问题描述
老板最近给了我一个空间数据压缩包,压缩包中包含10个文件,每一个文件中包含ID、X坐标、Y坐标、元素一、元素二五种标签,每个大约包含四百万条数据。老板对我提出的要求是以一个文件的XY坐标为准,找出其他九个文件中与其最相近的坐标,将相近坐标的两个元素复制到标准文件中。
| ID | X | Y | 元素一 | 元素二 |
|---|
菜鸟级想法
当时听到这个要求是,脑海中立马跳出一个想法,将标准文件的XY坐标与比较文件的所有XY坐标进行求距离得到最小值就OK了嘛。想法很美好,结果很现实,写了个matlab函数进行操作结果5个小时没搞出来,这个算法的时间复杂度为 ,n为百万级单位,在我的小破笔记本上短时间计算出来好比中国足球在世界杯拿冠军。
改进算法
将标准文件的一个xy坐标与相近文件的所有xy坐标进行距离计算是没有必要的,只需要计算一个范围的数据即可,在此基础上在进行下面算法的调整能大幅度减少计算量。但又产生了一个问题,如何进行排序,为此我下面探究了内部排序的六种算法。
for 依次遍历标准文件的每行数据
low = x - radius;
high = x + radius ;
使用二分法在相似文件中寻找半径内的坐标
for 依次遍历半径内的坐标
计算distance,寻找最小值,并进行移动。
end
end;排序算法比较
这里使用c++的clock()函数测试程序运行时间,测试环境为centos Linux 7,内存13.3GiB,处理器Intel® Core™ i5-4300M CPU @ 2.60GHz × 4 ,测试数量为10w万条,相关代码如下:
- 算法运行时间计算
#include<time.h> //头文件
clock_t start_time = clock(); //获取程序运行时间点
clock_t end_time = clock(); //获取程序结束时间点
cout << "sortInsertSort Running time is :" <<
static_cast<double>(end_time-start_time)/CLOCKS_PER_SEC
<<" s" << endl; //计算运行时间- 直接插入排序算法
直接插入算法知识清查阅相关资料,这里近给出代码和相关注释。
void direcInsertSort( ) //直接插入排序
{
double temp = 0.0;
for(int i=1; i < len ;i++) //len为数据的长度
{
for(int j=i;j >= 0;j--)
{
if(data_x[j]<data_x[j-1])
{
temp = data_x[j-1];
data_x[j-1] = data_x[j];
data_x[j] = temp;
}
}
}
} 运行结果:

- 希尔排序
希尔排序算法知识请查阅相关资料,这里仅给出相关代码和注解
void shellSort(double data[],int len)
{
for(int div = len/2;div >=1 ; div = div/2) //将数据拆分
{
for(int i = 0;i < div; i++) //对每部分进行排序
{
for(int j = i;j< len - div;j += div) //进行直接插入排序
{
for(int m = j + div ;m >= 0; m -= div)
{
if(data[m]<data[m-div])
{
temp = data[m-div];
data[m-div] = data[m];
data[m] = temp;
}
}
}
}
} 运行结果:

- 简单选择排序
简单选择排序算法知识请查阅相关资料,这里仅给出相关代码和注解。
void simpleSelectSort(double data[],int len)
{
int min = 0;
double temp = 0.0;
for(int i = 0 ; i < len ;i++) //从最小到最大的位置
{
min = i;
for(int j= i+1 ;j < len;j++)
{
if(data[j] < data[i])
{
min = j; //记录第i小的数据位置
}
}
if(min != i) //如果第i小的数据不再坐标i上,进行交换
{
temp = data[i];
data[i] =data[min];
data[min] = temp;
}
}
} 运行结果:


- 堆排序
堆排序知识请查阅相关资料,这里仅提供相关代码和注解,这里采用小跟堆和向下调整法。
void adjustHeap(int i,int len,double data[]) //调整函数
{
double temp = data[i];
for(int k = i*2 +1;k<len;k = k*2+1)
{
if(k+1 < len &&data[k] < data[k+1])
{
k++;
}
if(data[k] > temp)
{
data[i] = data[k];
i = k;
}
else
break;
}
data[i] = temp;
}
void heapSort(double data[],int len) //主函数
{
for(int i = len/2-1;i>= 0 ; i--)
adjustHeap(i,len,data)
for(int j = len -1;j>0;j--)
{
int temp = data[0];
data[0] =data[j];
data[j] = temp;
adjustHeap(0,j,data);
}
}运行结果为:
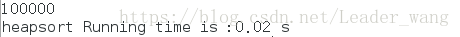
- 冒泡排序
冒泡排序知识请查阅相关资料,这里仅给出相关代码和注解。
void bubbleSort(double data[],int len)
{
double temp = 0.0;
for(int i = 0;data[i] != 0;i++)
{
for(int j = 0; j < len - i - 1;j++ )
{
if(data[j] > data[j+1])
{
temp = data[j+1];
data[j+1] = data[j];
data[j] = temp;
}
}
}
}运行结果:

- 快速排序算法
快速排序算法知识请查阅相关资料,这里仅给出相关代码和注解。
void quickSort(double &data[],int left,int right)
{
if(left >= right)
return ;
int i = left;
int j = right;
int key = data[left];
while(i < j)
{
while(i < j && key <= data[j])
j--;
data[i] = data[j];
while(i <j && key >= data[i])
i++;
data[j] = data[i];
}
data[i] = key;
quickSort(data,left,j-1);
quickSort(data,i+1,right);
}运行结果:

结果分析
| 排序算法 | 运行时间 |
|---|---|
| 快速排序 | 0.01s |
| 堆排序 | 0.02 |
| 简单选择排序 | 0.12 |
| 直接插入排序 | 0.15 |
| 希尔排序 | 0.32 |
| 冒泡排序 | 15.6 |
从图表中我们得知快速排序法最适合用于排序,因为它的时间复杂度和空间复杂度都是最优的,下面我们编写改进的算法看看效果。
- 二分查找算法
int binarySearch(int data[],int low,int high,int target)
{
while(low<=hight)
{
int mid = (low + hight) / 2 ;
if(target = data[mid])
return mid;
else if(target > data[mid])
low =mid +1;
else
high = mid -1;
}
return -1;
}仔细考虑了一下,二分法只能找到模糊的界线,不适用与精确的要求,实际还是依次判断坐标是否在范围内。
for 依次遍历标准文件的每行数据
for 从相似文件上次开始的起始坐标遍历 因为已经排好序
if 标准x坐标-相似x坐标 > radius
continue;进入下一次循环
else if 相似x坐标-标准x坐标 > radius
break;跳出此次循环
else
计算distance,记录相似文件起始坐标,寻找最相近距离的坐标,进行相关数据的替换
end
end;下面为核心代码:
void getResult()
{
int min_distance = INT_MAX;
int position = -1;
int low = 0,remem_label = 0;
for(int i = 0 ; i< len_podu;i++)
{
int distance = 0;
for(int j = low;j < len_gouzao;j++)
{
if((podu[i][1] - gouzao[j][1])> radius)
continue;
else if((gouzao[j][1]-podu[i][1]) > radius)
break;
else
{
if(remem_label == 0)
{
low = j;
remem_label = 1;
}
distance = pow(podu[i][1]- gouzao[j][1],2)+
pow(podu[i][2] - gouzao[j][2],2);
if(distance < min_distance)
{
min_distance = distance;
position = j;
}
}
}
remem_label = 0 ;
podu[i][3] = gouzao[position][3];
podu[i][4] = gouzao[position][4];
min_distance = INT_MAX;
}
}运行结果:

经过上面的调整之后程序运行已经从7个小时降到了不足15分钟,优化的大多也是减去了不必要的运算,所以在编程序之前认真分析数据和思考相关算法是十分重要的。