我们现在来用之前提到的Q-Learning算法,实现一个有趣的东西
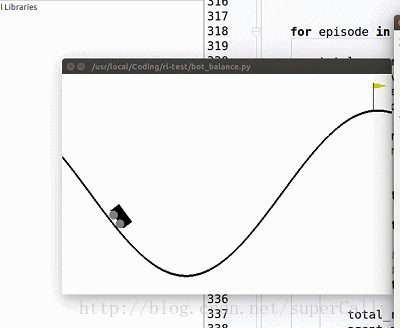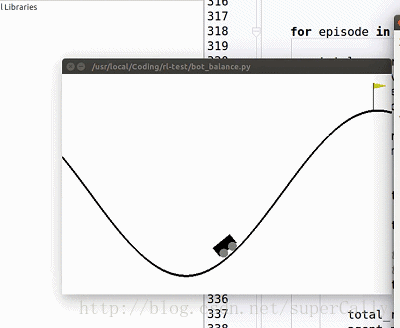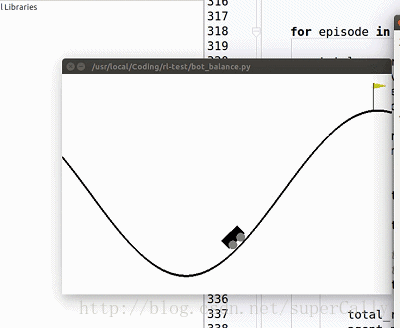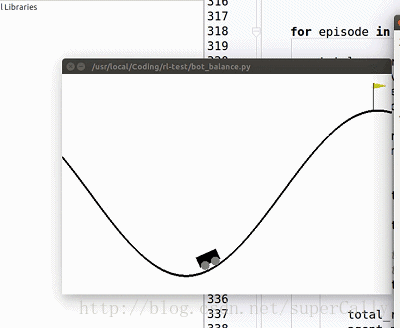
1. 算法效果
我们想要实现的,就是一个这样的小车。小车有两个动作,在任何一个时刻可以向左运动,也可以向右运动,我们的目标是上小车走上山顶。一开始小车只能随机地左右运动,在训练了一段时间之后就可以很好地完成我们设定的目标了
2. Deep Q Learning 算法简单介绍
就像我们在前一章里面简单介绍的,我们使用的算法就是最简单的Deep Q Learning算法,算法的流程如下图所示
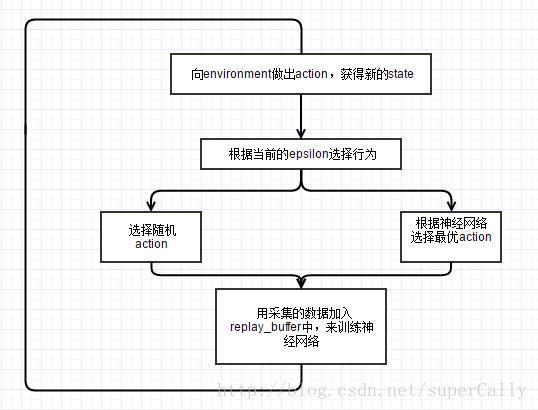
我们可以看到,这个算法里面主要有这样几个要素
1. replay_buffer
我们在不断地在系统中训练的过程中,会产生大量的训练数据。虽然这些数据并不是应对当时环境最优的策略,但是是通过与环境交互得到的经验,这对于我们训练系统是有非常大的帮助的。所以我们设置一个replay_buffer,获得新的交互数据,抛弃旧的数据, 并且每次从这个replay_buffer中随机取一个batch,来训练我们的系统
replay_buffer中的每一条记录包含这几项:
- state,表示当时系统所面临的状态
- action,表示我们的agent面临系统的状态时所做的行为
- reward,表示agent做出了选择的行为之后从环境中获得的收益
- next_state,表示agent做出了选择的行为,系统转移到的另外一个状态
- done,表示这个epsiode有没有结束
我们就用这个状态集来训练我的神经网络
这种平等地对待所有采集数据的策略似乎不是很有效,有的数据明显更有用(比如说那些得分的数据),所以我们可以在这一点上对他进行优化,就是prioritized_replay_buffer,后面我们会专门写文章进行介绍
2. 神经网络
在这里我们为什么会用神经网络呢?
因为对于某一个时刻系统的状态,我们需要估算在这个状态下,我们采取状态集S当中的每一个动作,大概会产生多大的收益
然后我们就可以根据我们既定的策略,在比较了收益之后,选一个动作
神经网络的输入,是系统的一个状态,state
神经网络的输出,是状态集当中的每一个动作,在当前状态下,会产生的价值
输入是系统给定的,输出是我们估算出来的,我们用估算的这个输出,来替代之前的输出,一步步地进行优化
有了这些数据,我们就可以对神经网络来做优化了
但是我们拿到了每个动作的价值之后,该采取怎样的策略呢?在基本的Q-Learning算法中,我们采取最最简单的epsilon-greedy策略
3. epsilon_greedy
这个策略虽然简单,但是十分的有效,甚至比很多复杂的策略效果还要好
具体的介绍可以看这篇文章https://zhuanlan.zhihu.com/p/21388070,我们在这里简单介绍一下
我们设置一个阈值,epsilon-boundary,比如说初始值是0.8,意思就是我们现在选择action的时候,80%的可能性是随机地从动作集中选择一个动作,20%的可能性是通过神经网络计算每个动作的收益,然后选最大的那一个
但是随着学习过程推进,我们的epsilon-boundary要越来越低,随机选择的次数要越来越少,到最后几乎不做随机的选择
3. 重点代码解析
Q_value_batch = self.Q_value.eval( feed_dict = { self.input_layer : next_state_batch } )
for i in xrange( BATCH_SIZE ):
if done_batch[i]:
y_batch.append( reward_batch[ i ] )
else:
y_batch.append( reward_batch[ i ] + GAMMA * np.max(Q_value_batch[ i ]) )
之前我们讲到,神经网络的作用就是,估算当前状态下采取每个action的价值。在这里,神经网络的输入是next_state,输出的是next_state的各个动作的值,各个动作的max我们就认为是next_state可以达到的最大值
所以在这里我们实现的是之前说到的正是Q-Learning算法
V^{\pi}(s_0)=E[R(s_0)+\gamma V^{\pi}(s_1)]如果这个状态是当前episdoe的最后一个状态,那么价值就只有即时的reward,如果还有下面的状态,reward就等于即时的reward,加下一个状态的价值
self.optimizer.run( feed_dict = {
self.input_layer: state_batch,
self.action_input:action_batch,
self.y_input : y_batch
} )
然后我们就用计算出来的reward值,来对神经网络做训练
self.Q_value = tf.matmul( hidder_layer3, W4 ) + b4
self.action_input = tf.placeholder("float", [None, self.action_dim])
self.y_input = tf.placeholder("float", [None])
Q_action = tf.reduce_sum( tf.mul( self.Q_value, self.action_input ), reduction_indices = 1 )
self.cost = tf.reduce_mean( tf.square( self.y_input - Q_action ) )
self.optimizer = tf.train.RMSPropOptimizer(0.00025,0.99,0.0,1e-6).minimize( self.cost )这一段涉及到了tensorflow最基本的操作,不熟悉的同学可以先看这篇
这段代码就是实现的这个想法
Q_value就是神经网络的输出,一个[1*K]的向量,K代表的是动作的数量
action_input就是实际上采取的那个动作,但是是one_hot_action类型的,就是整个向量都是0,除了采取操作的那个index是1,这样方便操作,只要做一个内积就可以了
然后我们就用之前计算出的估计值来当作真实值,对神经网络来做优化
可以自己指定优化器和相关的参数
if self.epsilon >= FINAL_EPSILON:
self.epsilon -= ( INITIAL_EPSILON - FINAL_EPSILON ) / 10000
if random.random() < self.epsilon:
return random.randint(0, self.action_dim - 1)
else:
return self.get_greedy_action( state )这段就是之前提到的epsilon-greedy算法
for episode in xrange(EPISODE):
state = env.reset()
total_reward = 0
debug_reward = 0
for step in xrange(STEP):
env.render()
action = agent.get_action( state )
next_state, reward, done, _ = env.step( action )
total_reward += reward
agent.percieve( state, action, reward, next_state, done )
state = next_state
if done:
break这段是主程序的代码,在每一个episode里面,我们跟环境进行交互,并且收集交互产生的数据,对神经网络进行训练
这里有几个api可能需要解释一下
next_state, reward, done, ob = env.step( action )在这里我们给环境一个action,环境给我们返回这个action导致的下一个state,这个action导致的reward,episdoe是否结束,最后一个返回的值是一个observation,就是能从环境中直接观测到的量,这个量虽然是环境返回给我们的,但是作为agent,因为不是上帝视角,所以是不能用的
4. 完整代码
import tensorflow as tf
import numpy as np
import gym
import random
from collections import deque
EPISDOE = 10000
STEP = 10000
ENV_NAME = 'MountainCar-v0'
BATCH_SIZE = 32
INIT_EPSILON = 1.0
FINAL_EPSILON = 0.1
REPLAY_SIZE = 50000
TRAIN_START_SIZE = 200
GAMMA = 0.9
def get_weights(shape):
weights = tf.truncated_normal( shape = shape, stddev= 0.01 )
return tf.Variable(weights)
def get_bias(shape):
bias = tf.constant( 0.01, shape = shape )
return tf.Variable(bias)
class DQN():
def __init__(self,env):
self.epsilon_step = ( INIT_EPSILON - FINAL_EPSILON ) / 10000
self.action_dim = env.action_space.n
print( env.observation_space )
self.state_dim = env.observation_space.shape[0]
self.neuron_num = 100
self.replay_buffer = deque()
self.epsilon = INIT_EPSILON
self.sess = tf.InteractiveSession()
self.init_network()
self.sess.run( tf.initialize_all_variables() )
def init_network(self):
self.input_layer = tf.placeholder( tf.float32, [ None, self.state_dim ] )
self.action_input = tf.placeholder( tf.float32, [None, self.action_dim] )
self.y_input = tf.placeholder( tf.float32, [None] )
w1 = get_weights( [self.state_dim, self.neuron_num] )
b1 = get_bias([self.neuron_num])
hidden_layer = tf.nn.relu( tf.matmul( self.input_layer, w1 ) + b1 )
w2 = get_weights( [ self.neuron_num, self.action_dim ] )
b2 = get_bias( [ self.action_dim ] )
self.Q_value = tf.matmul( hidden_layer, w2 ) + b2
value = tf.reduce_sum( tf.mul( self.Q_value, self.action_input ), reduction_indices = 1 )
self.cost = tf.reduce_mean( tf.square( value - self.y_input ) )
self.optimizer = tf.train.RMSPropOptimizer(0.00025,0.99,0.0,1e-6).minimize(self.cost)
return
def percieve(self, state, action, reward, next_state, done):
one_hot_action = np.zeros( [ self.action_dim ] )
one_hot_action[ action ] = 1
self.replay_buffer.append( [ state, one_hot_action, reward, next_state, done ] )
if len( self.replay_buffer ) > REPLAY_SIZE:
self.replay_buffer.popleft()
if len( self.replay_buffer ) > TRAIN_START_SIZE:
self.train()
def train(self):
mini_batch = random.sample( self.replay_buffer, BATCH_SIZE )
state_batch = [data[0] for data in mini_batch]
action_batch = [data[1] for data in mini_batch]
reward_batch = [ data[2] for data in mini_batch ]
next_state_batch = [ data[3] for data in mini_batch ]
done_batch = [ data[4] for data in mini_batch ]
y_batch = []
next_state_reward = self.Q_value.eval( feed_dict = { self.input_layer : next_state_batch } )
for i in range( BATCH_SIZE ):
if done_batch[ i ]:
y_batch.append( reward_batch[ i ] )
else:
y_batch.append( reward_batch[ i ] + GAMMA * np.max( next_state_reward[i] ) )
self.optimizer.run(
feed_dict = {
self.input_layer:state_batch,
self.action_input:action_batch,
self.y_input:y_batch
}
)
return
def get_greedy_action(self, state):
value = self.Q_value.eval( feed_dict = { self.input_layer : [state] } )[ 0 ]
return np.argmax( value )
def get_action(self, state):
if self.epsilon > FINAL_EPSILON:
self.epsilon -= self.epsilon_step
if random.random() < self.epsilon:
return random.randint( 0, self.action_dim - 1 )
else:
return self.get_greedy_action(state)
def main():
env = gym.make(ENV_NAME)
agent = DQN( env )
for episode in range(EPISDOE):
total_reward = 0
state = env.reset()
for step in range(STEP):
env.render()
action = agent.get_action( state )
next_state, reward, done, _ = env.step( action )
total_reward += reward
agent.percieve( state, action, reward, next_state, done )
if done:
break
state = next_state
print 'total reward this episode is: ', total_reward
if __name__ == "__main__":
main()