这一篇是AAAI 2017的best paper。出自Stanford ,随手查了一下,二作Stefano Ermon指导的AAAI 2017的另一篇paper,拿了Best Student Paper Award (CompSust Track)。在此膜拜一发。
一.题目理解
不得不说,一篇好的paper,题目很重要,是否吸引人。比如这一篇,猛地一看感觉很有内容,想法很新颖。
label-free : 训练时,不使用任何标签数据
Supervision :不用带有label的数据,干的却是监督学习的事情。
Physics and Domain Knowledge:采用领域相关的知识,来作为训练时的监督信息。
由题目可得,作者是要用domain相关的知识,来代替传统监督学习中的标签信息,从而达到不使用label情况下,监督学习的目的。
二.Motivation
1.标签数据是稀少并且昂贵的,但是监督学习,往往需要大量的标签数据
2.如果不带标签训练数据,往往陷入无监督学习的境地,而无监督学习得到的特征往往是朴素的,没有特定的含义与语义,这对于特定的任务而言,往往是不够的。
因此,希望通过一种方法,在监督学习的同时,而不需要使用标签数据,来尽可能达到甚至是超过,带标签的监督学习的精度。
三.Contribution
主要贡献:提出了一种,通过限制条件,即domain相关的知识来约束输出空间, 来进行监督学习的方法。
这样一种方法的好处有两点:

1.训练时不需要label
2.这样一种domain相关的约束,往往是对于多种数据集同时有效的,所以,这样一种方式是generality的。
四.Problem setup
对于传统的监督学习而言:
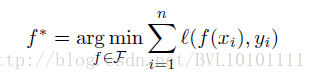
其中,
而在这篇paper中,学习的一种表示是:
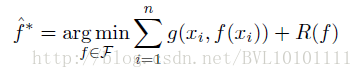
其中,
因为domain相关的约束对于特定的问题而言,往往是必要不充分的,因此如果仅仅依靠domain来约束的话,很有可能导致学习的
这里可以看到,学习的过程中是不包含标签
那么这个
g 具体的表达式是什么?可以这么说,没有固定的一种表达,不同的task,不同的domain,可能g 不尽相同,作者只是提出了这样一种想法。而为了验证这种想法的正确性,作者在三种不同的任务上(两种连续任务,一种离散任务),设计了g ,并且做了相应的测试。接下来,分别细讲这三种任务。
五.Experiment1:Tracking an object in free fall
5.1 background
这个task面临的是,通过视频录下,将一个物体抛在空中过程。这个视频中的每一帧看成一个image
那么
input: N张视频中连续的image。即

output:
即需要通过网络,学习一个函数
5.2Design
对于传统的机器学习而言,可能会这么做——CNN(label: height)
但是,对于本文而言,label-free,如何设计
g ?
5.2.1 domain knowledge
物体在空中的运动,基本遵循,牛顿第二定律即,:
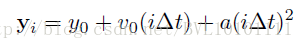
其中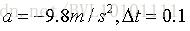
直观上讲,函数
f 需要遵循牛顿第二定律的方程。
5.2.2 约束函数
g
作者是这么将牛顿第二定律方程结合进来的。
首先
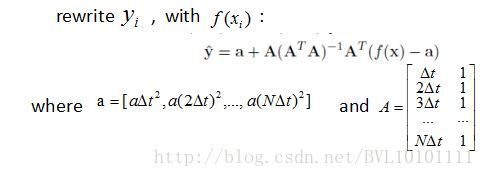
这个方程是怎么得到的呢?
我们将
看成一个线性回归方程,即
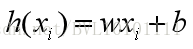
其中v0 可以看成是w ,y0 看成b ,i△t 看成xi 那么,根据对于线性回归方程通过最小二乘法求解,可以得到:
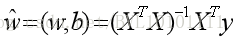
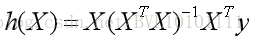
其中
由此便可得到: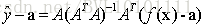
那么得到的
y^ 便可以看做是f(x) 的满足于牛顿第二定律的表达。我们可以想到,通过神经网络得到的高度
f(xi) 与yi 应是尽可能相近的。
因此最后的g 为:
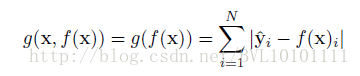
5.3 Experiment
Date set:电脑录下的65段不同的抛物轨迹,共602张图片,
Train set: 40 段轨迹
Tese set : 25 trajectories
Framwork:
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool->
Connected/ReLU ->
Connected/ReLU ->
regression output
5.4 Result
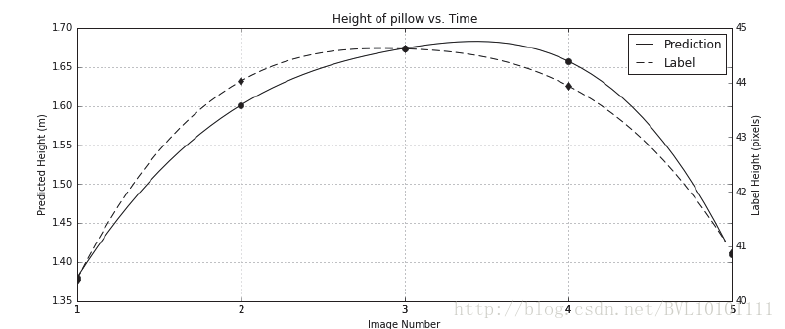
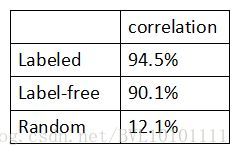
六.Experiment2:Tracking the position of a walking man
6.1 background
和第一个实验类似,只不过这次预测的是行走的人的position(横坐标)
input:N张视频中连续的image。即

输出是:
即需要通过网络,学习一个函数
6.2Design
6.2.1 domain knowledge
行人在短时间内的运动是匀速的,即:
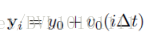
6.2.2 约束函数
g
如果直接按照第一个实验,这么设计的话,会很可能得到
f 的平凡解,比如
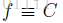
也是满足匀速条件,要是仅用匀速这个domain来约束的话,很可能得到得到这样一种平凡解,而平凡解显然是我们不希望出现,因此为了解决这样一个问题,作者加入了一些正则项:
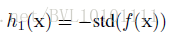
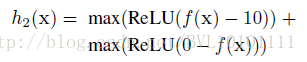
其中,h1(x) 为了使得fx 方差尽可能大,避免平凡解(常数)
h2(x) 为了避免fx 方差过大,而约束0<fx<10 之间因此最后的
g :
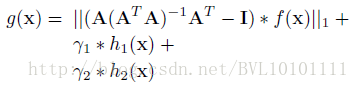
6.3 Experiment
Date set:电脑录下的11段在6个不同场景的抛物轨迹,共507张图片,
Train set: 50%
Framwork:
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool->
Connected/ReLU ->
Connected/ReLU ->
regression output
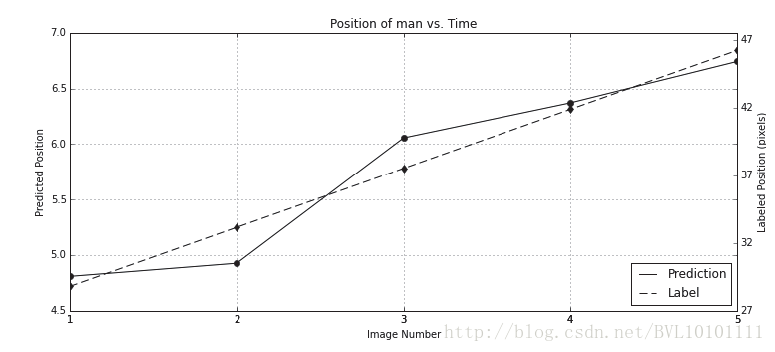
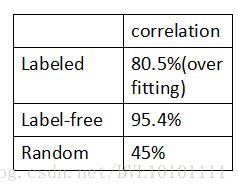
6.4 Result
七.Experiment3:Detecting objects with causal relationships
7.1 background
这是一个离散问题
input:一张image,(图片可能有四种生物,黄色的公主,红色的马里奥,还有棕色和绿色的怪物)

输出是:

即需要通过网络,学习一个函数
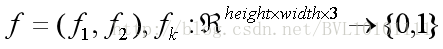
预测每张图片中是否有公主
7.2Design
7.2.1 domain knowledge
这里的domain knowledge是一个逻辑关系,即当出现公主的时候,马里奥一定出现,即
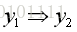
也就是说,可能的预测值是:
7.2.2 约束函数
g
如果直接用这样一种逻辑约束的话,即:
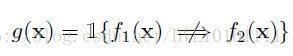
很容易遇到平凡解,比如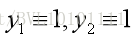
因此在这里,加了三个正则项:
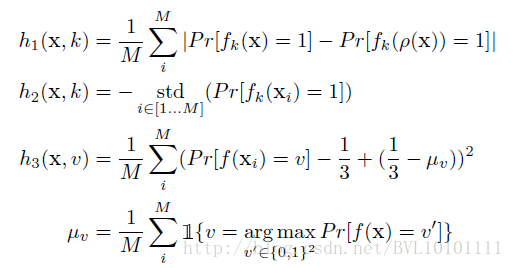
其中,h1(x) 中ρ(x) 是对图片进行各种平移选择变换,这个正则项的目的是为了不考虑图片中公主或者马里奥的位置,更关注于是否存在这两个物体,
h2(x) 为了使得fx 方差尽可能大,避免平凡解(常数)
h3(x) 为了增加输出熵,即每个概率为1/3为输出熵最大。
因此可以得到
g :
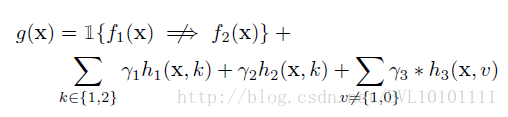
此外,即使加上这三个正则项,还是可能出现一些不愿意看到的解:
比如正确的输出是:,
那么根据这样一种关系,
还可能得到满足domain和约束,
为了解决这样一种平凡解,作者是这么做的
对于预测公主的网络,即
f1 ,在一定卷积后的map上预测是否出现公主,要是出现公主,那么在对应f2 ,公主对应的像素全都不考虑,即:
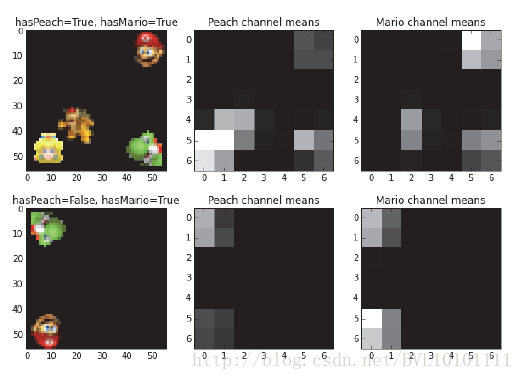
7.3 Experiment
Data Set: not mention
Test Set: 100 imagesFramework(
f1orf2 ):
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool ->
Conv/ReLU/MaxPool->
channel mean ->
Connected/ReLU ->
Connected/ReLU ->
regression outputResult: not mention???
很奇怪,居然没有说明,最后做的结果是如何的,笔者自行yy,可能作者在这个实验上,做的效果不是很好,所以就没有提及。
八.Conclusion
总结来看,不愧是best paper ,想法很好
但是,不足的是第三个实验,有点不够完善,和牵强。此外,对于domain相关约束设计,需要十分巧妙,而且,感觉应用的面不是很广,因为不是所有的task,都有类似于牛顿定律这种强约束。
因此,可能在挖坑,慎跳。