阵作图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 数据可视化必须的模块
data1 = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list("ABCD"))
# 创建一个1000X4矩阵,设置索引,定义了4个列属性
data1 = data1.cumsum()
print(data1.head())
# 打印矩阵前5个数据(5是默认个数)
data1.plot()
plt.show()
# 作图并显示图表运行截图如下:
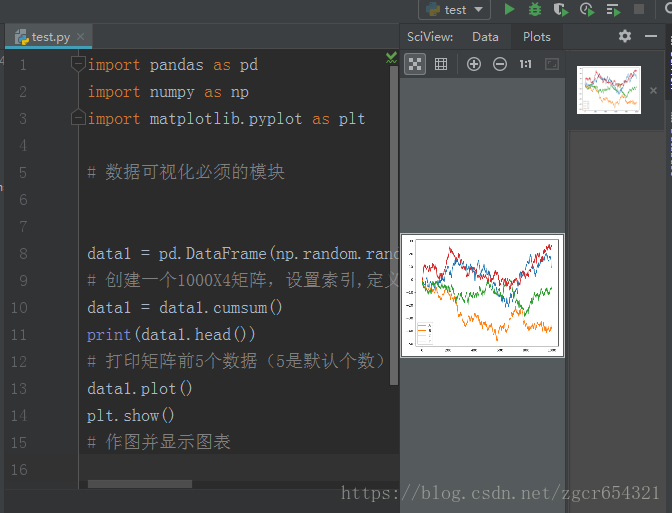
可以看到图上有4条不同颜色的曲线。(因为行索引只有一种。列属性有4种)
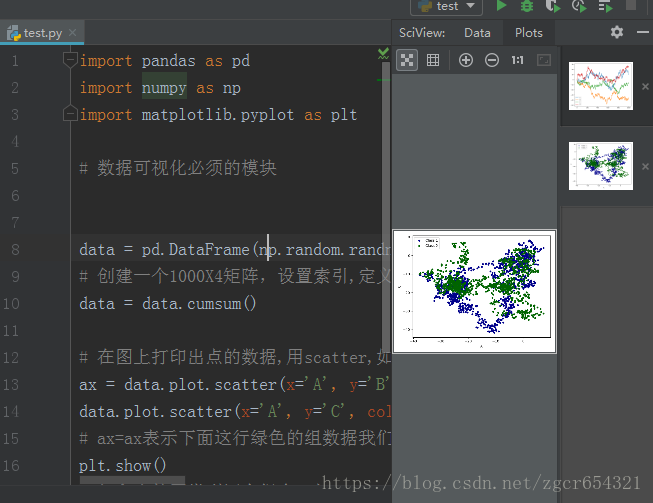
下面是在图上打印出散点的数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 数据可视化必须的模块
data = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list("ABCD"))
# 创建一个1000X4矩阵,设置索引,定义了4个列属性
data = data.cumsum()
# 在图上打印出点的数据,用scatter,如指定A和B属性分别为x和y
ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label='Class 1')
data.plot.scatter(x='A', y='C', color='DarkGreen', label='Class 2', ax=ax)
# ax=ax表示下面这行绿色的组数据我们也想附在ax这张图里
plt.show()
# 打印出的图类型还有很多,如bar、hist、box、kde、area、scatter、hexbin、pie,可以自己试试运行截图如下: