Zhang, D., Hu, Y., Ye, J., Li, X., & He, X. (2012, June). Matrix completion by truncated nuclear norm regularization. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2192-2199. 本文是这篇 CVPR 会议论文的笔记,主要是对文中的理论方法进行展开详解。本人学术水平有限,文中如有错误之处,敬请指正。 另外:这篇会议论文于 2013 年发表于 PAMI 期刊上,两篇 paper 的内容基本一致。 IEEE Transactions on Pattern Analysis and Machine Intelligence , 35(9), 2117-2130.
摘要:估计视觉图像中缺失的值是计算机视觉中有挑战的问题,其可以被认为是一个低秩的近似问题。大部分的研究都是用核范数来代替秩操作。然而,在核范数最小化过程中,所有的奇异值一起被最小化,在实际中秩不能被很好地近似。此文提出了一种 Truncated Nuclear Norm Regularization (TNNR) 方法,只最小化较小的
N − r 个部分奇异值,其中
N 是奇异值的总个数,
r 是矩阵的秩。这样可以更好地近似矩阵的秩。此文更设计了两种高效的优化算法,alternating direction method of multipliers (ADMM) 和 accelerated proximal gradient line search (APGL) 方法。
1 简介
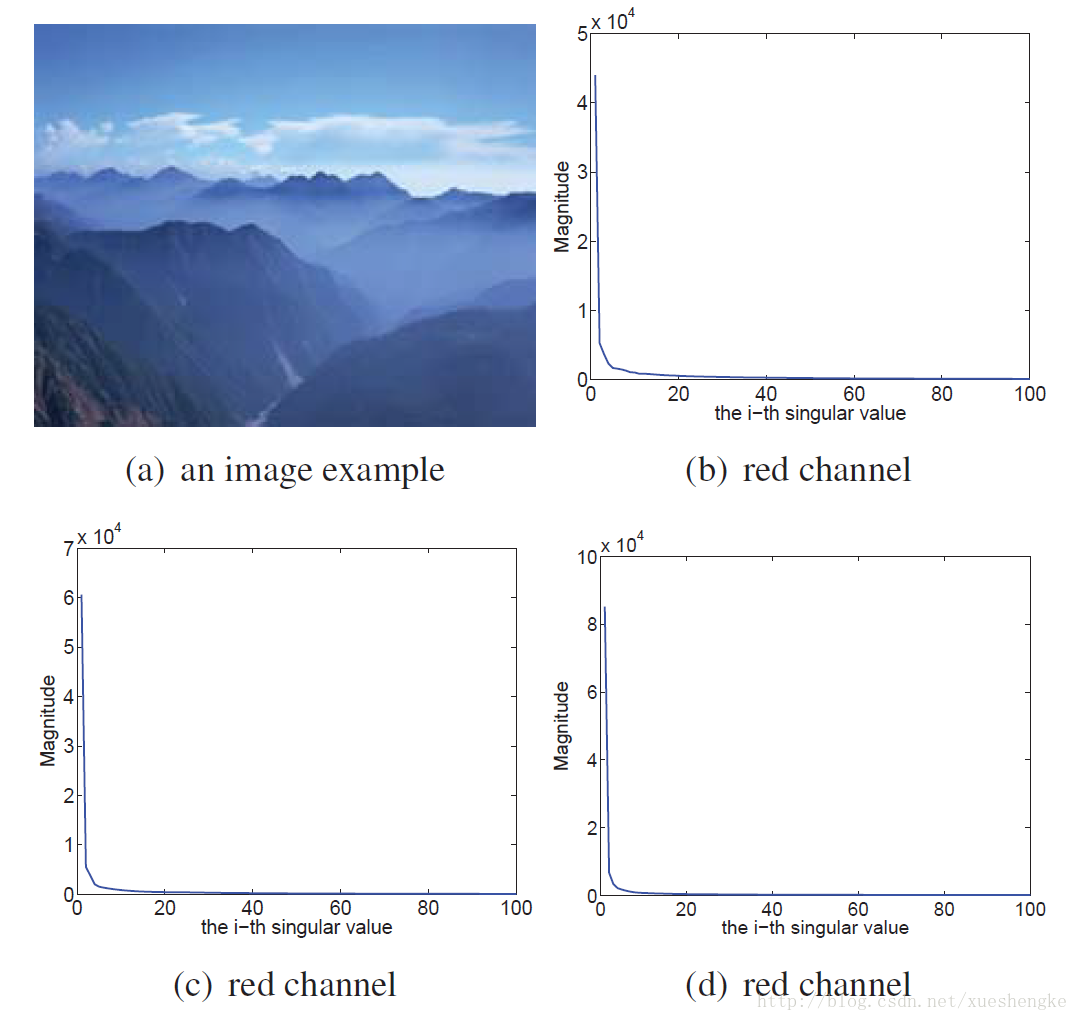
在许多的实际的计算视觉和模式识别中,比如图像恢复,数据中有丢失的部分。估计这些矩阵中丢失值得问题,即矩阵补全,已经受到了相当多的关注。视觉数据,,比如图像,有可能是低秩的,如图所示。于是,大部分的矩阵补全问题都旨在找到一个低秩的近似问题。具体的,给定一个不完整的数据
M ∈ R m × n ,矩阵补全问题可被阐述为
min X s.t. rank ( X ) X i j = M i j , ( i , j ) ∈ Ω , (1)
其中
X ∈ R m × n
,
Ω
是已知的元素的对应的位置集合。
然而, 以上的秩最小化问题是 NP-hard,因为其非凸性和不连续性。一种广泛采用的方法是核范数,即奇异值之和,作为一个凸的代替方法。受压缩感知的启发, Cand
e ` s 和 Recht 最近提出,如果矩阵的行空间和列空间是与标准基不一致的,那么核范数最小化可以恢复出矩阵,如果有足够的已知的元素。
已有的核范数方法,比如 singular value thresholding (SVT ),能够在无噪声的合成数据中获得较好的表现。然而,它们在真实的应用中不能得到低秩的解。这是因为核范数不能精确地近似秩函数。具体地,对比秩函数来说,所有的非零的奇异值都被平等处理,核范数则并不是。更差的是,这些方法优势甚至不收敛。因为核范数的理论的要求(比如不一致的性质)在实际中很难被满足。
此文提出了一种新的矩阵补全的方法,truncated nuclear norm regularization (TNNR),来恢复矩阵中一些缺失的数据。于一般核范数的方法不同的是,并不是同时最小化所有奇异值的和,此文的方法仅最小化较小的
min ( m , n ) − r 个奇异值。这样,该方法可以获得一个更精确、鲁棒性的对秩函数的近似。此外,此文提出了两种简单的,高效的优化机制解决目标函数,即 alternating direction method of multipliers (ADMM) 和 accelerated proximal gradient line search method (APGL) 。
2 相关工作
稀疏表示,低秩矩阵分解相关,略
3 Truncated Nuclear Norm Regularization
令
X = ( x , ⋯ , x n ) 成为一个
m × n 矩阵,
Ω ⊂ { 1 , ⋯ , m } × { 1 , ⋯ , n } 表示矩阵
X 中已知元素的索引,
Ω c 表示缺失元素的索引。可以方便的表示已知的元素
( X Ω ) i j = { X i j , 0 , if ( i , j ) ∈ Ω , if ( i , j ) ∈ Ω c . (2)
正如之前描述的,核范数不能确保很好的近似秩函数在实际中。首先介绍一个定义
定义 3.1 给定一个矩阵
X ∈ R m × n
,truncated nuclear norm
| | X | | r
定义为最小的
min ( m , n ) − r
个奇异值之和,也就是
| | X | | r = ∑ min ( m , n ) i = r + 1 σ i ( X )
。于是,目标函数可以写为
min X s.t. | | X | | r X Ω = M Ω . (3)
明显与传统的核范数不同,求解该问题一直可以得到低秩解,只要其存在。由于
| | X | | r
是非凸的,不容易直接求解。于是,有如下的定义。
Theorem 3.1 对于给定的矩阵
X ∈ R m × n
,
A ∈ R m × m
,
B ∈ R m × n
,和
A A T = I , B B T = I
。对于正的整数
r ≤ min ( m , n )
,我们有
tr ( A X B T ) ≤ ∑ i = 1 r σ i ( X ) . (4)
证明 根据 Von Neumann 迹不等式,我们得到
tr ( A X B T ) = tr ( X B T A ) ≤ ∑ i = 1 min ( m , n ) σ i ( X ) σ i ( B T A ) , (5)
其中
σ 1 ( X ) ≥ ⋯ ≥ σ min ( m , n ) ( X ) ≥ 0
。由于
rank ( A ) = r
,
rank ( B ) = r
,所以有
rank ( B T A ) = s ≤ r
。对于
i ≤ s
,
σ i ( B T A ) > 0
和
σ 2 i ( B T A )
是矩阵
B T A A T B = B T B
的第
i
个特征值,也是
B T B = I
的一个特征值。所以
σ i ( B T A ) = 1
,对
i = 1 , 2 , ⋯ , r
,其余的都是
0
。
∑ i = 1 min ( m , n ) σ i ( X ) σ i ( B T A ) = ∑ i = 1 s σ i ( X ) σ i ( B T A ) + ∑ i = s + 1 min ( m , n ) σ i ( X ) σ i ( B T A ) = ∑ i = 1 s σ i ( X ) ⋅ 1 + ∑ i = s + 1 min ( m , n ) σ i ( X ) ⋅ 0 = ∑ i = 1 s σ i ( X ) . (6)
因为
s ≤ r
和
σ i ( X ) > 0
,
∑ s i = 1 σ i ( X ) ≤ ∑ r i = 1 σ i ( X )
。结合上述不等式,可以证明得到
tr ( A X B T ) ≤ ∑ i = 1 s σ i ( X ) ≤ ∑ i = 1 r σ i ( X ) . (7)
假设
U Σ V T
是矩阵
X
的奇异值分解,其中
U = ( u 1 , ⋯ , u m ) ∈ R m × m
,
Σ ∈ R m × n
,和
V = ( v 1 , ⋯ , v n ) ∈ R n × n
。那么有如下
A = ( u 1 , ⋯ , u r ) T , B = ( v 1 , ⋯ , v r ) T . (8)
因为
tr ( ( u 1 , ⋯ , u r ) T X ( v 1 , ⋯ , v r ) ) = tr ( ( u 1 , ⋯ , u r ) T U Σ V T ( v 1 , ⋯ , v r ) ) = tr ( ( ( u 1 , ⋯ , u r ) T U ) Σ ( V T ( v 1 , ⋯ , v r ) ) ) = tr ( diag ( σ 1 ( X ) , ⋯ , σ r ( X ) , 0 , ⋯ , 0 ) ) = ∑ i = 1 r σ i ( X ) . (9)
结合上述公式,可以得到
max A A T = B B T = I tr ( A X B T ) = ∑ i = 1 r σ i ( X ) . (10)
接着有
| | X | | ∗ − max A A T = B B T = I tr ( A X B T ) = ∑ i = 1 min ( m , n ) σ i ( X ) − ∑ i = 1 r σ i ( X ) = | | X | | r . (11)
于是,优化问题可以被重写为
min X s.t. | | X | | ∗ − max A A T = B B T = I tr ( A X B T ) X Ω = M Ω , (12)
其中
A ∈ R r × m
,
B ∈ R r × n
。基于此,此文设计一个简单但是有效的迭代机制。令
X 1 = M Ω
为初始化,在第
ℓ
次迭代中,首先固定
X ℓ
,计算
A ℓ
和
B ℓ
,借由
X ℓ
的奇异值分解。接着,固定
A ℓ
和
B ℓ
,更新
X ℓ + 1
通过一个更简单的问题
min X s.t. | | X | | ∗ − tr ( A ℓ X B T ℓ ) X Ω = M Ω , (13)
已知
A ℓ ∈ R r × m
,
B ℓ ∈ R r × n
和观测到的矩阵
M Ω
。算法步骤总结于
Algorithm 1 中。通过反复迭代更新这两步,其可以收敛至局部最小值。
Algorithm 1 TNNR Input: 原始的不完整的矩阵
M Ω , 其中
Ω 是已知元素的对应的位置,容限
ϵ 。 Initialize:
X 1 = M Ω 。 repeat
Step 1 给定一个
X ℓ
[ U ℓ , Σ ℓ , V ℓ ] = svd ( X ℓ ) ,
其中
U = ( u 1 , ⋯ , u m ) ∈ R m × m
,
V = ( v 1 , ⋯ , v n ) ∈ R n × n
。
计算
A ℓ
和
B ℓ
如下
A ℓ = ( u 1 , ⋯ , u r ) T , B ℓ = ( v 1 , ⋯ , v r ) T .
Step 2 求解
X ℓ + 1 = arg min X | | X | | ∗ − tr ( A ℓ X B T ℓ ) s.t. X Ω = M Ω .
until
| | X ℓ + 1 − X ℓ | | F ≤ ϵ
Return 恢复的矩阵。
4 优化
需要设计一个有效的优化算法。因为
| | X | | ∗ 和
− tr ( A ℓ X B T ℓ ) 都是凸的,目标函数也是凸的。接下来介绍两种优化机制:増广 Lagrange 乘子法 (ADMM)和加速近似梯度法(APGL)。首先介绍一个非常有用的函数,singular value shrinkage operator :
X ∈ R m × n ,秩为
r ,的奇异值分解
X = U Σ V T , Σ = diag ( { σ i } 1 ≤ i ≤ r ) . (14)
这里定义 singular value shrinkage 操作
D τ ( X ) = U D τ ( Σ ) V T , D τ ( Σ ) = diag ( { σ i − τ } + ) . (15)
对于每一个
τ ≥ 0
和
Y ∈ R m × n
,这里有
D τ ( Y ) = arg min X 1 2 | | X − Y | | 2 F + τ | | X | | ∗ . (16)
4.1 ADMM 优化
将优化目标问题写为
min X , W s.t. | | X | | ∗ − tr ( A ℓ W B T ℓ ) X = W , W Ω = M Ω . (17)
其对应的 Lagrange 函数 可以写为
L ( X , Y , W ) = | | X | | ∗ − tr ( A ℓ W B T ℓ ) + ρ 2 | | X − W | | 2 F + tr ( Y T ( X − W ) ) , (18)
其中
ρ
是一个正的标量。给定初始值,
X 1 = M Ω
,
W 1 = X 1
和
Y 1 = X 1
,优化过程可以分为 3 步:
计算
X k + 1 : 固定
W k
和
Y k
,最小化求解
L ( X , Y k , W k )
X k + 1 = arg min X | | X | | ∗ − tr ( A ℓ W k B T ℓ ) + ρ 2 | | X − W k | | 2 F + tr ( Y T k ( X − W k ) ) . (19)
略去其他常数项,可以化简为
X k + 1 = arg min X | | X | | ∗ + ρ 2 | | X − ( W k − 1 ρ Y k ) | | 2 F . (20)
结合 SVT 操作,可以解得
X k + 1 = D 1 ρ ( W k − 1 ρ Y k ) . (21)
(2) 计算
W k + 1 : 固定
X k + 1 和
Y k ,最小化求解
W k + 1 = arg min W L ( X k + 1 , Y k , W ) 。这是一个二次函数,令其梯度等于
0 ,可以得到
W k + 1 = X k + 1 + 1 ρ ( A T ℓ B ℓ + Y k ) . (22)
固定已知的值,只更新未知部分的值
W k + 1 = ( W k + 1 ) Ω c + M Ω . (23)
(3) 计算
Y k + 1 : 固定
X k + 1 和
W k + 1 ,只需要计算
Y k + 1 = Y k + ρ ( X k + 1 − W k + 1 ) . (24)
全部的优化步骤总结于
Algorithm 2 中。
Algorithm 2: ADMM 优化过程 Input:
A ℓ ,
B ℓ ,
M Ω 和 容限阈值
ϵ 。 Initialize:
X 1 = M Ω ,
W 1 = X 1 ,
Y 1 = X 1 ,
ρ = 1 。 repeat
Step 1:
X k + 1 = D 1 ρ ( W k − 1 ρ Y k ) .
Step 2:
W k + 1 = X k + 1 + 1 ρ ( A T ℓ B ℓ + Y k ) .
W k + 1 = ( W k + 1 ) Ω c + M Ω .
Step 3:
Y k + 1 = Y k + ρ ( X k + 1 − W k + 1 )
.
until
| | X k + 1 − X k | | F ≤ ϵ
.
APGL 优化
实际上,ADMM 是硬约束问题。考虑到实际应用中的有噪声的数据,采用如下的松弛约束问题更有利
min X | | X | | ∗ − tr ( A ℓ X B T ℓ ) + λ 2 | | X Ω − M Ω | | 2 F , (25)
其中
λ > 0
。
APGL 解决如下形式的问题
min X g ( X ) + f ( X ) , (26)
其中
g
是闭的,凸的,可能不可微的函数,
f
是凸的,可微的函数。首先对任意的
t > 0
,APGL方法构建一个
F ( Y )
在固定点
Y
的近似
Q ( X , Y ) = f ( Y ) + ⟨ X − Y , ∇ f ( Y ) ⟩ + 1 2 t | | X − Y | | 2 F + g ( X ) . (27)
APGL 通过迭代优化,更新变量
X
,
Y
和
t
来求解。在第
k
次迭代中,更新
X k + 1
如下
X k + 1 = arg min X Q ( X , Y k ) = arg min X g ( X ) + 1 2 t k | | X − ( Y k − t k ∇ f ( Y k ) ) | | 2 F . (28)
在原优化目标中,令
g ( X ) = | | X | | ∗
和
f ( X ) = − tr ( A ℓ X B T ℓ ) + λ 2 | | X Ω − M Ω | | 2 F
。根据上述定理,可以得到
X k + 1 = arg min X | | X | | ∗ + 1 2 t k | | X − ( Y k − t k ∇ f ( Y k ) ) | | 2 F = D t k ( Y k + t k ( A T ℓ B ℓ − λ ( ( Y k ) Ω − M Ω ) ) ) . (29)
最后,
Y k + 1
和
t k + 1
按如下的方式更新
Y k + 1 t k + 1 = X k + 1 + t k − 1 t k + 1 ( X k + 1 − X k ) , = 1 + 1 + 4 t 2 k − − − − − − √ 2 . (30) (31)
算法步骤总结于
Algorithm 3 中。由于松弛了硬约束
X Ω = M Ω
,
Algorithm 3 更适合于处理噪声数据。另外,
Algorithm 3 中有非常快的收敛速度
O ( 1 k 2 )
。
Algorithm 3: APGL 优化过程 Input:
A ℓ ,
B ℓ ,
M Ω 和 容限阈值
ϵ 。 Initialize:
t 1 = 1 ,
X 1 = M Ω ,
Y 1 = X 1 。 repeat
Step 1:
X k + 1 = D t k ( Y k + t k ( A T ℓ B ℓ − λ ( ( Y k ) Ω − M Ω ) ) ) .
Step 2:
t k + 1 = 1 + 1 + 4 t 2 k √ 2 .
Step 3:
Y k + 1 = X k + 1 + t k − 1 t k + 1 ( X k + 1 − X k ) . until
| | X k + 1 − X k | | F ≤ ϵ .
5 实验
此算法可以对图像中确实的部分像素值进行补全,需要知道的条件除了残缺的图像之外,还需要知道确实部分的位置信息,即每一个像素的在图像中的坐标索引。
r ,i.e. 截取的奇异值的个数,如何选择。不同的图像对
r 的选择是不同的,在没有先验知识的情况下,只能通过设定一个范围
[ 1 , 30 ] 手动搜索最优值。另外,对于此文的两种优化方法,可以发现 APGL 明显在速度上有极大的优势,对于 ADMM 。
6 结论
此文提出了一种新的 Truncated Nuclear Norm Regularization 方法,用于估计图像中缺失的部分像素值,也就是矩阵补全问题。与传统的核范数(考虑所有的奇异值)不同,此文的方法只考虑最小的
min ( m , n ) − r 个奇异值,使得该方法能够更好的近似矩阵的秩函数。此文中还介绍了两种优化目标函数的方法,ADMM 和 APGL 。实验设计于合成的数据和真实的数据中,将 TNNR 方法和其他方法进行比较,得出其优势的效果。