一、需求
题目:实现一个自动生成小学四则运算题目的命令行程序
功能均已经实现:
- 使用 -n 参数控制生成题目的个数
- 使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围
- 生成的题目中计算过程不能产生负数,也就是说算术表达式中如果存在形如e1 − e2的子表达式,那么e1 ≥ e2
- 生成的题目中如果存在形如e1 ÷ e2的子表达式,那么其结果应是真分数
- 每道题目中出现的运算符个数不超过3个
- 程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目
- 在生成题目的同时,计算出所有题目的答案,并存入执行程序的当前目录下的Answers.txt
- 程序应能支持一万道题目的生成
- 程序支持对给定的题目文件和答案文件,判定答案中的对错并进行数量统计,统计结果输出到文件Grade.txt
二、耗费时间估计
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | |
| · Estimate | · 估计这个任务需要多少时间 | 30 | |
| Development | 开发 | 740 | |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | |
| · Design Spec | · 生成设计文档 | 120 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 40 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | |
| · Design | · 具体设计 | 60 | |
| · Coding | · 具体编码 | 30 | |
| · Code Review | · 代码复审 | 120 | |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | |
| Reporting | 报告 | 60 | |
| · Test Report | · 测试报告 | 40 | |
| · Size Measurement | · 计算工作量 | 10 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | |
| 合计 | 1640 |
三、效能分析
对-n 10000 -r 10的分析:
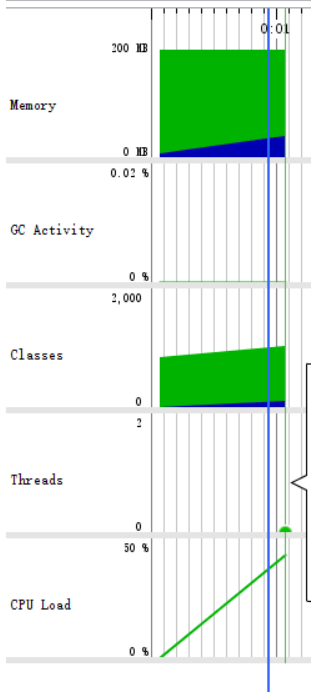
可见生成一万道题目,耗时不到1.1秒,运行时内存消耗为38M,程序运行良好。
我们将题目加大到一百万条,为了减去表达式重复碰撞的影响,我们将r值提高到100,参数为:
-n 1000000 -r 100,结果如下图:
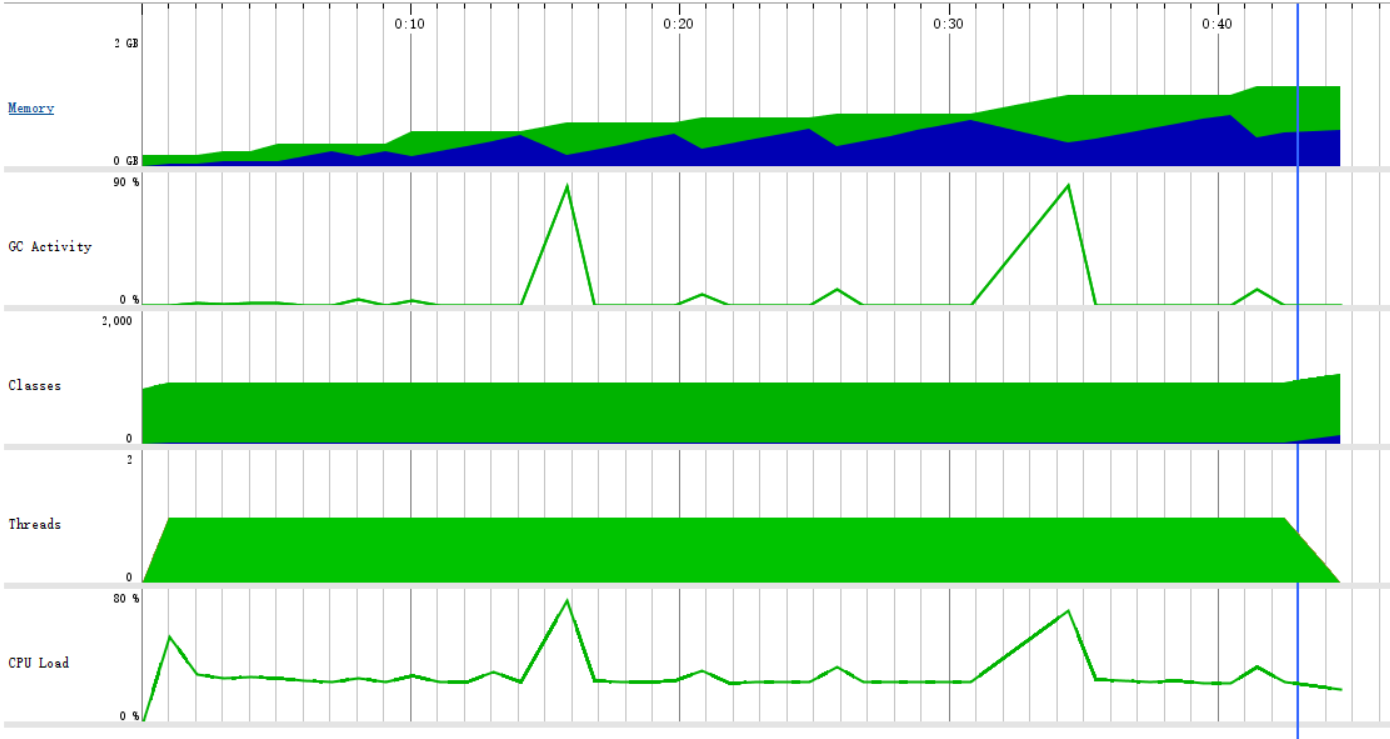
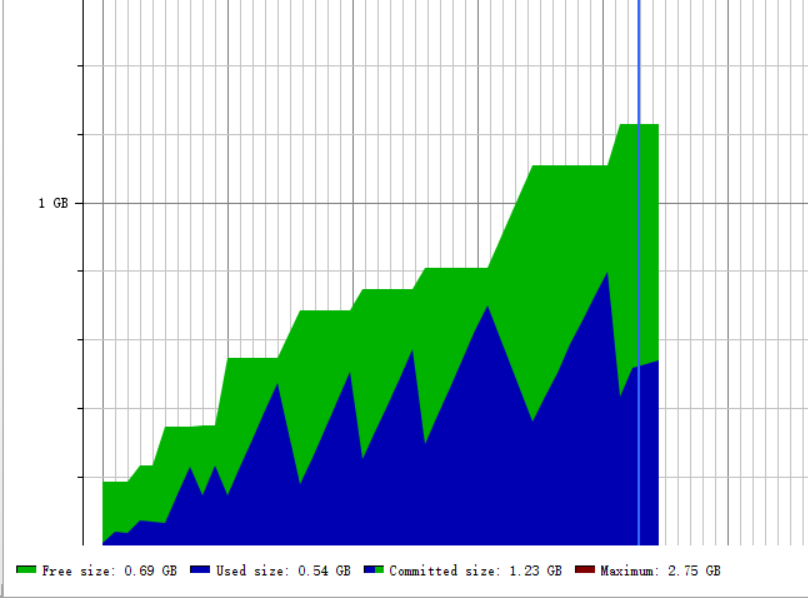
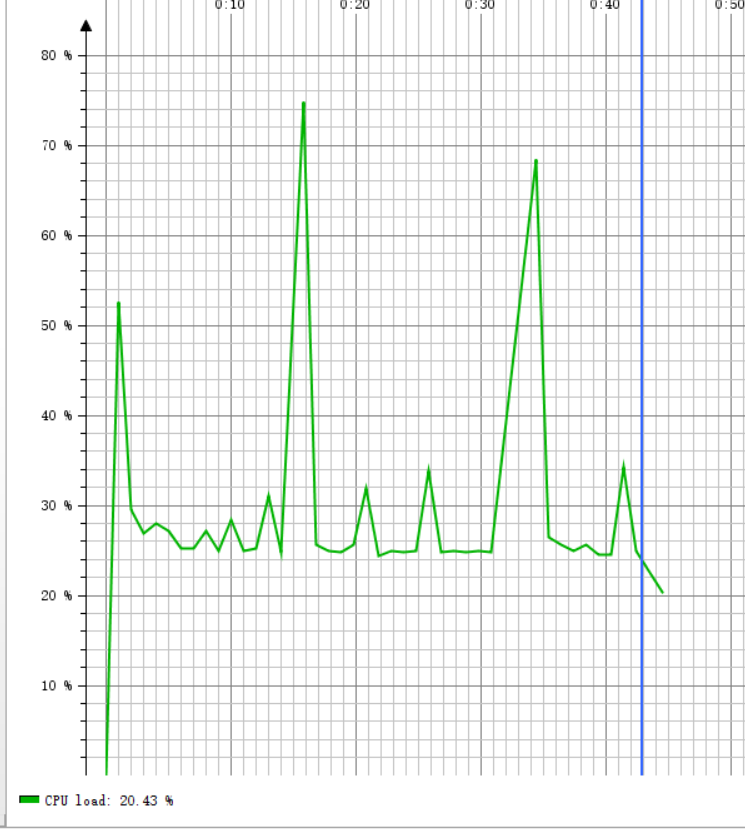
可以看到,这次的运行时间为44秒左右,虽然生成的题目增加了100倍,但是运行时间只增加了40倍左右,运行时内存占用0.54GB,CPU占用为20.43%,当进行GC垃圾回收活动的时候,CPU占用率就会明显升高,可见CPU时间主要消耗在垃圾回收上,这与我们的设计思想有关,我们设计的每个表达式都是一个对象,每个表达式对象里面都有一棵二叉树,每个对象都会占用一部分堆内存,生成一百万道题目就意味着堆内存里面要放一百万个对象,这显然是不可能的,所以需要不断的进行垃圾回收,将使用过的表达式对象所占用的内存回收掉,改进思路是减少表达式对象中不必要的属性,或者将表达式用其他方式而不是一个对象表示,由于时间限制目前还没有进行改进。
看下统计这一百万道题目的答案时的运行情况:
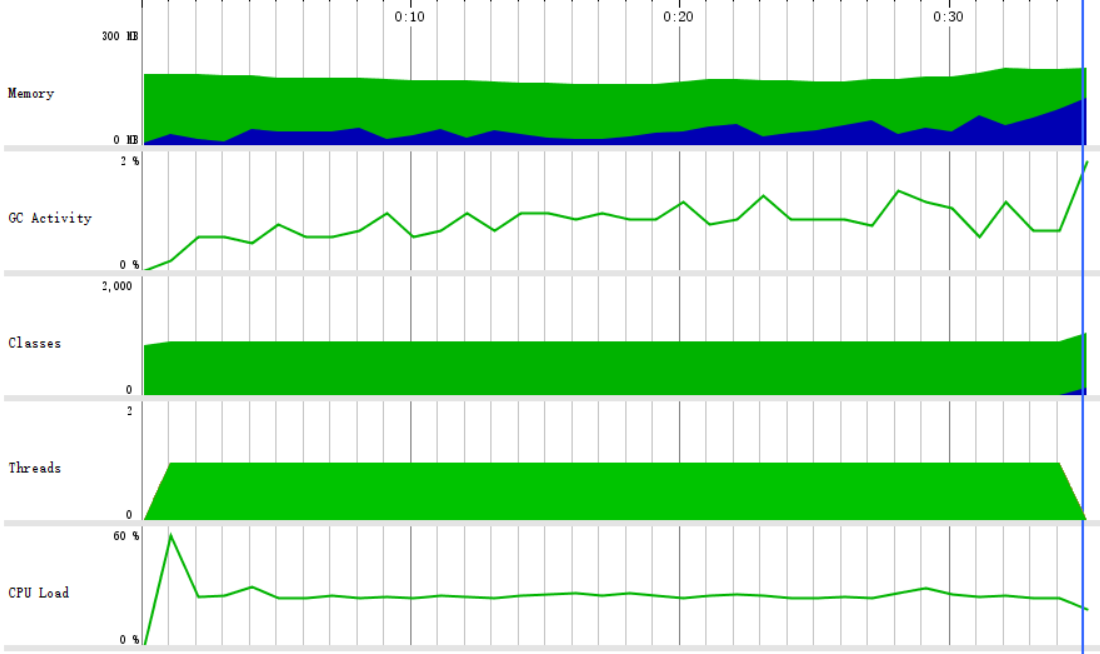
总耗时35秒,内存占用120.3MB,CPU占用18.96%,程序运行良好,统计一百万道表达式的答案的速度比生成一百万道表达式快,我们觉得这是因为不需要进行表达式的判重操作,而且表达式对象不需要放在HashSet中,所以用完可以立即进行垃圾回收,占用的内存也减少了。
四、设计实现过程
1.数值的表示
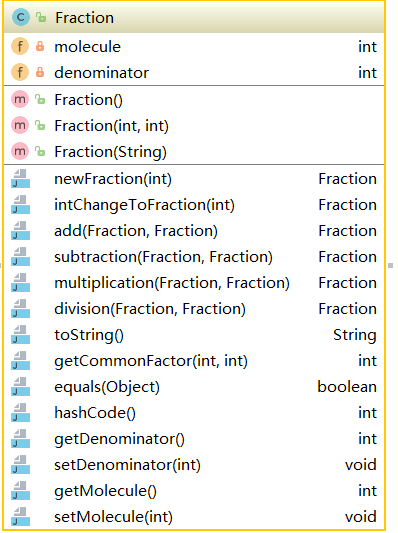
四则运算表达式中要求题目中的数值为自然数或真分数,这里我们设计一个分数类Fraction,将所有数值用分数来表示,这个分数类只有两个属性molecule和denominator,即分子和分母,运算的时候通过分数的分子分母进行运算,所以我们需要一个方法将自然数转化为分数,这个方法是intChangeToFraction(int)。同时,我们还需要一个方法newFraction(int)用来随机生成分数,参数为表达式中数值的最大取值。最后是实现分数的加减乘除操作方法。当需要打印到表达式时,我们重写它的toString()方法,将它用真分数的形式打印出来即可。该类的结构图如下:
2.四则运算表达式的表示
我们平时看到的四则表达式如 a+b+c 是表达式的中缀表示,不方便用于机器计算结果,所以我们使用表达式的后缀表示法(即逆波兰表示法),上面的式子转化逆波兰式为:ab+c+,按照逆波兰表达式的计算方法这个式子可以用二叉树来表示:
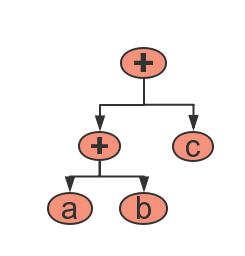
通过二叉树,我们可以对四则运算表达式的结果进行计算,实现对四则运算表达式的判重。
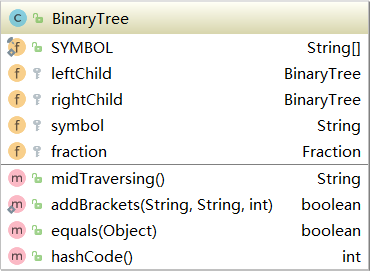
(1)二叉树节点对象BinaryTree
二叉树的每个节点有四个属性:符号symbol、分数fraction以及左右子树节点。如果是叶子节点那么它的symbol为空。中序遍历二叉树的根节点,即可打印出中缀表达式的形式,因此我们需要一个中序遍历的方法:midTraversing()。还有需要注意的是,中序遍历的时候有3种情况需要加括号:
1.当前节点的符号是减号,右子树的节点符号是加号或减号时,表达式右边需要加括号,如式子c-(a+b)的二叉树为:
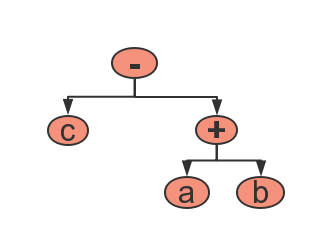
如果不加括号,中序遍历的结果为c-a+b,这样显然不对。我们就是刚开始的时候少考虑了这种情况,忘记加这种情况的括号,导致打印出来的表达式是错误的,和计算结果匹配不上。
2.如果当前节点的符号是乘法,左右子树的节点是加法或减法,左右子树加括号
3.如果当前节点的符号是除法,右子树如果是符号的话都加括号,左子树的符号是加法或减法加括号。
所以这里我们加一个addBrackets()方法判断是否需要加括号。
这个二叉树类的结构如下:
(2)表达式对象Expression
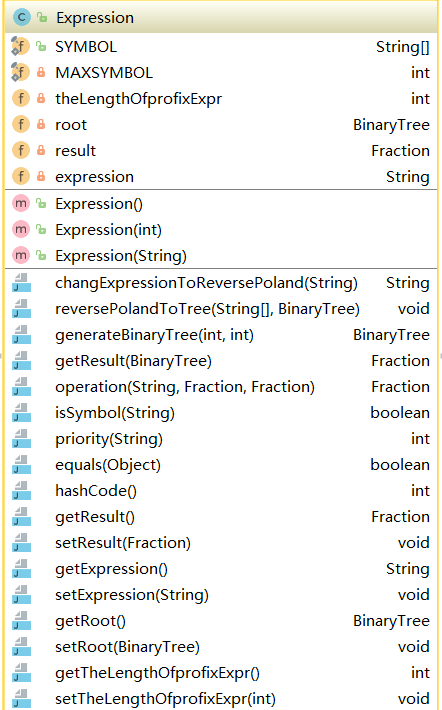
表达式对象的属性有:二叉树对象root、计算结果result、中序遍历二叉树得到的表达式的字符串形式expression。这里我们生成表达式对象有两种情况:
1.-n -r生成题目的时候,随机生成表达式对象,使用构造方法Expression(int):
int 是限制的最大自然数
随机生成表达式,即我们需要随机生成一棵二叉树,实现一个generateBinaryTree(int,int),第一个参数是最大自然数,第二个参数是符号数,给当前节点分配一个随机生成符号,给左子树分配0到(符号数-1)个符号,给右子数分配符号数-1-分配给左子树的符号数个符号;如果符号数为0,则给当前节点随机生成一个分数。
随机生成二叉树后,我们还需要一个getResult(BinaryTree)方法来计算二叉树的节点,这个方法通过左子树的值[+|-|*|÷]右子树的值,遍历得到结果。
2.-e 题目.txt -a answers.txt统计题目和答案的时候,根据表达式的字符串来生成表达式对象,使用构造方法Expression(String):
需要先将中缀表达式转为逆波兰表达式,再将逆波兰表达式生成二叉树,这里用到了2个方法:changeExpressionToReversePoland(String)、reversePolandToTree(String)
将中缀表达式转为逆波兰表达式的思路我参考了博文:算术表达式转成后缀表达式(逆波兰式)并求值
我们约定 ‘*’,‘/’两种运算符的优先级最高,用整数3表示,‘+’,‘-’的运算符的优先级次之,用2表示,‘(’的优 先级最低,用1表示;
具体思想如下:
- 建立一个栈用来保存操作符,初始时为空;
- 从左至右遍历输入的算术表达式;
1) 如果当前字符为操作数,则直接加入到后缀表达式中;
2) 如果当前字符为操作符,当栈为空直接将此操作符加入到栈中,否则就将栈中所有操作符优先级小于当前操作符优先级的操作 符全部加入到后缀表达式中(如果栈不为空且栈顶操作符的优先级大于等于当前操作符的优先级就将栈顶元素出栈并加入后缀表达式中,直到栈为空或栈顶 操作符的优先级小于当前操作符的优先级),最后将当前操作符入栈。
3) 如果当前字符为‘(',直接将其加入操作符栈中;
4) 如果当前字符为‘)’,就将栈顶操作符出栈,直到遇到第一个‘(’为止。(注意,需要将‘(’从操作数 栈中取出但不需要加入到后缀表达式中)。- 读取完毕后,将栈中剩余操作符挨个出栈并加入到后缀表达式中。
至于将逆波兰表达式转为二叉树就很简单了,具体实现在后面的代码中可以看到。
Expression类的结构:
(3)表达式判重
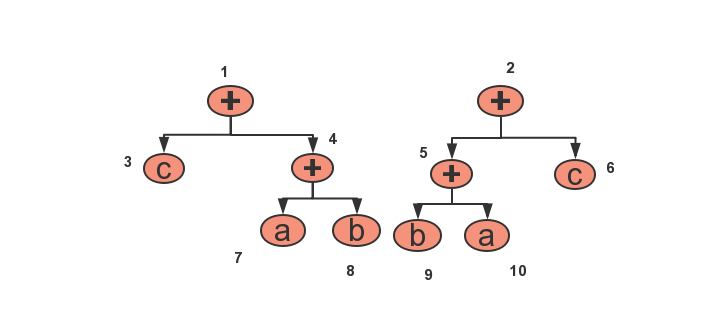
判断的时候如果当前节点的符号和左右子树相同,则是相同的树;否则如果当前节点的符号是+或*,交换左右子树进行比较,如果相同则是相同的数。
比如上面这两棵树,1号节点和2号节点进行比较,因为左右子数不同,交换左右子数比较,3和6比较,相同,4和5比较,左右子数不同,交换左右子树比较,7和10比较,相同,8和9比较,相同。故1和2相同。
具体的实现是将生成的Expression对象放在HashSet中,HashSet的不允许放置重复的对象,每次添加对象,它会判断该的hashcode是否相等,如果相等,再判断调用对象的equals()方法判断是否与已经添加的对象equals,如果equals,则不允许添加,返回false。
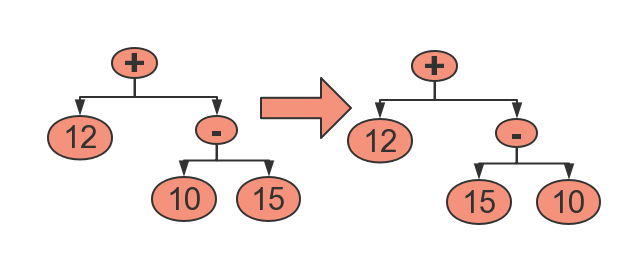
(4)负数的处理
如果计算过程中出现负数,只需要交换左右子树的节点即可,如下图,10-15出现负数,我们将10和15交换:
五、代码说明
Fraction.java关键代码:
/**
* 将分数对象按真分数的表示方法打印
* @return String
*/
@Override
public String toString() {
if(denominator==1){
return molecule+"";
}
else{
int prefix = molecule/denominator;
int realMolecule = molecule % denominator;
if(realMolecule==0){
return prefix+"";
}
//拿分子分母的最小公因数
int commonFactor = Math.abs(getCommonFactor(denominator,realMolecule));
if(prefix==0){
return realMolecule/commonFactor+"/"+denominator/commonFactor;
}
else
return prefix+"'"+realMolecule/commonFactor+"/"+denominator/commonFactor;
}
}BinaryTree.java关键代码:
/***
* 中序遍历
* @return
*/
public String midTraversing() {
BinaryTree node = this;
StringBuilder expression = new StringBuilder();
if(node.symbol!=null){
String symbol = node.symbol;
String left = node.leftChild.midTraversing();
String right = node.rightChild.midTraversing();
if(addBrackets(symbol,node.leftChild.symbol,1)){
expression.append("( ").append(left+" ) ").append(symbol+" ");
}
else{
expression.append(left+" ").append(symbol+" ");
}
if(addBrackets(symbol,node.rightChild.symbol,2)){
expression.append("( ").append(right+ " ) ");
}
else{
expression.append(right);
}
return expression.toString();
}
else{
return node.fraction.toString();
}
}
/***
* 判断是否需要加括号
* @param symbol1
* @param symbol2
* @param leftOrRight 1表示left,2表示right
* @return
*/
public static boolean addBrackets(String symbol1,String symbol2,int leftOrRight){
if(symbol2==null){
return false;
}
if(symbol1.equals(SYMBOL[1])){
if(symbol2.equals(SYMBOL[1])||symbol2.equals(SYMBOL[0])) {
if (leftOrRight == 2) return true;
}
}
if(symbol1.equals(SYMBOL[2])){
if(symbol2.equals(SYMBOL[0])||symbol2.equals(SYMBOL[1])){
return true;
}
}
if(symbol1.equals(SYMBOL[3])){
if(symbol2.equals(SYMBOL[0])||symbol2.equals(SYMBOL[1])){
return true;
}
if(leftOrRight==2){
return true;
}
}
return false;
}
@Override
public boolean equals(Object obj) {
if (obj != null) {
BinaryTree binaryTree = (BinaryTree) obj;
boolean l = false;//判断左子数是否相等
boolean r = false;//判断右子数是否相等
boolean f;//判断数值是否相等
if(binaryTree.fraction!=null){
f = binaryTree.fraction.equals(this.fraction);
}
else{
f = this.fraction == null;
}
boolean s ;//判断符号是否相等
if(binaryTree.symbol!=null){
s = binaryTree.symbol.equals(this.symbol);
}
else{
s = this.symbol==null;
}
if (binaryTree.leftChild != null && binaryTree.rightChild != null&&f&&s) {
l = binaryTree.leftChild.equals(this.leftChild);
r = binaryTree.rightChild.equals(this.rightChild);
if(l==false&&r==false&&(binaryTree.symbol.equals(SYMBOL[0])||binaryTree.symbol.equals(SYMBOL[2]))){
//左右子数交换比较
r = binaryTree.rightChild.equals(this.leftChild);
l = binaryTree.leftChild.equals(this.rightChild);
}
}
else{
l = this.leftChild==null;
r = this.rightChild==null;
}
return l && r && f && s;
} else {
return false;
}
}Expression.java关键代码:
/**
* 将普通表达式转化为逆波兰表达式
* @param expression
* @return
*/
public String changExpressionToReversePoland(String expression){
//逆波兰表达式
StringBuilder profixExpr = new StringBuilder();
String[] elements = expression.split(" ");
Stack<String> stack = new Stack<String>();
String element = null;
String pop = null;
for(int i=0; i<elements.length; i++){
element = elements[i];
//如果当前字符为操作数
if(!isSymbol(element)&&!element.equals("(")&&!element.equals(")")) {
profixExpr.append(element+" ");
}
//如果当前字符为操作符
else if(isSymbol(element)) {
if(stack.isEmpty())
stack.push(element);
else {
while(true) {
if(stack.isEmpty() || priority(stack.peek()) < priority(element))
break;
pop = stack.pop();
profixExpr.append(pop+" ");
}
stack.push(element);
}
}
//如果当前字符为‘(’
else if("(" .equals(element) ) {
stack.push(element);
}
//如果当前字符为‘)’
else if(")".equals(element)) {
while(!(pop = stack.pop() ).equals("("))
profixExpr.append(pop+" ");
}
else
System.out.println("输入文件中表达式有错误");
}
while(!stack.isEmpty()){
profixExpr.append(stack.pop()+" ");
}
String profixExprTem = profixExpr.toString();
return profixExprTem.substring(0,profixExprTem.length()-1);//去掉最后的" "
}
/**
* 由逆波兰表达式生成二叉树
* @param elements
* @param node
*/
public void reversePolandToTree(String[] elements,BinaryTree node){
if(isSymbol(elements[theLengthOfprofixExpr])){
//拿逆波兰表达式的最后一位生成当前节点
node.symbol = elements[theLengthOfprofixExpr];
theLengthOfprofixExpr--;
//先生成右子树,再生成左子数
node.rightChild = new BinaryTree();
reversePolandToTree(elements,node.rightChild);
node.leftChild = new BinaryTree();
reversePolandToTree(elements,node.leftChild);
}
else{
node.fraction = new Fraction(elements[theLengthOfprofixExpr]);
theLengthOfprofixExpr--;
return ;
}
}
/**
* 随机生成二叉树
* @param maxNum
* @param symbolNum
* @return
*/
public BinaryTree generateBinaryTree(int maxNum, int symbolNum){
BinaryTree binaryTree = new BinaryTree();
if(symbolNum==0){
binaryTree.fraction = NumberFactory.getNumber(maxNum);
}
else{
binaryTree.symbol = SYMBOL[(int)(Math.random() * 4)];
int leaveSymbolNum = symbolNum-1;
int symbolNumToLeft = (int)(Math.random()*(leaveSymbolNum+1));
binaryTree.leftChild = generateBinaryTree(maxNum,symbolNumToLeft);
binaryTree.rightChild = generateBinaryTree(maxNum,leaveSymbolNum-symbolNumToLeft);
}
return binaryTree;
}
/**
* 计算二叉树的结果
* @param binaryTree
* @return
* @throws Exception
*/
public Fraction getResult(BinaryTree binaryTree) throws Exception {
if(binaryTree.leftChild==null&&binaryTree.rightChild==null){
return binaryTree.fraction;
}
else{
String symbol = binaryTree.symbol;
Fraction leftChildFraction = getResult(binaryTree.leftChild);
Fraction rightChildFraction = getResult(binaryTree.rightChild);
binaryTree.fraction = operation(symbol,leftChildFraction,rightChildFraction);
//若结果为负数,左右子树交换,值取绝对值
if(binaryTree.fraction.getMolecule()<0){
binaryTree.fraction.setMolecule(Math.abs(binaryTree.fraction.getMolecule()));
BinaryTree node = binaryTree.leftChild;
binaryTree.leftChild = binaryTree.rightChild;
binaryTree.rightChild = node;
}
return binaryTree.fraction;
}
}六、测试运行
保证程序正确的关键:单元测试,这次项目,我们对每个方法都进行了单元测试,确保每个方法都没有错误才继续写下一个方法。
生成的一万道题目:

答案:

统计结果:

七、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 1040 | 2040 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 480 |
| · Design Spec | · 生成设计文档 | 120 | 240 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 40 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 330 | 630 |
| · Code Review | · 代码复审 | 120 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 40 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 1230 | 2160 |
八、项目小结
第一次尝试采用结对编程(Pair Programming)这种编程模式,虽然时间不长,但还是感觉体会颇多。
本次结对编程我俩是舍友。本次结对编程的总体体验是非常愉快的,编程时及时得到同伴的肯定,自信心和成就感会增强,这样就会提高生产率。在开始定方案的时候,两个人分别找资料找思路,方案选出了彼此认为最优秀的一个,二叉树。
结对编程之初,我们两个的配合还是有些不顺畅,编码习惯有差异,甚至对数值的定义起名方式存在差异,会影响到我们的效率。在编写代码的过程中,相互督促,可以使我们都能集中精力,更加认真的工作,不间断的Code Review,提高代码质量。任何一段代码都至少被两双眼睛看过,两个脑袋思考过,大家的思维互相补充,许多隐藏的bug当场就被提出,被消灭在萌芽之中,代码的质量会得到有效提高。
两个人一起编程难免出现意见不一致的现象,出现这种情况我们采取的方式是停止手头的工作,直到讨论清楚得出结论为止,有时候我们这样的讨论可能持续时间比较长,会影响到我们的生产力。很多代码优化的步骤在编写代码的时候就被提出并且改进,我认为这非常重要。整个代码是两个人一起完成的,每个人都非常熟悉整个代码,这非常方便后面的debug调试。
编程耗时最多的方面就是debug。在我们得出设计思路,并将它们初次转化成代码后,往往会有bug。
在设计代码时,有个同伴可以一起讨论,融合两个人不同的见解和观点,我们往往可以得出更加准确且更加高效的设计思路。