1、线性回归算法
例如根据房屋面积进行价格预测
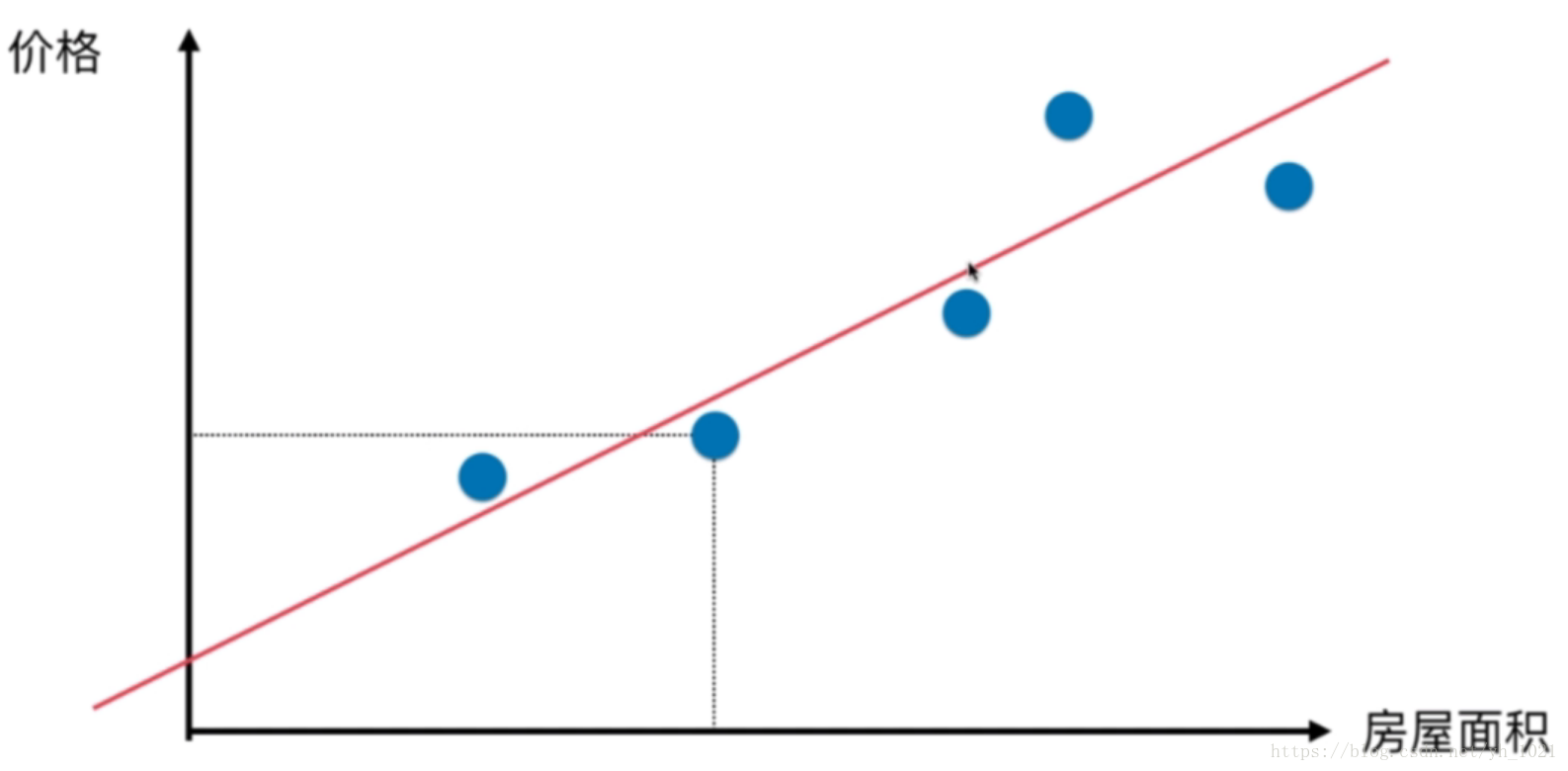
希望寻找一条直线,最大程度“拟合”样本特征(房屋面积)和样本输出标记(价格)之间的关系。
假设该直线方程为y=ax+b,每一个样本点的坐标为
,每一个
预测的值
,计算真实值和预测值之间的差距,并使其尽量小,为了使计算可导,利用欧拉距离计算差距
。
目标:找到a和b,使得
尽可能小
(通过分析问题,确定问题的损失函数或者效用函数,通过最优化损失函数或者效用函数,获得机器学习模型)
利用最小二乘法(求偏导数)就可以求得损失函数最小时的参数a、b的值。
2、线性回归算法的评测
算出a和b值后,将测试数据的x坐标带入方程得到预测的y坐标值,衡量标准为:
又因为这个衡量标准与样本数据量m有关,所以除以m,得到新的衡量标准:均方误差MSE
为了使量纲与距离y相同,所以开方根得到均方根误差RMSE:
还有平均绝对误差MAE:(之前计算损失函数因为要求导所以不能用绝对值,这里评测时可以):
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
#利用sklearn中波士顿房价的数据
boston=datasets.load_boston()
#打印波士顿房价数据的特征名称,选择RM特征(第六个特征)
print(boston.feature_names)
x=boston.data[:,5]
y=boston.target
#去除上限值,可能不是真是的点
x=x[y<50.0]
y=y[y<50.0]
plt.scatter(x,y)
plt.show()
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
from sklearn.linear_model import LinearRegression
reg=LinearRegression()
#注:因为sklearn中的线性回归模型需要二维的数组来进行拟合但是这里只有一个特征所以需要reshape来转换为二维数组
x_train=x_train.reshape(-1,1)
y_train=y_train.reshape(-1,1)
reg.fit(x_train,y_train)
print(reg.coef_) #打印斜率
print(reg.intercept_) #打印截距
y_train_predict=reg.predict(x_train)
plt.scatter(x_train,y_train)
plt.plot(x_train,y_train_predict,color='r')
plt.show()
x_test=x_test.reshape(-1,1)
y_test_predict=reg.predict(x_test)
#在skleran中计算MSE和MAE
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
mean_MSE=mean_squared_error(y_test,y_test_predict)
print(mean_MSE)
from math import sqrt
mean_RMSE=sqrt(mean_MSE)
print(mean_RMSE)
mean_MAE=mean_absolute_error(y_test,y_test_predict)
print(mean_MAE)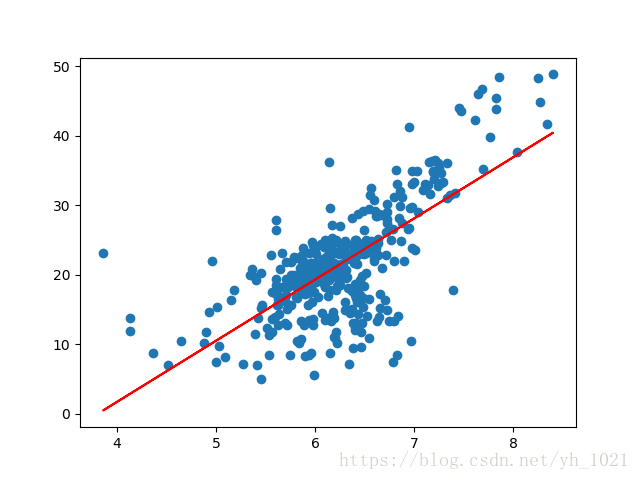
输出结果为:
[[8.68833821]] #斜率
[-32.60743471] #截距
41.34495045353025 #MSE
6.430003923290425 #RMSE
4.391472766349768 #MAE虽然两者量纲相同,但可以看出RMSE的数值大于MAE,因为RMSE的误差经过平方项后再开方,误差被放大了,而MAE是直接表示预测值和真值之间的差距。所以使RMSE更小更有意义。
3、使用R Squared(R方)评测模型
其中 为样本数据的平均值。
- 越大越好,若预测的y值与真值相同,则 为最大值1
- 如果 <0,说明模型还不如基准模型,可能数据不存在线性关系,则不能用线性回归.
最终可以表示为1-MSE除以y值的方差:
R_square=1-mean_squared_error(y_test,y_test_predict)/np.var(y_test)
#输出0.3610551467037436
#在sklearn中
from sklearn.metrics import r2_score
R=r2_score(y_test,y_test_predict)
print(R)
#输出0.3610551467037436
注:sklearn中线性回归的.score方法运用的就是R方
R1=reg.score(x_test,y_test)4、多元线性回归
假设一个样本共有n个特征:
,需要通过
来拟合,共有n+1个参数,
为截距。
多元线性回归的正规方程解:
为了使目标:
尽可能小,可得到
.
用sklearn直接计算多元线性回归:
from sklearn import datasets
boston=datasets.load_boston()
X=boston.data
Y=boston.target
X=X[Y<50]
Y=Y[Y<50]
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,Y,random_state=666,test_size=0.2)
from sklearn.linear_model import LinearRegression
lin=LinearRegression()
lin.fit(x_train,y_train)
print(lin.coef_)
print(lin.intercept_)
##KNN线性回归
from sklearn.neighbors import KNeighborsRegressor
KNN=KNeighborsRegressor()
KNN.fit(x_train,y_train)
print(KNN.score(x_test,y_test))
由于每个特征前面的系数代表了该特征的影响程度,正的为正相关,数值越大表明越相关。通过对特征前面的系数排序可以得知特征的重要性。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston=datasets.load_boston()
X=boston.data
Y=boston.target
X=X[Y<50]
Y=Y[Y<50]
from sklearn.linear_model import LinearRegression
lin=LinearRegression()
lin.fit(X,Y)
print(lin.coef_)
print(lin.intercept_)
print(np.argsort(lin.coef_)) #给每个特征的系数排序
print(boston.feature_names)
print(boston.feature_names[np.argsort(lin.coef_)]) #打印出排序之后的影响因素输出:RM即为影响程度最大的特征
[-1.05574295e-01 3.52748549e-02 -4.35179251e-02 4.55405227e-01
-1.24268073e+01 3.75411229e+00 -2.36116881e-02 -1.21088069e+00
2.50740082e-01 -1.37702943e-02 -8.38888137e-01 7.93577159e-03
-3.50952134e-01]
32.26110687531778
[ 4 7 10 12 0 2 6 9 11 1 8 3 5]
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
['NOX' 'DIS' 'PTRATIO' 'LSTAT' 'CRIM' 'INDUS' 'AGE' 'TAX' 'B' 'ZN' 'RAD'
'CHAS' 'RM']