在数据挖掘任务中,通过数据样本实际上是可以得到诸多模型的,尽管这些模型都是错误的,但是有的模型是有用的,那么如何去评价哪个模型对本次任务来说是最有用的?在评价模型过程中,需要考虑两个问题,一个是如何获取用于评价模型的数据样本,即测试数据集,另一个是用什么指标来衡量模型的优劣。
1.获取测试数据集
用训练数据建立模型之后总是要考虑它的泛化能力,为此需要使用测试数据来观察模型的泛化能力。在建立模型的时候,数据样本的数量总是有限的,区别在于数据量的大小,这就导致在选择训练数据和测试数据时出现了诸多方法,常用的方法有留出法、交叉验证法、bootstrap方法,下面分别介绍。
1.1 留出法
留出法一般用在样本数据量较大的情况。在使用留出法时,将样本数据分为两部分,一部分为训练集
,另一部分为测试集
,训练集
用来生成模型,测试集
用来评估其测试误差,将其作为对泛化误差的估计,这个思路比较简单,但是数据集
的划分过程需要注意两点:训练集
与测试集
的划分比例、训练集
与测试集
中样本的抽样方式。
训练集与测试集
的划分比例偏大时,由于测试集
中数据样本量少,其包含的样本信息也较少(糟糕的情况是其中还包含了较多噪声,这或许直接导致非常离谱的评估结果),因此其评估结果可能不够准确。即使
中包含了比较准确的样本信息,在换一个同等数量新的测试集时,可能包含的信息就不那么准确,评估结果也可能会有较大差别,故其评估结果不稳定;训练集
与测试集
的划分比例偏小时,由于训练数据包含较少的样本信息,这样得到的模型本身就不可取,这种情况比“训练集
与测试集
的划分比例偏大”更糟糕,之后用测试集
得到的评估结果,已经是失真的了。那该如何选取训练集
与测试集
的划分比例呢?一般选用样本数据集
的2/3~4/5用来训练模型,剩余数据用来测试,测试集
应至少包含30个样本。
对样本数据抽样得到训练集
与测试集
时,一定要注意数据信息分布一致的问题,避免因为抽样问题导致训练集
与测试集
中信息分布不均匀,影响模型的训练与评估。举个例子,对某地区居民生活满意情况进行调查,依据指标(变量){年收入、环境、交通出行、住房}等建立分类模型,判断居民对自己生活是否满意(分为满意、不满意),如果在该地区有一片富人区,富人区的居民全部被抽样到训练集
中,那么用测试集
得到的评估结果就不那么准确,这就是信息不平均的影响,这是采样中该注意的问题。
解决了以上两个问题之后,剩下的就是(在
个样本中选取
个)的问题,此时样本选择仍有多种情况。单次使用留出法得到的评估结果往往不够可靠,一般采用多次随机划分、取评估结果的平均值的方式得到最终的评估结果。
1.2 交叉验证法
交叉验证法中,将样本数据集均分为
等份(注意,这个均分过程仍然要考虑1.1节中提到的信息均匀问题),前
份作为训练集,剩余一份作为测试集,得到测试结果。由于测试集的选择方式有
种,因此在数据集
的一次划分过程中可以得到
个测试结果,将这
个测试结果的平均值返回作为最终结果,这个过程通常称为“
折交叉验证”。当
=10时,交叉验证的过程示意图如下
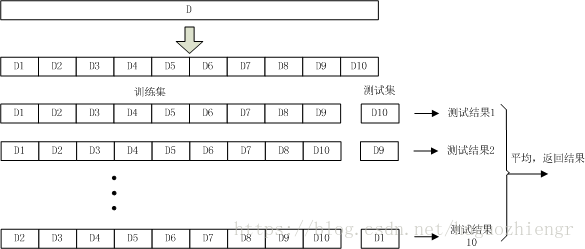
在交叉验证过程中,在确定样本数据集划分份数
时需要考虑1.1节中提到的训练集与测试集比例问题,除此之外,从数据集
中抽样得到每份数据时同样存在
问题,因此一般也会进行多次随机抽样(抽样次数为
),这样在使用交叉验证法时一共会进行
次测试,最终的评估结果是这
次
折交叉验证的结果的平均。
分析交叉验证法和留出法的过程来看,本质上是一样的。折交叉验证的过程可以视作
次留出法的过程,不过要求在这
次留出时,留出的数据间不能有重和,并且
次留出的数据并起来就是样本数据集
。
1.3 bootstrap方法
留出法和交叉验证法都在数据样本中单独划分出了测试集,这样在模型训练时并没有使用全部的样本数据,这在样本数据量充足时并不会产生多大问题,但是在样本数据量较小时可能会导致模型包含信息不充分,产生估计偏差,在这种情况下,bootstrap方法可能是一个比较好的选择。
在实施bootstrap方法时,为了得到训练集(包含
个样本),每次从样本数据集
中随机抽样一个样本放入训练集
中,然后将该抽取的样本放回
中重新进行抽样,重复该过程
次后就得到训练集
,然后将数据集
中除去训练集
后剩下的数据作为测试集,得到测试结果。重复进行多次这样的过程,将所有结果的平均值作为最终结果。
很明显,在bootstrap方法中抽样得到训练集的过程十分关键,抽样过程改变了训练集
及测试集
的分布,这很有可能带来估计偏差,因此在样本数据量充足时,还是选取前两种方法比较合适。
2.性能指标选择
在不同的任务中,应该选择合适的性能指标来衡量模型的优劣。在预测任务中,给定样本集,
是
的真实标记,评估模型
的性能就是要比较
的预测结果与真实标记
之间的差异。
2.1 回归任务
在回归任务中,最常用的指标为均方误差,其定义如下
由于回归任务中为连续取值,因此更一般的定义为
为概率密度函数
2.2 分类任务
2.2.1 错误率与精度
错误率及精度是分类任务中最常用的性能指标,适合于二分类及多分类任务,其定义也比较简单,错误率指错误分类的样本数占总样本数的比例,精度则为1-
。
2.2.2 查准率、查全率
在一些场合下,错误率及精度不足以衡量模型的性能,我们还关心查准率和查全率。比如在建立疾病预测模型时,需要依据人的体温、呼吸等条件预测其是否患有某种疾病,那么我们可能更关心这个模型的查准率,将真正患有疾病的人都预测出来,而不是简单的知道精度是多少,因为这存在健康被诊为患病、患病诊为健康的情况。对于二分类问题,先简单定义一下查准率与查全率
查准率:在所有被标为“正例”的样本中,真正为“正例”的样本比例
查全率:在所有真正为“正例”的样本,被标记为“正例”的样本比例
建立分类结果的混淆矩阵

查准率与查全率
的计算公式为
然而查准率和查全率是一对矛盾的度量,对于很多模型来说二者很难同时达到完美,在对比模型的时候会出现一方查准率高而另一方查全率高的情况,此时该如何抉择呢?在实际应用中一般使用度量指标,它是基于查准率
与查全率
计算出来的,其定义如下
(1)
为样例总数
在一些分类任务中,对查准率与查全率的侧重会有所不同。在商品推荐领域中,会侧重查准率以减少不准确信息对用户的干扰,而在逃犯信息检索领域,会侧重查全率一些,避免有漏网之鱼,为此有了的改进形式——
,其定义形式为
(2)
(3)
从公式(2)容易看出,当时,查全率R的变换对
的影响较大,此时更侧重查全率;当
时,查全率R的变换对
的影响较小,查准率影响相对较大,此时更侧重查准率;当
时,也就没有权重,变成了
的形式。正如第1节中提到的,实际测试过程一般会有多次,此时可以计算多次测试的查准率、查全率结果,然后取其平均值代入公式(1)和公式(3)中计算。
在多分类任务中,假设分类数为,那么我们得到一个
的混淆矩阵,
表示第
类样本被预测为第
类的数量,多分类的混淆矩阵如下所示
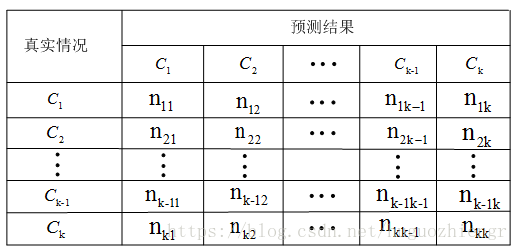
第类的查准率
为
第i类查全率为
那么对于整个模型来说,其查准率与查全率该如何定义呢?我还没有查到相关比较权威的定义,先提一点个人的想法,如果对每一类的分类查准率与查全率没有权重的话,可以各类的查准率与查全率相加,然后计算平均值,再代入公式(1)和公式(3)中计算;如果有权重的话,则将各类的查准率与查全率加以相应权重,然后计算平均值,再代入公式(1)和公式(3)中计算,注意这种情况下会有两次加权,一次是对不同类的加权,一次是对查准率与查全率的加权。