一、Mysql执行查询流程
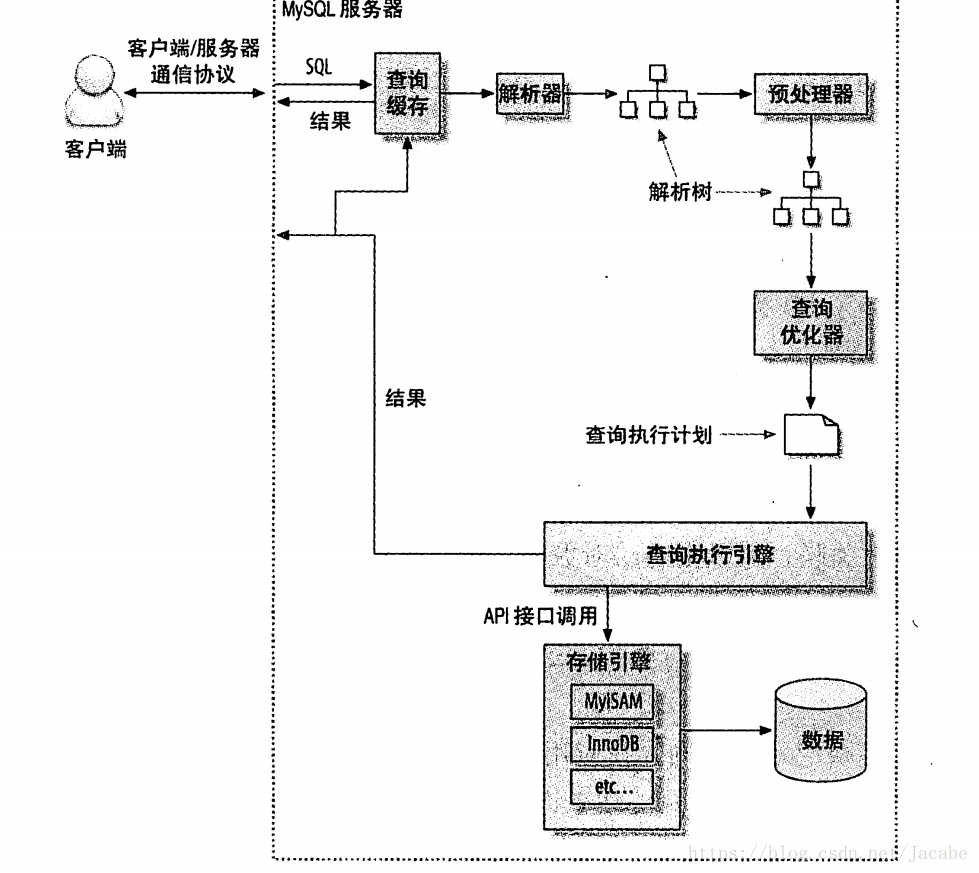
mysql执行查询的流程
mysql执行查询内部路程:1.客服端发送一条查询给服务器
2.服务器先检查查询缓存,如果命中缓存,立刻返回存储在缓存的结果,否则进入下一阶段。
3.服务器端进行sql解析,预处理,再由优化器生成对应的执行计划。
将一个SQL转换成一个执行计划,MySQL再依照这个执行计划和存储引擎进行交互,者包括多个子阶段,解析SQL,预处理,优化sql执行计划。
4.mysql根据优化器生成的执行计划,调用存储引擎的api来执行查询
5.将结果返回给客户端。
优化数据访问: 1、只查询需要的记录,如使用limit等
2、多表关联时不要返回全部列
3、查询不取出全部列
4、不要重复查询相同的数据:不断重复执行相同的查询,然后每次都返回相同的数据,比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出。
对于MySQl,最简单的衡量查询开销的三个指标如下:
响应时间
扫描的行数
返回的行数
语法解析器 : Mysql通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用mysql语法规则验证和解析查询。 如:验证是否使用错误的关键字,或者使用关键字的顺序是否正确等。或者它还会验证引号是否能前后正确匹配。
预处理器 :根据一些MySQL规则进一步检查解析树是否合法。如:检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。
查询优化器:使用基于成本的优化器,尝试预测一个查询使用某个执行计划的成本,并选择成本最小的一个。
使用很多优化策略来生成一个最优的执行计划,优化策略可以简单地分为,一种静态优化,一种动态优化。
静态优化可以直接对解析树进行分析,并完成优化。静态优化不依赖特别的值,如where条件带入的一些常数等。
动态优化则和查询的上下文有关。跟其他因素有关,如WHERE条件中的取值,索引中条目对应的数据行数等。
MySQL能够处理的优化类型:
1、重新定义关联表的顺序
优化器不总是按查询中指定的顺序。
2、将外连接转化成内连接
不是所有的outer join语句都必须以外连接执行。
where条件、库表结构都可能会让外连接等价于一个内连接。
3、使用等价变换规则
使用一些等价变换来简化并规范表达式。如:(5=5 AND a>5)被改成 a>5..如果有(a<b AND b=c) AND a=5 则会改写为
b>5 AND b=c AND a=5.。
4、优化COUNT()/MIN()和MAX()
如,要找到某一列的最小值,只需要查询对应B-Tree索引最左端的记录,mysql可以直接获取索引的第一行记录。
如果要找到一个最大值,也只需读取B-Tree索引的最后一条记录。/5、预估并转化为常数表达式
5、预估并转化为 常数表达式。
检测到一个表达式可以转化为常数 的时候,就会 把该表达式作为常数处理。
二、索引
对于非常小的表,大部分情况下简单的全表扫描更高效。对于中到大型的表,索引就非常有效。
B-Tree索引
使用B-Tree数据结构来存储数据,索引类型大多数指的是B-Tree索引。
除了Archive引擎不支持这种索引,其他大多数都支持。
B-Tree所有的值按照顺序存储,每一个叶子页到根的 距离相同。
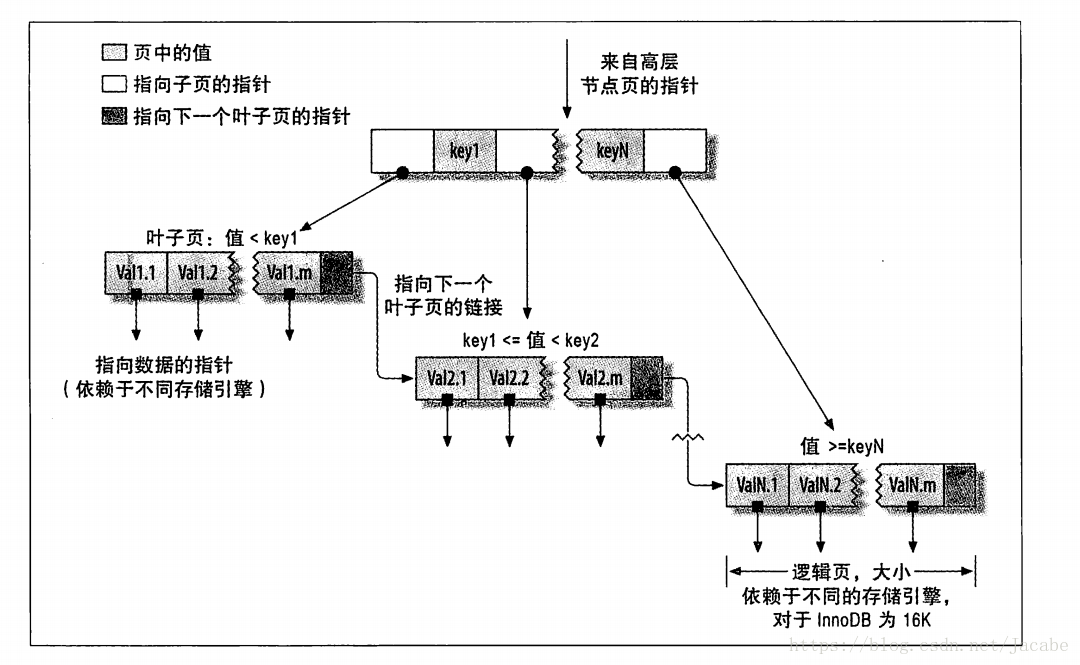
InnoDB索引工作流程
B-Tree索引能够快速访问数据, 因为存储引擎不再需要 进行全表扫描来获取需要的数据,而是从索引的根节点开始进行搜索,根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点。最终存储一起拿要么找到对应值,要么记录不存在。

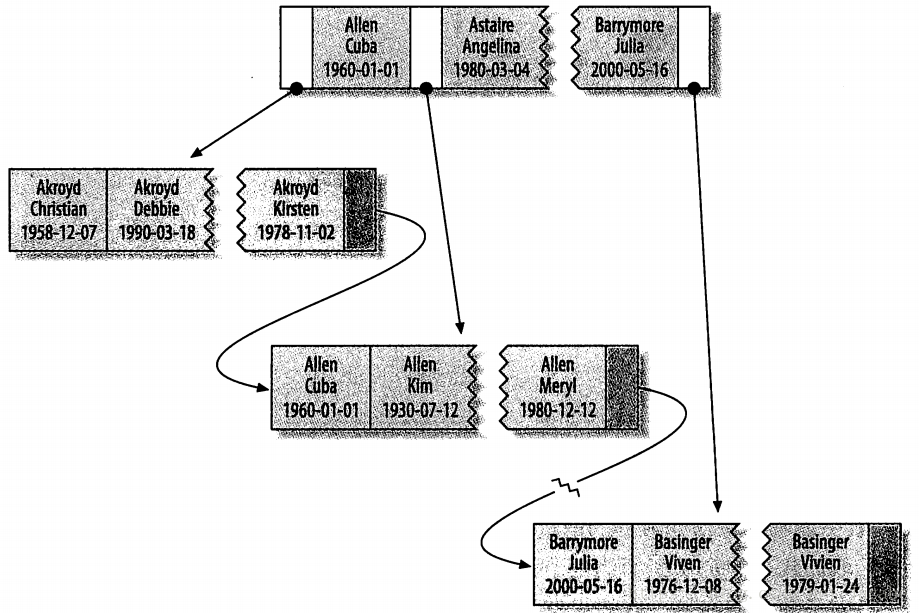
B-Tree索引组织数据存储
B-Tree对索引列时顺序组织存储的,进行排序的依据是CREATE TABLE 语句中定义索引时列的顺序。
看一下最后两个条目,两个人的姓和名都一样,则根据他们的出生日期来排序。
B-Tree索引适用于全键值、键值范围或键前缀查找。
其中键前缀查找只适用于根据最左前缀的查找。
前面的索引对以下类型的查询有效:
全值匹配 : 是和索引中的所有列进行匹配,
匹配最左前缀 : 用于查找所有姓为Allen的人,即只使用索引的第一列。
匹配列前缀: 只匹配某一列的值的开头部分。如:可用于查找所有以J开头的姓的人。
匹配范围值: 可用于查找姓在Allen和Barraymore之间的人。
精确匹配某一列并范围匹配另外一列: 可用于查找所有姓为Allen,并且名字是字母K开头(如:Kim,Karl等)的人,
即第一列last_name全匹配,第二列first_name范围匹配。
只访问索引的 查询:查询只需要访问索引,不需要访问数据行。
B-Tree索引限制:
1、索引不是最左列查找,则无法使用,如:无法查找某个特定生日的人,不是最左数据列。
如果不指定(first_name),就无法查找姓为Smith并且在某个特定日期出生的人。 否则mysql只能使用索引的第一列。
2、如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
例如:有查询WHERE last_name='Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23',这个查询只能使用索引的前两列,因为这个LIKE是一个范围条件。
哈希索引
哈希索引基于哈希表的实现,只有精确匹配索引所有列的查询才有效。
哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
只有memory引擎显示支持哈希索引,是memory引擎默认索引类型。memory引擎也支持B-Tree索引,支持非唯一哈希索引。
索引策略
前缀索引 :对于BLOB/TEXT或者VARCHAR类型的列,必须使用前缀索引,因为Mysql不允许索引这些列的完整长度。
诀窍 选择足够长的前缀保证较高的选择性,接近于完整列,使得前缀索引的选择性接近于索引整个列。
多列索引:为每个列创建独立的索引。是非常错误的,比真正最优得到索引可能差几个数量级。
忽略掉where子句,集中精力优化索引列的顺序,或者创建一个全覆盖索引。
在多个列上建立独立的单列索引大部分情况下并不能提高MySQL的查询性能。
MySQL和以上版本引入“索引合并”的策略,一定程度上可以使用表上的多个单列索引来定位指定的行。老版本只能使用其中一个单列索引。
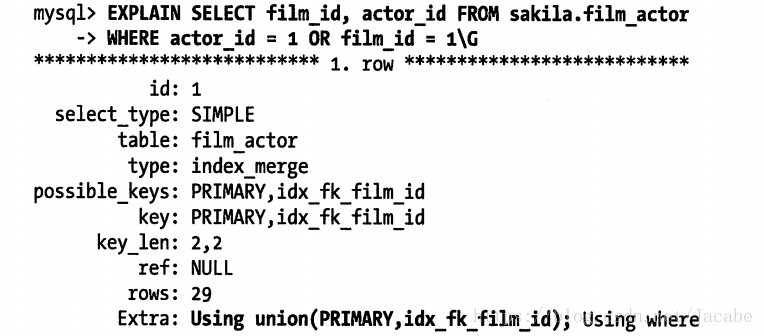
表file_actor在字段film_id和actor_id上各有一个单列索引。
SELECT film_id,actor_id from sakila.film_actor where actor_id = 1 OR film_id = 1;
在老版本中会全表扫描,除非改成:
SELECT film_id,actor_id from sakila.film_actor where actor_id = 1
UNION ALL
SELECT film_id,actor_id from sakila.film_actor where film_id = 1 and actor_id <>1;
, 在MYSQL5.0和以上版本中,查询能够使用者两个单列索引扫描并进行合并。(需要合并,说明索引建的很槽)
索引联合消耗了大量的CPU和内存资源。
如果在EXPLAIN中看到有索引合并,应该好好检查一下查询和表的结构。看是不是已经是最优的。
也可以通过参数optimizer_switch来关闭索引合并功能。也可以使用IGNORE INDEX提示让优化器忽略掉某些索引。
这算法的三个变种:OR条件的联合(union),AND条件的相交(intersection),组合前两种情况的联合及相交。
下面就体现了,使用了两个索引扫描的联合:--》
选择合适的索引列顺序:在一个多列B-Tree索引中,索引列的顺序以为者索引首先按照最左列进行排序,其次是第二列
将选择性最高的列放在最前面
参考mysql书籍的示例:






聚族索引:InnoDB的聚族索引保存了B-Tree索引和数据行,聚族索引不是一种单独的索引类型,而是一种数据存储方式。
术语“聚族”表示数据行和相邻的键值紧凑地存储在一起。数据行存放在索引的叶子页中。
聚族索引的记录存放方式:叶子页包含了行的全部数据,节点页只包含了索引列。下面就是索引列包含的是整数值
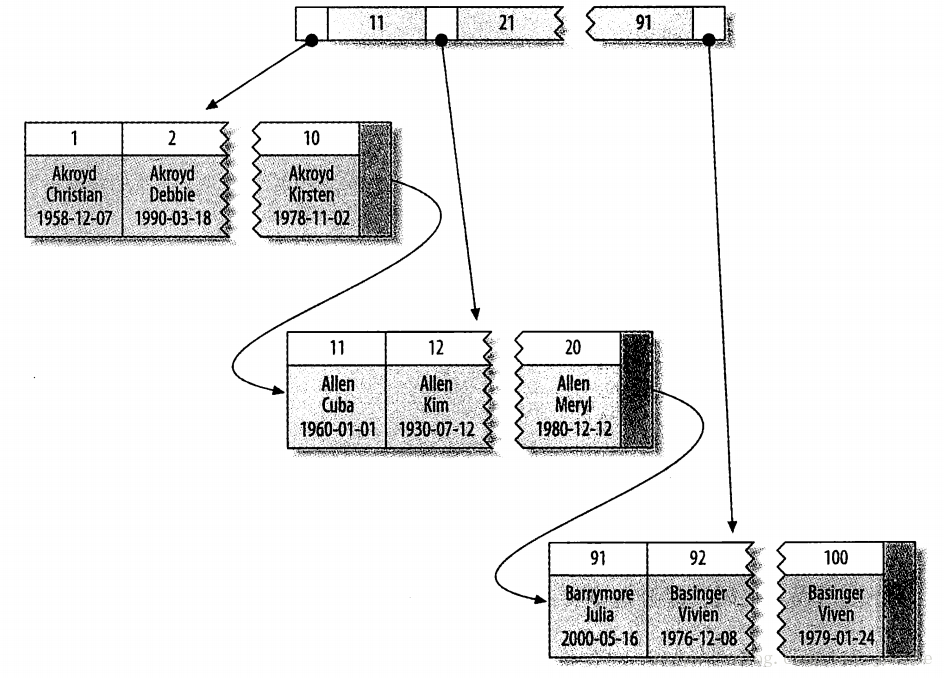
InnoDB将通过主键聚集数据,也就是图上的被索引的列就是主键列。
冗余和重复索引:重复索引指在相同的列上按照相同的顺序创建相同的类型的索引。如下面
CREATE TABLE test(
ID INT NOT NULL PRIMARY KEY,
A INT NOT NULL,
UNIQUE(ID),
INDEX(ID)
) ENGINE = INNODB;
如果创建了索引(A,B),再创建索引(A)就是冗余索引,索引(A,B)也可以当作索引(A)来使用。但是如果再创建索引(B,A),则不是冗余索引,索引(B)也不是,因为B不是索引(A,B)的最左前缀列。还有一种情况把一个索引扩展为(A,ID),其中ID是主键,对于InnoDB来说主键列已经包含在二级索引中,所以也是冗余的。应该尽量扩展已有的索引而不是创建新索引。