本环境使用Ubuntu-18.04.1 64,分布式集群方式(三台虚拟机:一台namenode,俩台datanode)
创建hadoop用户(三台都要)
为了操作方便,如果安装Ubuntu的时候不是“hadoop”用户,则需要增加一个名为hadoop的用户。
打开终端是 ctrl+alt+t
Ubuntu终端窗口中,复制粘贴的快捷键需要加上 shift,即粘贴是 ctrl+shift+v
创建用户:
sudo useradd -m hadoop -s /bin/bash
设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo
注销当前用户(在右上角),在登陆界面使用hadoop用户进行登陆
更新apt
由于Ubuntu的一些特性,需要随时更新一下apt,不然有时候软件安装不了
sudo apt-get update
后续配置文件的过程中,很多人喜欢用vi ,vim。为了图方便可以使用gedit,请将后面用到 vim 的地方改为 gedit
安装最新版本的Java
更新软件列表
sudo apt-get update
安装openjdk-8-jdk
sudo apt-get install openjdk-8-jdk
查看Java版本,如下:
java -version

安装好 OpenJDK 后,需要找到相应的安装路径
update-alternatives --config java

我们输出的路径为 /usr/lib/jvm/java-8-open-jdk-amd64/jre/bin/java
其中,绝对路径为 /usr/lib/jvm/java-8-open-jdk-amd64
接着配置 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置
sudo vi ~/.bashrc
在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为绝对路径,并保存:

让该环境变量生效
source ~/.bashrc
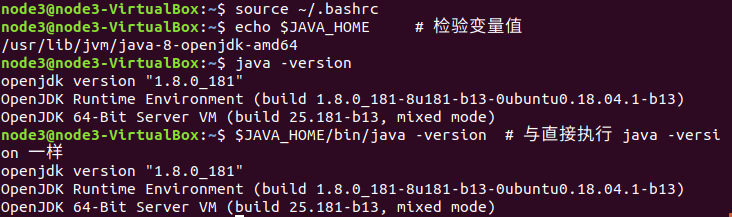
设置好后我们来检验一下是否设置正确:
echo $JAVA_HOME # 检验变量值
java -version
$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
如果正确的话
第一个会输出JAVA安装路径
第二个和第三个输出的Java安装版本一致
这样,Hadoop 所需的 Java 运行环境就安装好了
特别感谢:
给力星前辈写的非常好,单机和集群俩篇文章对我启发都很大。可以说我的第一个hadoop集群就是在他的博文指导下搭建好的。吃水不忘挖井人,在向前辈表示感谢的同时,特此附上原网址: