人工神经网络
人工神经网络主要应用于数据建模、预测、模式识别和函数优化等方向
1. 基本理论
ANN(artificial neutral network,人工神经网络) 是由大量简单的基本元件——神经元相互连接,通过模拟人的大脑神经处理信息的方式,进行信息并行处理和非线性转换的复杂网络系统。
1. BP 网络基本数学原理
BP(back propagation,前向反馈) 网络是一种多层前馈神经网络
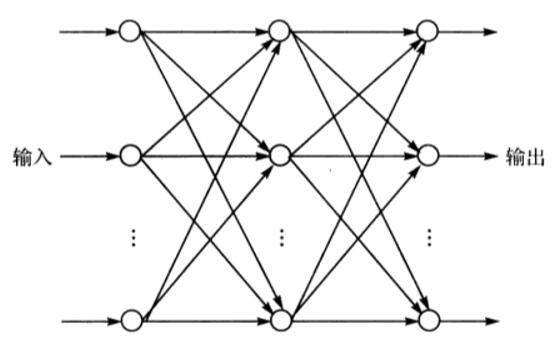
如图,BP 网络是一种具有三层或三层以上神经元的神经网络,包括输入层、中间层(隐含层)和输出层。上下层之间实现全连接,而同一层的神经元之间无连接,输入神经元与隐含层神经元之间是网络的权值,其意义是两个神经元之间的连接强度。隐含层或输出层任一神经元将前一层所有神经元传来的信息进行整合,通常还会在整合过的信息中添加一个阈值,这主要是模拟生物学中神经元必须达到一定的阈值才会触发的原理,然后将整合过的信息作为该层神经元的输入。当一对学习样本提供给输入神经元后,神经元的激活值(该层神经元输出值)从输入层经过各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应,然后按照减少网络输出与实际输出样本之间误差的方向,从输出层反向经过各隐含层回到输入层,从而逐步修复各连接权值,这样的算法称为误差反向传播算法,即 BP 算法。随着这种误差逆向传播修正的反复进行,网络对输入模式响应的正确率也不断上升
2. 工具箱
1. BP 网络创建函数
可能用得上的变量及其含义:
| 变量 | 含义 |
|---|---|
| PR | 由每组输入元素的最大值和最小值组成的 R X 2 的矩阵 |
| Si | 第 层的长度,共计 层 |
| TFi | 第 层的激励函数,默认为 “tansig” |
| BTF | 网络的训练函数,默认为 “trainlm” |
| BLF | 权值和阈值的学习算法,默认为 “learngdm” |
| PF | 网络的性能函数,默认为 “mse” |
1. 函数 newcf
该函数用于创建一个 BP 网络
net = newff
net = newff(PR,[S1 S2...SN],{TF1 TF2...TFN},BTF,BLF,PF)其中,net = newff 用于在对话框中创建一个 BP 网络
2. 函数 newfftd
该函数用于创建一个存在输入延迟的前向网络
net = nefftd
net = nefftd(PR,[S1 S2...SN],{TF1 TF2...TFN},BTF,BLF,PF)其中,net = newfftd 用于在对话框中创建一个 BP 网络
2. 神经元激励函数
激励函数必须是连续可微的
1. 函数 logsig
logsig 为 S 型的对数函数
A = logsig(N)
info = logsig(code)其中, 为 个 维的输入列向量;A 为函数返回值,位于区间 (0,1) 之间,info 根据 code 值不同返回不同的信息,具体如表
| code 的取值 | 返回的信息 |
|---|---|
| ‘deriv’ | 微分函数的名称 |
| ‘name’ | 函数全称 |
| ‘output’ | 输出值域 |
| ‘active’ | 有效的输入区间 |
该函数使用的算法为:
2. 函数 dlogsig
dlogsig 是 logsig 的导函数
dA_dN = dlogsig(N,A)其中, 为 维网络输入,A 为 维网络输出,dA_dN 为函数的返回值,输出对输入的导数
该函数使用的算法为:
3. 函数 tansig
tansig 为双曲正切 S 型激励函数
A = tansig(N)
info = tansig(code)其中,N 为 个 维的输入列向量,A 为函数返回值,位于区间 (-1,1) 之间,info 根据 code 值不同返回不同的信息,同上 logsig 函数
该函数使用的算法为:
4. 函数 dtansig
dtansig 是函数 tansig 的导函数
dA_dN = dtansig(N,A)其中, 为 维网络输入,A 为 维网络输出,dA_dN 为函数的返回值,输出对输入的导数
该函数使用的算法为:
5. 函数 purelin
purelin 为线性激励函数
A = purelin(N)
info = purelin(code)其中, 为 个 维的输入列向量;A 为函数返回值,A = N,info 根据 code 值不同返回不同的信息,具体同 logsig
该函数使用的算法为:
6. 函数 dpurelin
dpurelin 是函数 purelin 的导函数
dA_dN = dpurelin(N,A)其中, 为 维网络输入,A 为 维网络输出,dA_dN 为函数的返回值,输出对输入的导数
该函数使用的算法为:
3. BP 网络学习函数
1. 函数 learngd
函数 learngd 是梯度下降权值/阈值学习函数,它通过神经元的输入和误差,以及权值和阈值的学习速率计算权值或阈值的变化率
[dW,LS] = learngd(W,P,Z,N,A,T,E,gW,gA,D,LP,LS)
[db,LS] = learngd(b,ones(1,Q),Z,N,A,T,E,gW,gA,D,LP,LS)
info = learngd(code)其中,W 为 维的权值矩阵;b 为 S 维的阈值向量;P 为 组 维的输入向量;ones(1,Q) 为产生一个 Q 维的输入向量;Z 为 Q 组 S 维 的加权输入向量;N 为 Q 组 S 维的输入向量;A 为 Q 组 S 维的输出向量;T 为 Q 组 S 维的层目标向量;E 为 Q 组 S 维的层误差向量;gW 为与性能相关的 维梯度;gA 为与性能相关的 维输出梯度;D 为 维的神经元距离矩阵;LP 为学习参数,可通过该参数设置学习速率,设置格式如 LP.lr = 0.001;LS 为学习状态,初始状态下为空;dW 为 维的权值或阈值变化率矩阵;db 为 S 维的阈值变化率向量;ls 为新的学习状态;learngd(code) 依据不同的 code 返回有关函数的不同信息,具体如下
| code 的取值 | 返回的信息 |
|---|---|
| pnames | 返回设置的学习参数 |
| pdefaults | 返回默认的学习参数 |
| needg | 如果函数使用了 gW 或 gA,则返回 1 |
2. 函数 learngdm
函数 learngdm 为梯度下降动量学习函数,它利用神经元的输入和误差、权值或阈值的学习速率和动量常数计算权值或阈值的变化率
[dW,LS] = learngdm(W,P,Z,N,A,T,E,gW,gA,D,LP,LS)
[db,LS] = learngdm(b,ones(1,Q),Z,N,A,T,E,gW,gA,D,LP,LS)
info = learngdm(code)各参数含义同 learngdm,另外动量常数 mc 是通过学习参数 LP 设置的,其格式为 LP.mc = 0.8
4. BP 网络训练函数
1. 函数 trainbfg
函数 trainbfg 为 BFGS 准牛顿 BP 算法函数,除了 BP 网络外,该函数也可以训练任意形式的神经网络,要求它的激励函数对于权值和输入存在导数
[net,TR,Ac,El] = trainbfg(NET,Pd,Tl,Ai,Q,TS,VV,TV)
info = trainbfg(code)其中,NET 为待训练的神经网络;Pd 为有延迟的输入向量;Tl 为层次目标向量;Ai 为初始的输入延迟条件;Q 为批量;TS 为时间步长;VV 用于确定向量结构或者为空;TV 用于检验向量结构或者为空;net 为训练后的神经网络;TR 为每步训练的有关信息记录,包括:TR.epoch——时刻点,TR.perf——训练性能,TR.vperf——确认性能,TR.tperf——检验性能;Ac 为上一步训练中聚合层的输出;El 为上一步训练中的层次误差;info = trainbfg(code) 根据不同的 code 值返回不同的信息,具体有:
| code 值 | 返回的信息 |
|---|---|
| pnames | 返回设定的训练参数 |
| pdefaults | 返回默认的训练参数 |
在利用该函数进行 BP 网络训练时,matlab 已经默认了一些训练参数,具体如表:
| 参数名称 | 默认值 | 属性 |
|---|---|---|
| net.trainParam.epochs | 100 | 训练次数,人工设定的训练次数不能超过 100 |
| net.trainParam.show | 25 | 两次显示之间的训练步数 |
| net.trainParam.goal | 0 | 训练目标 |
| net.trainParam.time | inf | 训练时间,inf 表示训练时间不限 |
| net.trainParam.min_grad | 1e-6 | 最小性能梯度 |
| net.trainParam.max_fail | 5 | 最大确认失败次数 |
| net.trainParam.searchFcn | ‘srchcha’ | 所用的线性搜索路径 |
2. 函数 traingd
函数 traingd 是梯度下降 BP 算法训练函数
[net,TR,Ac,El] = traingd(NET,Pd,Tl,Ai,Q,TS,VV,TV)
info = traingd(code)以上程序各参数含义、设置格式和使用范围与函数 trainbfg 相同
3. 函数 traingdm
函数 traingdm 为梯度下降动量 BP 算法训练函数
[net,TR,Ac,El] = traingdm(NET,Pd,Tl,Ai,Q,TS,VV,TV)
info = traingdm(code)以上程序各参数含义、设置格式和使用范围与函数 trainbfg 相同
5. 性能函数
1. 函数 mse
函数 mse 为均方误差性能函数
perf = mse(e,x,pp)
perf = mse(e,net,pp)
info = mse(code)其中,e 为误差向量矩阵;x 为所有的权值和阈值向量,可忽略;pp 为性能参数,可忽略;net 为待评定的神经网络;perf 为函数的返回值,为平均绝对误差;info 为根据 code 值的不同,返回不同的信息,如下表
| code 的值 | 返回的信息 |
|---|---|
| deriv | 返回导数函数的名称 |
| name | 返回函数全称 |
| pnames | 返回训练函数的名称 |
| pdefaults | 返回默认的训练函数 |
2. 函数 msereg
perf = msereg(e,x,pp)
perf = msereg(e,net)
info = msereg(code)以上程序中各参数的含义与函数 mse 相同
函数 msereg 是在函数 mse 基础上增加一项网络权值和阈值的均方差,目的是使网络获得较小的权值和阈值,从而迫使网络的响应变得更平滑
3. 组建神经网络的注意事项
1. 神经元节点数量
网络的输入与输出节点数是由实际问题的维数决定的,与网络性能无关。而隐含层节点数 L 的设计就非常重要了,一般可以利用下面两个经验公式之一来确定
或者
其中, 分别为输入节点数与输出节点数数目; 为 1~10 之间的常数
隐藏节点数可以根据上面两个公式得出一个初始值,然后利用逐步增长或逐步修剪法最终确定神经元的个数。逐步增长是从一个较简单的网络开始,若训练结果不符合要求,则逐步增加隐含层神经元个数直到合适为止;逐步修剪则从一个较复杂的网络开始逐步删除隐含层神经元
2. 数据预处理和后期处理
MATLAB 中提供的预处理方法有如下几个:
- 归一化处理:将每组数据都变为 -1~1 之间的数,所涉及的函数有 mapminmax、postmnmx、tramnmx
- 标准化处理:将每组数据都化为均值为 0、方差为 1 的一组数据,所涉及的函数有 prestd、poststd、trastd
- 主成分分析:进行正交处理,可减少输入数据的维数,所涉及的函数有 prepca、trapca
- 回归分析与相关性分析:涉及的函数有 postrg 等
1. 函数 premnmx
归一化函数 premnmx
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)
[pn,minp,maxp] = premnmx(p)其中,p 为 维输入矩阵;pn 为标准化的 维输入矩阵;minp 为 维包含 p 的每个分量最小值的向量;maxp 为 维包含 p 的每个分量最大值的向量;tn 为标准化的 维目标矩阵;mint 为 维包含 t 的每个分量;maxt 为 维包含 t 的每个分量最大值的向量
该函数使用的算法为:
4. 实例
1. 问题描述
公路运量主要包括公路运客量和公路货运量两个方面。据研究,某地区的公路运量主要与该地区的人数、机动车数量和公路面积有关。
根据相关部门数据,该地区 2010 年和 2011 年的人数分别为 73.39 和 75.55 万人,机动车数量分别为 3.9635 和 4.0975 万辆,公路面积将分别为 0.9880 和 1.0268 万平方千米。
请利用 BP 网络预测该地区 2010 和 2011 年的公路客运量和公路货运量
| 年份 | 人口数量/万人 | 机动车数量/万辆 | 公路面积/万平方千米 | 公路运客量/万人 | 公路货运量/万吨 |
|---|---|---|---|---|---|
| 1990 | 55 | 6 | 09 | 5126 | 1237 |
| 1991 | 22.44 | 0.75 | 0.11 | 6217 | 1379 |
| 1992 | 25.37 | 0.85 | 0.11 | 7730 | 1385 |
| 1993 | 27.13 | 0.90 | 0.14 | 9145 | 1399 |
| 1994 | 29.45 | 1.05 | 0.20 | 10460 | 1663 |
| 1995 | 30.1 | 1.35 | 0.23 | 11387 | 1714 |
| 1996 | 30.96 | 1.45 | 0.23 | 12353 | 1834 |
| 1997 | 34.06 | 1.60 | 0.32 | 15750 | 4322 |
| 1998 | 36.42 | 1.70 | 0.32 | 18304 | 8132 |
| 1999 | 38.09 | 1.85 | 0.34 | 19836 | 8936 |
| 2000 | 39.13 | 2.15 | 0.36 | 21024 | 11099 |
| 2001 | 39.99 | 2.20 | 0.36 | 19490 | 11203 |
| 2002 | 41.93 | 2.25 | 0.38 | 20433 | 10524 |
| 2003 | 44.59 | 2.35 | 0.49 | 22598 | 11115 |
| 2004 | 47.30 | 2.50 | 0.56 | 25107 | 13320 |
| 2005 | 52.89 | 2.60 | 0.59 | 33442 | 16762 |
| 2006 | 55.73 | 2.70 | 0.59 | 36836 | 18673 |
| 2007 | 56.76 | 2.85 | 0.67 | 40548 | 20724 |
| 2008 | 59.17 | 2.95 | 0.69 | 42927 | 20803 |
| 2009 | 60.63 | 3.10 | 0.79 | 43462 | 21804 |
2. 工具箱求解过程
1. 原始数据的输入
clc
%原始数据
%人数(单位:万人)
sqrs=[20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 ...
41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63];
%机动车数(单位:万辆)
sqjdcs=[0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.25 2.35 2.5 2.6...
2.7 2.85 2.95 3.1];
%公路面积(单位:万平方公里)
sqglmj=[0.09 0.11 0.11 0.14 0.20 0.23 0.23 0.32 0.32 0.34 0.36 0.36 0.38 0.49 ...
0.56 0.59 0.59 0.67 0.69 0.79];
%公路客运量(单位:万人)
glkyl=[5126 6217 7730 9145 10460 11387 12353 15750 18304 19836 21024 19490 20433 ...
22598 25107 33442 36836 40548 42927 43462];
%公路货运量(单位:万吨)
glhyl=[1237 1379 1385 1399 1663 1714 1834 4322 8132 8936 11099 11203 10524 11115 ...
13320 16762 18673 20724 20803 21804];
p=[sqrs;sqjdcs;sqglmj]; %输入数据矩阵
t=[glkyl;glhyl]; %目标数据矩阵2. 数据归一化
%利用premnmx函数对数据进行归一化
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); % 对于输入矩阵p和输出矩阵t进行归一化处理
dx=[-1,1;-1,1;-1,1]; %归一化处理后最小值为-1,最大值为13. 网络训练
%BP网络训练
net=newff(dx,[3,7,2],{'tansig','tansig','purelin'},'traingdx'); %建立模型,并用梯度下降法训练.
net.trainParam.show=1000; %1000轮回显示一次结果
net.trainParam.Lr=0.05; %学习速度为0.05
net.trainParam.epochs=50000; %最大训练轮回为50000次
net.trainParam.goal=0.65*10^(-3); %均方误差
net=train(net,pn,tn); %开始训练,其中pn,tn分别为输入输出样本4. 对原始数据进行仿真
%利用原始数据对BP网络仿真
an=sim(net,pn); %用训练好的模型进行仿真
a=postmnmx(an,mint,maxt); % 把仿真得到的数据还原为原始的数量级;5. 将原始数据仿真的结果与已知样本进行对比
%本例因样本容量有限使用训练数据进行测试,通常必须用新鲜数据进行测试
x=1990:2009;
newk=a(1,:);
newh=a(2,:);
figure (2);
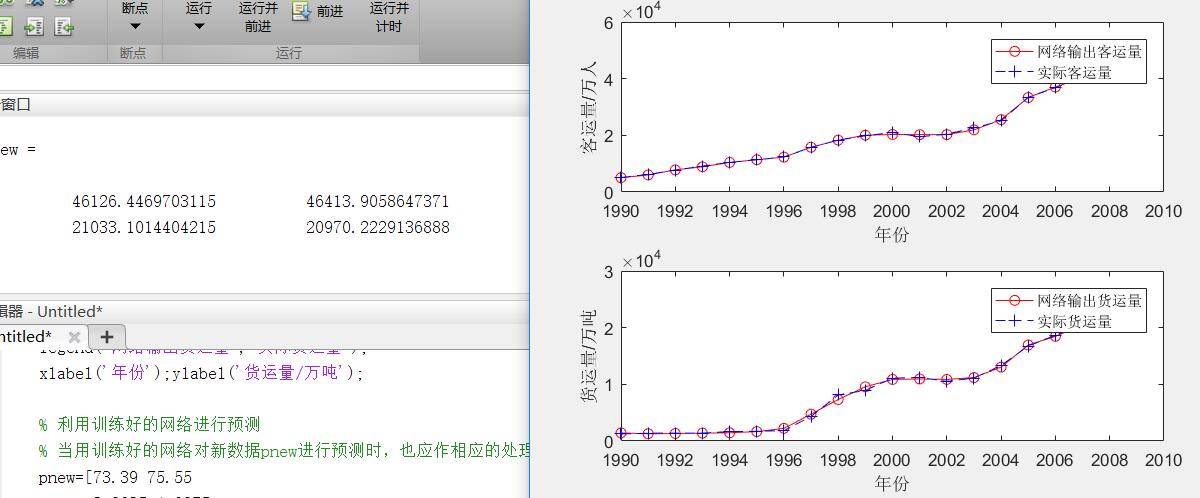
subplot(2,1,1);plot(x,newk,'r-o',x,glkyl,'b--+') %绘值公路客运量对比图;
legend('网络输出客运量','实际客运量');
xlabel('年份');ylabel('客运量/万人');
subplot(2,1,2);plot(x,newh,'r-o',x,glhyl,'b--+') %绘制公路货运量对比图;
legend('网络输出货运量','实际货运量');
xlabel('年份');ylabel('货运量/万吨');6. 对新数据进行仿真
%利用训练好的网络进行预测
% 当用训练好的网络对新数据pnew进行预测时,也应作相应的处理:
pnew=[73.39 75.55
3.9635 4.0975
0.9880 1.0268]; %2010年和2011年的相关数据;
pnewn=tramnmx(pnew,minp,maxp); %利用原始输入数据的归一化参数对新数据进行归一化;
anewn=sim(net,pnewn); %利用归一化后的数据进行仿真;
anew=postmnmx(anewn,mint,maxt) %把仿真得到的数据还原为原始的数量级;7. 综合程序
clc
%原始数据
%人数(单位:万人)
sqrs=[20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 ...
41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63];
%机动车数(单位:万辆)
sqjdcs=[0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.25 2.35 2.5 2.6...
2.7 2.85 2.95 3.1];
%公路面积(单位:万平方公里)
sqglmj=[0.09 0.11 0.11 0.14 0.20 0.23 0.23 0.32 0.32 0.34 0.36 0.36 0.38 0.49 ...
0.56 0.59 0.59 0.67 0.69 0.79];
%公路客运量(单位:万人)
glkyl=[5126 6217 7730 9145 10460 11387 12353 15750 18304 19836 21024 19490 20433 ...
22598 25107 33442 36836 40548 42927 43462];
%公路货运量(单位:万吨)
glhyl=[1237 1379 1385 1399 1663 1714 1834 4322 8132 8936 11099 11203 10524 11115 ...
13320 16762 18673 20724 20803 21804];
p=[sqrs;sqjdcs;sqglmj]; %输入数据矩阵
t=[glkyl;glhyl]; %目标数据矩阵
%利用premnmx函数对数据进行归一化
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); % 对于输入矩阵p和输出矩阵t进行归一化处理
dx=[-1,1;-1,1;-1,1]; %归一化处理后最小值为-1,最大值为1
%BP网络训练
net=newff(dx,[3,7,2],{'tansig','tansig','purelin'},'traingdx'); %建立模型,并用梯度下降法训练.
net.trainParam.show=1000; %1000轮回显示一次结果
net.trainParam.Lr=0.05; %学习速度为0.05
net.trainParam.epochs=50000; %最大训练轮回为50000次
net.trainParam.goal=0.65*10^(-3); %均方误差
net=train(net,pn,tn); %开始训练,其中pn,tn分别为输入输出样本
%利用原始数据对BP网络仿真
an=sim(net,pn); %用训练好的模型进行仿真
a=postmnmx(an,mint,maxt); % 把仿真得到的数据还原为原始的数量级;
%本例因样本容量有限使用训练数据进行测试,通常必须用新鲜数据进行测试
x=1990:2009;
newk=a(1,:);
newh=a(2,:);
figure (2);
subplot(2,1,1);plot(x,newk,'r-o',x,glkyl,'b--+') %绘值公路客运量对比图;
legend('网络输出客运量','实际客运量');
xlabel('年份');ylabel('客运量/万人');
subplot(2,1,2);plot(x,newh,'r-o',x,glhyl,'b--+') %绘制公路货运量对比图;
legend('网络输出货运量','实际货运量');
xlabel('年份');ylabel('货运量/万吨');
%利用训练好的网络进行预测
% 当用训练好的网络对新数据pnew进行预测时,也应作相应的处理:
pnew=[73.39 75.55
3.9635 4.0975
0.9880 1.0268]; %2010年和2011年的相关数据;
pnewn=tramnmx(pnew,minp,maxp); %利用原始输入数据的归一化参数对新数据进行归一化;
anewn=sim(net,pnewn); %利用归一化后的数据进行仿真;
anew=postmnmx(anewn,mint,maxt) %把仿真得到的数据还原为原始的数量级;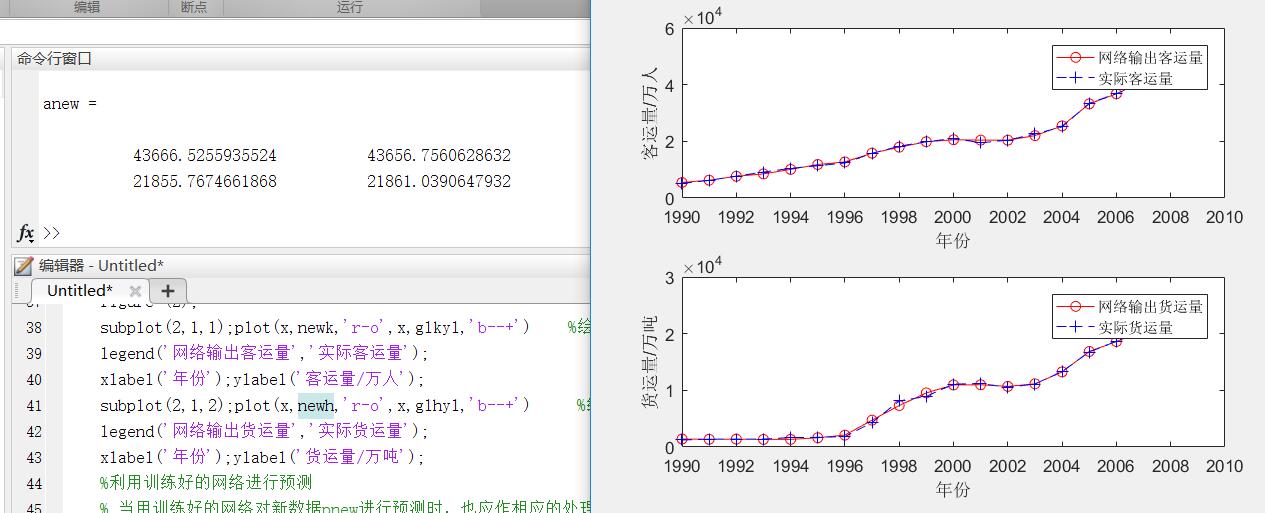
3. 源程序求解过程
clc % 清屏
clear all; %清除内存以便加快运算速度
close all; %关闭当前所有figure图像
SamNum=20; %输入样本数量为20
TestSamNum=20; %测试样本数量也是20
ForcastSamNum=2; %预测样本数量为2
HiddenUnitNum=8; %中间层隐节点数量取8,比工具箱程序多了1个
InDim=3; %网络输入维度为3
OutDim=2; %网络输出维度为2
%原始数据
%人数(单位:万人)
sqrs=[20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 ...
41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63];
%机动车数(单位:万辆)
sqjdcs=[0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.25 2.35 2.5 2.6...
2.7 2.85 2.95 3.1];
%公路面积(单位:万平方公里)
sqglmj=[0.09 0.11 0.11 0.14 0.20 0.23 0.23 0.32 0.32 0.34 0.36 0.36 0.38 0.49 ...
0.56 0.59 0.59 0.67 0.69 0.79];
%公路客运量(单位:万人)
glkyl=[5126 6217 7730 9145 10460 11387 12353 15750 18304 19836 21024 19490 20433 ...
22598 25107 33442 36836 40548 42927 43462];
%公路货运量(单位:万吨)
glhyl=[1237 1379 1385 1399 1663 1714 1834 4322 8132 8936 11099 11203 10524 11115 ...
13320 16762 18673 20724 20803 21804];
p=[sqrs;sqjdcs;sqglmj]; %输入数据矩阵
t=[glkyl;glhyl]; %目标数据矩阵
[SamIn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %原始样本对(输入和输出)初始化
rand('state',sum(100*clock)) %依据系统时钟种子产生随机数
NoiseVar=0.01; %噪声强度为0.01(添加噪声的目的是为了防止网络过度拟合)
Noise=NoiseVar*randn(2,SamNum); %生成噪声
SamOut=tn + Noise; %将噪声添加到输出样本上
TestSamIn=SamIn; %这里取输入样本与测试样本相同因为样本容量偏少
TestSamOut=SamOut; %也取输出样本与测试样本相同
MaxEpochs=50000; %最多训练次数为50000
lr=0.035; %学习速率为0.035
E0=0.65*10^(-3); %目标误差为0.65*10^(-3)
W1=0.5*rand(HiddenUnitNum,InDim)-0.1; %初始化输入层与隐含层之间的权值
B1=0.5*rand(HiddenUnitNum,1)-0.1; %初始化输入层与隐含层之间的阈值
W2=0.5*rand(OutDim,HiddenUnitNum)-0.1; %初始化输出层与隐含层之间的权值
B2=0.5*rand(OutDim,1)-0.1; %初始化输出层与隐含层之间的阈值
ErrHistory=[]; %给中间变量预先占据内存
for i=1:MaxEpochs
HiddenOut=logsig(W1*SamIn+repmat(B1,1,SamNum)); % 隐含层网络输出
NetworkOut=W2*HiddenOut+repmat(B2,1,SamNum); % 输出层网络输出
Error=SamOut-NetworkOut; % 实际输出与网络输出之差
SSE=sumsqr(Error) %能量函数(误差平方和)
ErrHistory=[ErrHistory SSE];
if SSE<E0,break, end %如果达到误差要求则跳出学习循环
% 以下六行是BP网络最核心的程序
% 他们是权值(阈值)依据能量函数负梯度下降原理所作的每一步动态调整量
Delta2=Error;
Delta1=W2'*Delta2.*HiddenOut.*(1-HiddenOut);
dW2=Delta2*HiddenOut';
dB2=Delta2*ones(SamNum,1);
dW1=Delta1*SamIn';
dB1=Delta1*ones(SamNum,1);
%对输出层与隐含层之间的权值和阈值进行修正
W2=W2+lr*dW2;
B2=B2+lr*dB2;
%对输入层与隐含层之间的权值和阈值进行修正
W1=W1+lr*dW1;
B1=B1+lr*dB1;
end
HiddenOut=logsig(W1*SamIn+repmat(B1,1,TestSamNum)); % 隐含层输出最终结果
NetworkOut=W2*HiddenOut+repmat(B2,1,TestSamNum); % 输出层输出最终结果
a=postmnmx(NetworkOut,mint,maxt); % 还原网络输出层的结果
x=1990:2009; % 时间轴刻度
newk=a(1,:); % 网络输出客运量
newh=a(2,:); % 网络输出货运量
figure ;
subplot(2,1,1);plot(x,newk,'r-o',x,glkyl,'b--+') %绘值公路客运量对比图;
legend('网络输出客运量','实际客运量');
xlabel('年份');ylabel('客运量/万人');
subplot(2,1,2);plot(x,newh,'r-o',x,glhyl,'b--+') %绘制公路货运量对比图;
legend('网络输出货运量','实际货运量');
xlabel('年份');ylabel('货运量/万吨');
% 利用训练好的网络进行预测
% 当用训练好的网络对新数据pnew进行预测时,也应作相应的处理
pnew=[73.39 75.55
3.9635 4.0975
0.9880 1.0268]; %2010年和2011年的相关数据;
pnewn=tramnmx(pnew,minp,maxp); %利用原始输入数据的归一化参数对新数据进行归一化;
HiddenOut=logsig(W1*pnewn+repmat(B1,1,ForcastSamNum)); % 隐含层输出预测结果
anewn=W2*HiddenOut+repmat(B2,1,ForcastSamNum); % 输出层输出预测结果
%把网络预测得到的数据还原为原始的数量级;
anew=postmnmx(anewn,mint,maxt)