Li, S., K. Li and Y. Fu, Self-Taught Low-Rank Coding for Visual Learning. IEEE Transactions on Neural Networks and Learning Systems, 2017. PP(99): p. 1-12.
本文是这篇 Trans. on NNLS 期刊论文的笔记,主要是对文中的理论方法进行展开详解。本人学术水平有限,文中如有错误之处,敬请指正。
摘要: 计算机视觉和机器学习研究中,缺少标签数据是一个常有的挑战。半监督学习和迁移学习,已经被用于应对这种问题,通过使用来自相同领域、或不同领域的,辅助的样本。自我学习是一种特殊的迁移学习,在选择辅助数据上有更少的限制。这已经在视觉学习上有良好的表现。然而,现有的自我学习方法通常忽视了数据的结构信息。此文关注点在建立一个自我学习编码框架,有效地使用丰富的低级的模式信息(提取于辅助领域),为了在目标领域中表示高级的结构信息。通过利用从辅助领域和目标领域学习到的高质量的字典,此方法可以在目标领域学习到样本的表示编码。已经有许多类型的视觉数据被证明有子空间结构,低秩约束加入到目标中,更好地表示目标集。此文提出的表示学习框架称为自学习低秩编码(self-taught low-rank (S-Low) coding),可以建模为一个非凸的秩最小化和字典学习的问题。此文也使用,最小化的増广 Lagrange 乘子法。根据提出的编码框架,同时推导出了非监督和有监督的算法。
1 简介
好的特征是能表达出来的,是一个合理大小的字典,可以捕获到大量输入数据,表征一个给予的数据集的全局结构。然而,缺少训练数据使得特征学习变得非常复杂。
半监督学习利用一些带标签的样本和大量无标签的样本,它们来自相同的领域,有相同的分布,去训练模型。半监督学习还是有局限性。迁移学习中,限制被放松了。其中,标签样本和辅助样本来自不同的集合,有不同的分布。但是迁移学习中,要求两个领域是相似的。许多的迁移学习算法假设两个领域都有相似的知识结构。所以,半监督学习和迁移学习在辅助(源)数据上都有强约束条件,限制了其应用。最近出现的机器学习模型——自我学习(STL)1 2 3 4 5,使用无标签数据,带有很少的约束,提升了图像聚类和分类的性能。
自我学习和迁移学习是两个相关的概念。关键的差异是它们在辅助领域的约束不同。具体来说,迁移学习只利用同类的任务的标签数据,而自我学习(更宽松)利用来自辅助领域的随机图像。简单来说,自我学习随机从辅助领域选择的视觉数据,仍可以包含一些基本的视觉模式(边缘、角、形状),与目标领域的特征极其相似。这灵活性使得自我学习特别有潜力适用大量的无标签的数据。现有的一些自我学习方法,忽视了目标领域中的结构信息(这个在图像分类中很重要)。
此文提出了一种新的自我学习低秩编码(S-Low coding)框架。通过利用从辅助领域中提取的高质量的字典,可以学习在目标领域中的高级表示。由于许多视觉数据可以很好地用子空间结构表示 6 7,此文介绍了一种低秩约束,利用目标领域中的全局结构信息。此文的方法可以适用于许多应用:目标检测、场景分类、人脸识别、图像聚类。特别当目标数据很少时,此方法仍可以提取有效地特征表示,借助辅助领域中的大规模的无标签数据。同时,低秩约束能够移除噪声或异常点 8 9 10 。
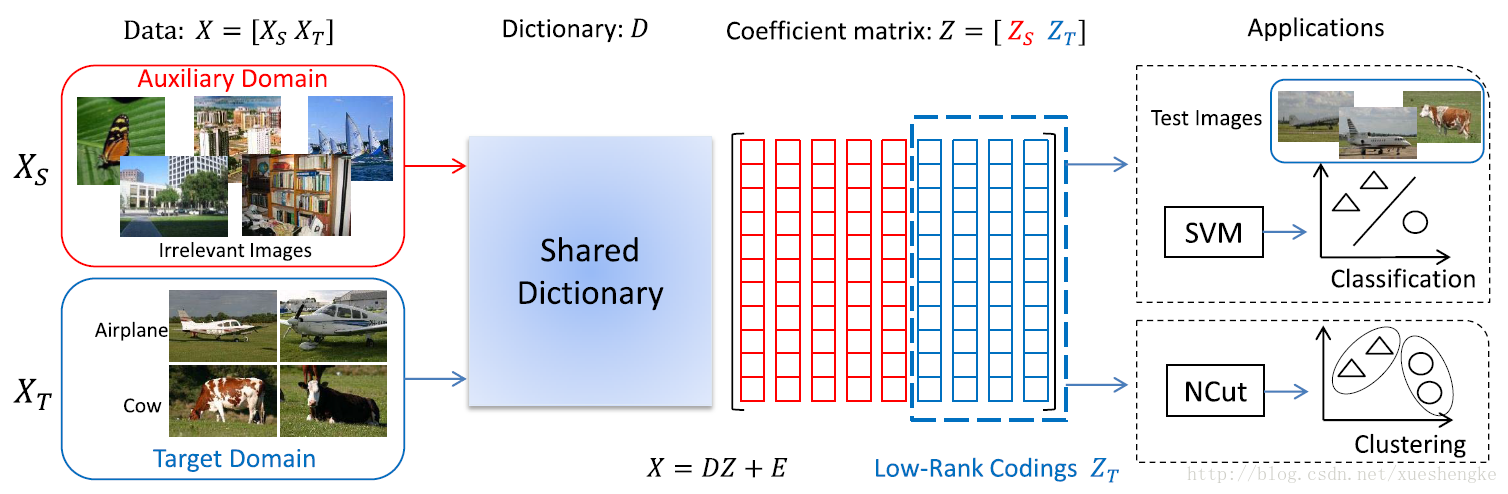
自我学习低秩编码(S-Low coding)流程。较少的目标数据集
此文提出的方法可以解决一些现有方法的限制。首先,现有的方法给特定的应用设计算法。而此文提出的方法可以被用于监督和非监督的任务。其次,现有的自我学习方法仅仅从目标领域中学习新的特征,却忽视了重要的全局的结构信息。此文的方法可以利用从辅助领域提取的低级的模式信息,来表示目标领域中的高级的结构信息。
此文的主要贡献有:
有了辅助领域的大量的模式信息,S-Low 编码方法可以更好地学习到特征表示,在目标领域中加入低秩约束。
此文提出的方式是一个通用的框架,可以用于多种视觉学习场景。此文给出了非监督学习和监督学习的详细的算法。
不像其他 LRR 算法(使用有偏估计,
ℓ1 范数和核范数),此文将ℓ0 范数核 rank 函数替换成最小最大凹惩罚范数(minimax concave penalty norm, MCP)和矩阵γ 范数,这是无偏估计的。我们设计了最小化优化算法,并经验性地给出了其收敛性质。
2 相关工作
略
3 自学习低秩编码
3.1 动机
略
3.2 优化算法
考虑无标签样本
传统的稀疏编码 13,字典学习 14,低秩学习 15 方法近似表达样本在一个域中
其中
首先,此方法可以从两个领域中的所有样本中学习字典。数据集
其次,在许多的聚类和分类的问题中,目标领域中的样本通常有隐含的子空间结构。研究表明,使用低秩约束,可以有效地发现潜在的子空间结构。利用这子空间结构信息对学习过程很有利。根据观察,将约束加于
其中
矩阵
其中
字典从辅助领域和目标领域一起学习到,为了学习到有用的信息。公式中的两个约束都共用一个字典
其中
3.3 优化
此文使用优化最小化增广拉格朗日乘子(MM-ALM)算法(majorization–minimization augmented Lagrange multiplier, MM-ALM)求解。首先介绍通用的 shrinkage 操作和 singular value shrinkage 操作,
其中
MM-ALM 算法包含内循环和外循环。每一次迭代中,外循环使用局部线性近似(locally linear approximation, LLA)处理原始的非凸问题,并组成一个加权的凸优化问题;在内循环中,采用 inexact ALM 算法。
在外循环中,需要重写目标函数。因为原目标函数关于
其中一阶近似项表达为
在内循环中,采用 inexact ALM 算法进行优化。已有初始化过的字典
其中
之后再更新字典
内循环和外循环重复进行直至收敛。整体的算法于 Algorithm 1 中给出。
Algorithm 1 MM-ALM Algorithm
Input: 数据
1: while not converged do
2:
3:
4: while not converged do
5: 更新
6: 更新
7: 更新
8: 更新
9: 更新
10: 更新
11: 更新
12: 检查收敛条件
13:
14: end while
15: 更新
16:
17: end while
Output:
3.4 分析
此文提出的算法有局部的收敛性:当字典
在初始化时,字典
时间复杂度:假设
4 S-Low 编码学习
S-Low 聚类
有了无标签的数据集
另一方面,稀疏性在图构建过程中也是强调的,所以通过修剪一些小的权值使其变得更稀疏。最后,有效的聚类算法,比如 normalized cuts (NCuts) 用于给出聚类的结果。
S-Low 分类
当目标领域中的样本标签都已知,可以设计一个分类算法基于 S-Low 编码,训练一个分类器。有了字典
其中
实验
略
- R. Raina, A. Battle, H. Lee, B. Packer, and A. Y. Ng, “Self-taught learning: Transfer learning from unlabeled data,” in Proc. 24th Int. Conf. Mach. Learn., 2007, pp. 759–766. ↩
- W. Dai, Q. Yang, G.-R. Xue, and Y. Yu, “Self-taught clustering,” in Proc. 25th Int. Conf. Mach. Learn., 2008, pp. 200–207. ↩
- R. Raina, “Self-taught learning,” Ph.D. dissertation, Dept. Comput. Sci. Stanford Univ., Stanford, CA, USA, 2009. ↩
- H. Wang, F. Nie, and H. Huang, “Robust and discriminative self-taught learning,” in Proc. 30th Int. Conf. Mach. Learn., 2013, pp. 298–306. ↩
- J. Kuen, K. M. Lim, and C. P. Lee, “Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle,” Pattern Recognit., vol. 48, no. 10, pp. 2964–2982, Oct. 2015. ↩
- G. Liu, Z. Lin, S. Yan, J. Sun, Y. Yu, and Y. Ma, “Robust recovery of subspace structures by low-rank representation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 1, pp. 171–184, Jan. 2013. ↩
- J. Wright, A. Y. Yang, A. Ganesh, S. S. Sastry, and Y. Ma, “Robust face recognition via sparse representation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 2, pp. 210–227, Feb. 2009. ↩
- E. J. Candès, X. Li, Y. Ma, and J. Wright, “Robust principal component analysis?” J. ACM, vol. 58, no. 3, p. 11, May 2011. ↩
- G. Liu, H. Xu, and S. Yan, “Exact subspace segmentation and outlier detection by low-rank representation,” J. Mach. Learn. Res.-Proc. Track, vol. 22, pp. 703–711, 2012. ↩
- S. Li, M. Shao, and Y. Fu, “Locality linear fitting one-class SVM with low-rank constraints for outlier detection,” in Proc. Int. Joint Conf. Neural Netw., Jul. 2014, pp. 676–683. ↩
- R. Raina, A. Battle, H. Lee, B. Packer, and A. Y. Ng, “Self-taught learning: Transfer learning from unlabeled data,” in Proc. 24th Int. Conf. Mach. Learn., 2007, pp. 759–766. ↩
- H. Wang, F. Nie, and H. Huang, “Robust and discriminative self-taught learning,” in Proc. 30th Int. Conf. Mach. Learn., 2013, pp. 298–306. ↩
- J. Wright, A. Y. Yang, A. Ganesh, S. S. Sastry, and Y. Ma, “Robust face recognition via sparse representation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 2, pp. 210–227, Feb. 2009. ↩
- L. Ma, C. Wang, B. Xiao, and W. Zhou, “Sparse representation for face recognition based on discriminative low-rank dictionary learning,” in Proc. 25th IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2012, pp. 2586–2593. ↩
- G. Liu, Z. Lin, S. Yan, J. Sun, Y. Yu, and Y. Ma, “Robust recovery of subspace structures by low-rank representation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 1, pp. 171–184, Jan. 2013. ↩
- S. Wang, D. Liu, and Z. Zhang, “Nonconvex relaxation approaches to robust matrix recovery,” in Proc. 23rd Int. Joint Conf. Artif. Intell., 2013, pp. 1764–1770. ↩
- C.-H. Zhang, “Nearly unbiased variable selection under minimax concave penalty,” Ann. Statist., vol. 38, no. 2, pp. 894–942, 2010. ↩
- S. Wang, D. Liu, and Z. Zhang, “Nonconvex relaxation approaches to robust matrix recovery,” in Proc. 23rd Int. Joint Conf. Artif. Intell., 2013, pp. 1764–1770. ↩