Redis系列-6.集合(Set)结构
文章中可能有地方描述偏差,欢迎留言指证
1.基本
redsi里的集合叫set,和其他语言有一些不同。在数据结构上,集合里的数据原则上是没有先后的。就像去超市买了一大袋东西,袋子就是一个集合,里面的东西也没什么必然的联系吧?
2.常用命令
下面所有描述里 {}都是必需参数,<>是可选参数
设置值
sadd {key} {element} 可以新添加一个集合并一次添加多个元素,向旧有的集合里添加数据也是用这个
获取值
smembers {key}和前面列表不一样,因为没有顺序,不能直接获取某一个数据,只能随机获取。要不就是获取集合中所有数据
此命令是比较重的,和lrange(遍历列表) hgetall(遍历哈希表)一样,都不建议在线上环境中使用。
删除元素
srem {key} {element} [element....]此命令会先判断元素是不是在集合中,是的话会删除。结果是返回删除的个数。。如果不在集合中会返回0。。也就是说,返回0此命令没什么产生什么效果。
计算元素个数
scard {key} 和前面讲到的一样,此命令不会去遍历,会直接取内部值。时间复杂度是O(1);
判断元素是否在集合中
sismember {key} {element} 从集合中随机弹出元素
spop {key} {count} //count参数从redis3.2版本起才支持,windows版最新版也支持了这个弹出命令是集合中用的比较多的命令,注意是随机的!至于真随机还是伪随机,个人推测这里是用伪随机达到了真随机的效果。redis是单线程程序,也就是说单位时间内只会有一条命令在执行,伪随机里有时间来做种子,既然时间不一样了,那就不可能产生两个相同的随机数,所以也就是真随机了。
命令执行后,会返回从集合中弹出的数据。
从redis 3.2版起,此命令也支持count参数了,但是要注意的是:此命令会删除数据
随机从集合中返回指定个数元素
srandmember {key} {count} 随机的和上面一样的推测,结果也是返回多个。
和上面命令不用的是:此命令不会删除数据
3.集合间的操作
这些集合间的操作和数学中的集合一样的。。差集 并集 交集等等
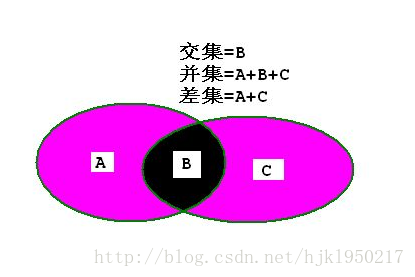
求多个集合的交集
sinter {key} [key...]此命令会返回两个集合中,有相同元素的(值相同就行)。如果有2个集合以上来求交集,那就会多个集合的元素值都有一样的才会有结果,否则就不行。
求多个集合的并集
suinon {key} [key...]命令也是一样,返回结果。。并集什么意思就不用讲了呗
求多个集合的差集
sdiff {key} [key...]命令也是一样,返回结果。。差集什么意思就不用讲了呗。在最上面那个图有解释。
将集合操作保存
sinterstore {TargetKey} {key} [key....]//保存交集
suionstore {TargetKey} {key} [key....]//保存并集
sdiffstore {TargetKey} {key} [key....]//保存差集
把第二个参数key和后面的key的交\并\差集结果保存在TargetKey这个参数的集合里集合操作在元素比较多的情况下是比较费时的,redis也提供了保存结果的命令。这里就是把结果保存在第一个集合里。
这个在设计时就要考虑要不要保存结果。。虽然说保存下来做缓存是好的,但是也增加了复杂性。在设计时就要权衡这些,往往在增强一个点时,另一些地方可能就会显露出不足。在业务不复杂的、查询量大时,可以保存下来结果,增加的复杂性不大,但效果却好。如果业务比较多或是复杂了,性能上有要求时,这会就要具体分析了。。因为保存结果的这个集合,也是需要管理的啊。。
4.内部编码
有两种:
intset:整数集合,当集合全是整数而且元素个数小于配置set-max-intset-entries的时候,会使用这个类型
hashtable:哈希表,当集合不满足inset条件时,使用这个类型
5.适合场景
1.标签
标签是不用分顺序的,所以集合适合这类场景。比如用户的兴趣爱好、热点分类等。。建议:给用户添加标签可以同时按标签添加用户,并放在一个事务内执行。。这样就可以很简单的实现博客中的功能(文章按标签分类了,同时点标签也会查看所有有这个标签文章)。热点排行可以用后面的有序集合
2.抽奖
集合中有随机弹出和随机获取功能,可以用来完成抽奖功能。调整权重时也可以控制集合里重复的元素来控制权重,当然也可以用后面的有序集合。