版权声明:博主GitHub地址https://github.com/suyeq欢迎大家前来交流学习 https://blog.csdn.net/hackersuye/article/details/82823806
在Redis字典中,得到键的hash值显得尤为重要,因为这个不仅关乎到是否字典能做到负载均衡,以及在性能上优势是否突出,一个良好的hash算法在此时就能发挥出巨大的作用。而一个良好的hash算法往往倾向于把不同的实例分配在不同的散列值上。在Redis中,实现键的哈希值有两种算法实现,一种是djb2算法,另一种就是MurmurHash2算法。
djb2算法
djb2是Daniel J. Bernstein多年前在comp.lang.c上发表的哈希算法,这个算法已被广泛应用,是目前最好的字符串哈希算法之一。因为它不仅计算速度很快,而且分布比较均匀。
而在Redis中的实现如下:
static uint32_t dict_hash_function_seed = 5381;
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c buf转换成小写*/
return hash;
}
MurmurHash2算法
MurmurHash2算法是由Austin Appleby于2008年发明,这种算法的优点在于,即使给出的实例有着规律,但是算法依旧可以给出一个不错的随机分布,而且计算速度也很快。这也是Redis中采用计算键的哈希值的算法。
给出算法实现:
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
而在Redis中采用的散列函数是对键的哈希值与字典的大小的掩码取与操作。这种做法使得取与后的值小于等于字典的大小的掩码,防止了内存溢出。
如下代码所示:
#include <iostream>
using std::string;
unsigned int djb2(string s)
{
unsigned int hash=(unsigned)5381;
for (int i = 0; i <s.length() ; ++i) {
hash=((hash<<5)+hash)+tolower(s[i]);
}
return hash;
}
int main()
{
unsigned int sizemask=9;
string s[10];
for (int i = 0; i <10 ; ++i) {
std::cin>>s[i];
}
for (int j = 0; j <10 ; ++j) {
std::cout<<(djb2(s[j]) & sizemask)<<std::endl;
}
return 0;
}
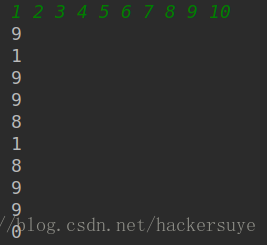
结果为:
可见结果确实如此。
因对算法理解有限,博主并不知道其中的算法的原理具体如何,如有大神浏览,请告知一声。下面有个在Stack Overflow上对djb2算法的解惑,解释了为什么选择5381。
这里有个答案