caffe生成lmdb的需求后边再说,先讲该程序要实现的:给定一个路径,读取该路径下的所有文件夹及其中的文件,将这些文件复制到另一目录下并重命名,再生成一个文件列表,列表中包括更改后的文件名和对应的类别。
命名规则是将所有图片从1开始编号,并且编号右对齐,位数不够前边用0补齐。类别的生成规则是同一个子文件夹下的文件为一个类别,从0开始编号。
MATLAB实现:
clear;
clc;
fileFolder=fullfile('D:\dataset\CASIA-maxpy-clean');
dirOutput=dir(fullfile(fileFolder, '*'));
f_train = fopen('casiaList_train.txt', 'wt');
f_test = fopen('casiaList_test.txt', 'wt');
num = 0;
for i = 3:length(dirOutput)
num = num + 1;
face = dir(fullfile(fileFolder, dirOutput(i).name));
personName = dirOutput(i).name;
temp = floor((length(face)-2)*0.1);
for j = 3:length(face)-temp
movefile(fullfile(fileFolder, dirOutput(i).name, face(j).name), ['train-', sprintf('%07d', num), '.jpg']);
fprintf(f_train , '%s %d\n', ['train-', sprintf('%07d', num), '.jpg'], i-3);
end
if temp >= 1
for j = (length(face)-temp+1) : length(face)
movefile(fullfile(fileFolder, dirOutput(i).name, face(j).name), ['test-', sprintf('%07d', num), '.jpg']);
fprintf(f_test, '%s %d\n', ['test-', sprintf('%07d', num), '.jpg'], i-3);
end
end
end
fclose(f_train );
fclose(f_test);解释:
数字转换成字符串,右对齐,前边不够用零补。
数字x,转换成字符串,要求必须是7位的,比如3要存成0000003,怎么办呢? num2str(‘%07d’, x)
格式化输出:%07d ,%07.4f
%f - 浮点数,%d – 整数
0 - 前面补零
7 - 共7位
.4 - 小数点后4位
num2str 将数字转换为数字字符串
str2num 将数字字符串转换为数字
mat2str 将数组转换成字符串通过dir读取出的文件组织结构中,前两个分别是当前文件夹./和上层文件夹../,所以读取该目录下的所有文件夹从第3个开始。
fullfile()作用:将多个字符串合成一个路径。
复制文件和移动文件
movefile('1.txt', '11.txt'); %就地移动,相当于重命名 copyfile('2.txt', '22.txt'); %就地复制
movefile('11.txt', '1'); %剪切文件到文件夹1
copyfile('22.txt', '2'); %复制文件到文件夹1
kk = 3;
movefile(‘D:\xxl\1.txt’, ['test-',sprintf('%03d',kk),'.png']) %把指定文件夹中的指定文件复制到当前目录下,并重命名为test-003.pngcaffe生成lmdb时需要一个文件列表,分别给出训练集(train.txt)和测试集(test.txt)的数据及其所属类别。注意:在构造list文件时,这里的空格就是一个空格,不要写成tab(\t),否则会报错说找不到文件。
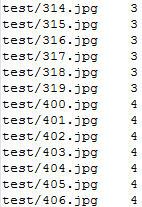
例如

注:这里的类别必须用数字进行编号。如果想要知道每一类分别代表什么。可以另写一个文件给出编号和含义的对应关系,在分类完成以后便于人的理解。对于机器来说只用编号就够了。
并且我在使用caffe生成lmdb的过程中发现,如果在文件列表中给出文件路径,例如
在生成lmdb过程中总是会报错,无法打开或找到文件
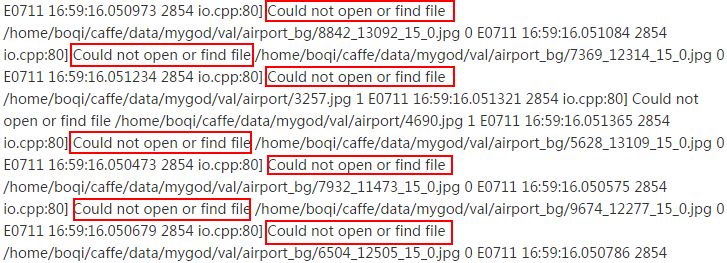
可是我对照文件路径和报错中提到的路径,明明是一样的。。。
解决方法:
将图片都放在一个文件夹下,然后文件列表中只有文件名,没有子文件夹名,即图片不要放在子文件夹下。
【至今没有搞清为什么,我猜想有可能caffe默认列表中给出的那一长串都是文件名,而我们的给出的路径,所以出现不对应。有知道原因的朋友忘告知,谢谢!】
我在构造训练集和测试集的时候,本来打算每个类别取一张图作为测试集,但是觉得这样不太合理,因为不用类别的样本数目差别还是挺大的。因此,我按比例取了整体图片的10%作为测试集,其他作为训练集。具体实现为,进入一个文件夹后,先看这类图片的样本数的10%是不是大于1,若是,留出10%的部分作为测试集,否则将所有的文件作为训练集。