本文是Deep Learning 之 最优化方法系列文章的Adam方法。主要参考Deep Learning 一书。
整个优化系列文章列表:
Deep Learning 最优化方法之Momentum(动量)
先上结论:
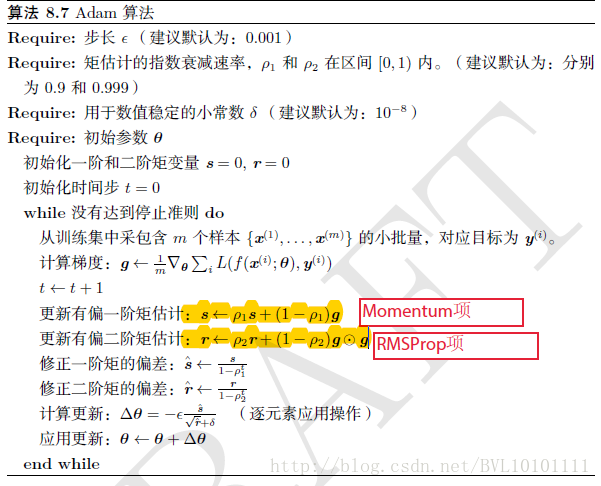
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001
再看算法:其实就是Momentum+RMSProp的结合,然后再修正其偏差。
本文是Deep Learning 之 最优化方法系列文章的Adam方法。主要参考Deep Learning 一书。
整个优化系列文章列表:
Deep Learning 最优化方法之Momentum(动量)
先上结论:
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001
再看算法:其实就是Momentum+RMSProp的结合,然后再修正其偏差。