献给和我一样苦苦挣扎的数学渣们,以下是我在查阅网上资料时总结的,懒得一一标明出处了
基础摘要: 尽量详细推导
一个在HMM算法里经常出现的重要结论: 条件独立
引用wiki的解释就是一旦知道了Z,从Y的值便不能得出任何关于X的信息。例如,相同的数量Z的两个测量X和Y不是独立的,但它们是给定Z条件独立(除非两个测量的误差是有关联的)。

以及

明白了上面2条公式,你才可以看懂HMM以及贝叶斯滤波的公式
马尔科夫链:根据其无后效性有 P(x_n|x_{n-1},...,x_1)=P(x_n|x_{n-1})
P(x_n,x_{n-1},...,x_1)=P(x_1)P(x_2|x_1)P(x_3|x_2,x_1)...P(x_n|x_{n-1}...x_1)
=P(x_1)P(x_2|x_1)P(x_3|x_2).....P(x_n|x_{n-1})
独立输出假设:第i时刻的接收信号oi只由发送信号si决定,即
P(o_1,o_2,o_3...o_n|s_1,s_2,s_3...s_n)=P(o_1|s_1)P(o_2|s_2)...P(o_n|s_n)
开篇:关于HMM的说明在网上已经有很大一坨,在这里就不在叙述了。用一句话概括就是你不会hmm的话很多关于AI或者说machine learning的算法无法往下看。在这里我尽量做最简洁的说明,想看详细的请自行搜索关键词("hmm学习最佳范例“)
马尔科夫过程:
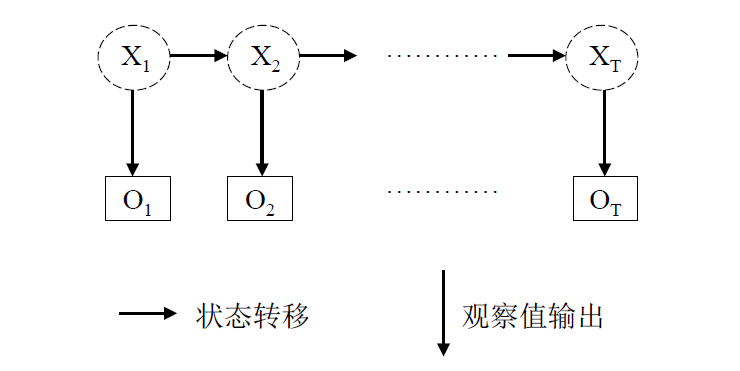
现在我们已知观察值(o1,o2....on),而(x1,x2...xn)是隐藏状态,比如说我们看到一个人在哭,那他可能此刻很伤心,或者说只是路过被楼上花盆砸到头很痛所以哭了,在这里“哭”是观察值,“伤心”和“痛”是隐藏状态,我们不能直接得到的。
由无后效性和独立输出假设(见上)
可以推出P(o_1,o_2....o_n,s_1,s_2....s_n)=P(o_1,o_2...,o_n|s_1,s_2...s_n)P(s_1,s_2...s_n)
=P(o_1|s_1)P(o_2|s_2)...P(o_n|s_n)P(s_1)P(s_2|s_1)...P(s_n|s_{n-1})
整理一下就可以得到网上常见的公式
HMM有三个典型(canonical)问题:
- 已知模型参数,计算某一特定输出序列的概率.通常使用forward算法解决.
- 已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列.通常使用Viterbi算法解决.
- 已知输出序列,寻找最可能的状态转移以及输出概率.通常使用Baum-Welch算法以及Reversed Viterbi算法解决.