
Apache Spark:是一种采用Scala语言编写的用于大规模数据处理的快速通用引擎, 由UC Berkeley AMP Lab开发的类似MapReduce集群计算框架设计,用于低延迟迭代作业和交互使用,是一种内存计算框架。
Spark发展历程
•Spark诞生于2009年,那时候它是,加州大学伯克利分校RAD实验室的一个研究项目,后来到了AMP实验室。
•Spark最初是基于Hadoop Mapreduce的,后来发现Mapreduce在迭代式计算和交互式上是低效的。因此Spark进行了改进,引 入了内存存储和高容错机制。
•2010年3月份Spark开源。
•2011年,AMP实验室开始在Spark上面开发高级组件,像Shark(Hive on Spark),Spark Streaming。
•2013年转移到了Apache下,现在已经是顶级项目了。
•2014年5月份Spark1.0发布。
Spark特点
先进架构
Spark采用Scala语言编写,代码十分简洁高效。
基于DAG图的执行引擎,减少多次计算之间中间结果写到HDFS的开销。
建立在统一抽象的RDD(弹性分布式数据集)之上,使得它可以以基本一致的方式 应对不同的大数据处理场景。
高效性
提供Cache机制来支持需要反复迭代的计算或者多次数据共享,减少数据读取的IO开销。
与Hadoop的MapReduce相比,Spark基于内存的运算比MR要快100倍;而基于硬盘的运算也要快10倍!
易用性
Spark提供广泛的数据集操作类型(20+),不像Hadoop只提供了Map和Reduce两种操作。
Spark支持Java,Python和Scala API,支持交互式的Python和Scala的shell。
提供整体解决方案
以其RDD模型的强大表现能力,逐渐形成了一套自己的生态圈,提供了full-stack的解决方案。
主要包括Spark内存中批处理,Spark SQL交互式查询,Spark Streaming流式计算, GraphX和MLlib提供的常用图计算和机 器学习算法。
与Hadoop无缝衔接
Spark可以使用YARN作为它的集群管理器读取HDFS,HBase等一切Hadoop的数据。
Spark相关概念
Application:Spark中的Application和Hadoop MapReduce中的概念是相似的,指的是用户编写的Spark应用程序,包含了一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码。Spark应用程序,由一个或多个作业JOB组成。
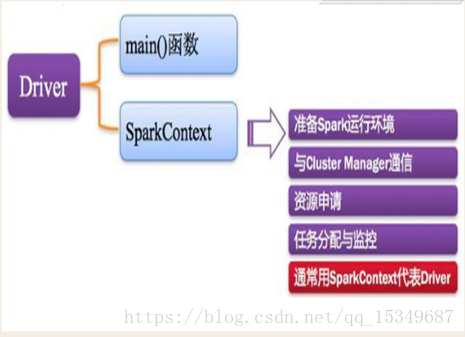
Driver Program:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创=创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Driver。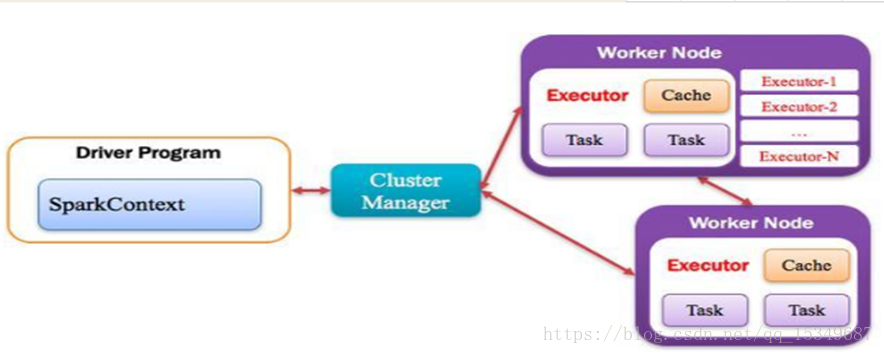
Executor:Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。
Cluster Mananger:指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配。
Worker:集群中任何可以运行Application代码的节点。
Job:由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个Job包含多个RDD及作用于相应RDD上的各种Operations。Stage:一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段。Task:被送到某个Executor上的工作任务,单个分区数据集上的最小处理流程单元。
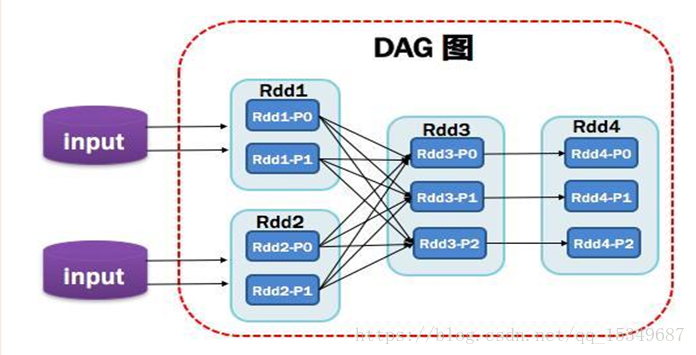
DAG:有向无环图。简单的来说,就是一个由顶点和有方向性的边构成的图,从任意一个顶点出发,没有任何一条路径会将其带回到出发的顶点。其反应了RDD之间的依赖关系。
Spark的4大组件
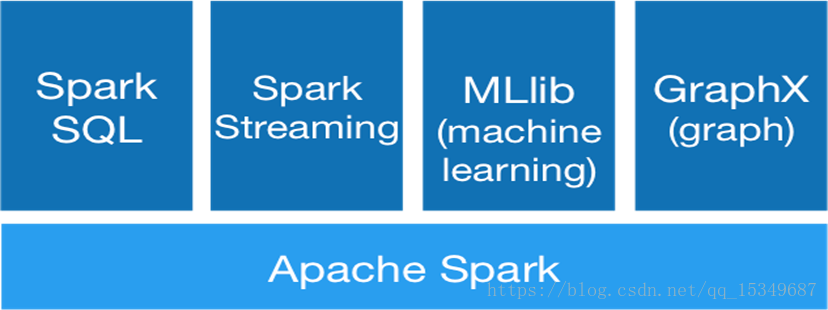
SparkSQL
一种结构化数据查询。
Spark程序可以与SQL查询无缝衔接。
提供的最核心的编程抽象就是DataFrame,它可以根据很多数据源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD。
MLlib
Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。MLlib 目前支持四种常见的机器学习问题:二元分类,回归,聚类以及协同过滤,同时也包括一个底层的梯度下降优化基础算法。
GraphX
一个分布式图处理框架,基于Spark平台提供对图计算和图挖掘简洁易用的而丰富多彩的接口,极大的方便了大家对分布式图处理的需求。灵活性,图表和集合可以无缝衔接;高性能,比其他图处理软件处理快;算法种类多,提供更多的图算法。
Spark Streaming
建立在Spark上的实时计算框架,通过它提供丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互式查询应用,并且支持高吞吐量及容错机制。
基本原理:将流数据分成小的时间片段(几秒),以类似批处理方式来处理这部分小数据。
处理流程:Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块;Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据,每个块都会生成一个Spark Job,处理后的最终结果也返回多块。
Sark相关概念