Python解析Excel时需要安装两个包,分别是xlrd(读excel)和xlwt(写excel),安装方法如下:
pip install xlrd
pip install xlwt
读取Excel表
读取excel前需要先引入该模块(import xlrd)。但是需要注意的是,用xlrd读取excel表时,返回的xlrd.Book类型,是只读的,不能对其进行操作。
下面介绍一下读取Excel的流程及使用的一些函数:
1、打开Excel文件并读取数据
xlrd.open_workbook(filename)
filename是要读取的excel表名,当然要加上表所在目录的路径。
如:
data = xlrd.open_workbook('c:\\t2.xls')查看一下data类型:
>>> type(data)
<class 'xlrd.book.Book'>
可见data是xlrd.book.Book类的一个实例。
2、获取一个工作表(sheet)
获取一个工作表的方法有三种,分别为:
(1)通过索引顺序获取
table = data.sheets()[index_number]index_number表示表的索引号,索引号从0开始,表示第一张表,1表示第二张表,依次类似。
查看一下data.sheets这个方法的原型:
>>> help(data.sheets)
sheets(self) method of xlrd.book.Book instance
##
# @return A list of all sheets in the book.
# All sheets not already loaded will be loaded.
这个方法的作用是,将excel中所有表存于list中并返回。
(2)通过索引顺序获取
table = data.sheet_by_index(index_number)index_number表示表的索引号,索引号从0开始,表示第一张表,1表示第二张表,依次类似。
函数原型:
sheet_by_index(self, sheetx) method of xlrd.book.Book instance
##
# @param sheetx Sheet index in range(nsheets)
# @return An object of the Sheet class
(3)通过名称获取
table = data.sheet_by_name(sheet_name)sheet_name表示工作表的名字,但是需要注意的是这个表明的字符串需要使用Unicode的字符串,如:
table = data.sheet_by_name(u'Sheet1')函数原型:
sheet_by_name(self, sheet_name) method of xlrd.book.Book instance
##
# @param sheet_name Name of sheet required
# @return An object of the Sheet class
3、获取整行和整列的值
返回一行:
table.row_values(row_index)row_index表示行索引号,0表示第一行,1表示第二行,以此类推。返回的结果是row_index 行组成的list。
返回一列:
table.col_values(col_index)col_index表示行索引号,0表示第一列,1表示第二列,以此类推。返回的结果是col_index 行组成的list。
4、获取表的行数和列数
获取行数和列数都是固定语法:
table.nrows #获取行数
table.ncols #获取列数
5、获取单元格中的值
语法:
table.cell(row_index, col_index).valuerow_index:表示表的行索引号。
col_index:表示表的列索引号。
创建Excel表
Python中使用的是xlwt模块来生成Excel文件,并且可以控制单元格的格式。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。下面就让我们看看写excel文件的流程及需要使用的函数吧。
写excel前也必须先导入该模块(import xlwt)。流程如下:
1、创建工作表(workbook)
创建workbook,其实就是创建excel,写完数据后,保存就ok了。
语法:
workbook = xlwt.Workbook(encoding = 'ascii')查看一下workbook类型:
>>> type(workbook)
<class 'xlwt.Workbook.Workbook'>
可见workbook是xlwt.Workbook类的一个实例。
2、创建表
worksheet = Workbook.add_sheet(sheet_name)如:
worksheet = Workbook.add_sheet('note')3、往单元格中写内容
worksheet.write(r, c, label='', style=<xlwt.Style.XFStyle object>)参数说明:
r :表示行索引号,从0开始。
c :表示列索引号,从0开始。
label :表示要写的内容。
4、保存excel表
语法:
workbook.save(Excel_name)Excel_name表示保存为什么名,当然可以保存在具体的目录下。如:
workbook.save('c:\\Excel_Test.xls')修改Excel
上面我们介绍了读和写excel,前两种都是不能修改excel的,但是在实际的工作中,经常会遇到修改已经存在的Excel文件这种需求,通常我们能想到的办法,就是先打开这个excel,然后将内容读入到内存,进行处理,然后写到一个新的同名excel文件中,最后直接用修改后的excel文件覆盖了老的excel文件即可。值得我们高兴的是,python已经帮我们实现了这么一个功能模块,那就是模块xlutils,这个模块依赖于xlrd和xlwt模块,它提供了复制excel文件内容和修改文件内容的功能。其实也就是在xlrd.Book和xlwt.Workbook之间建立了一个管道来实现修改功能。实现流程如下图所示:
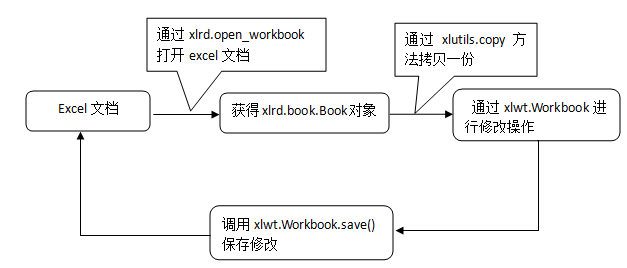
引入模块
引入模块时,需要同时引入读模块和修改模块,如下:
import xlrd
from xlutils.copy import copy
打开excel开始将内容读到内存中:
readbook = xlrd.open_workbook('c:\\t2.xls')使用xlutils.copy模块的copy()方法将原excel另外拷贝一份,准备修改操作:
copyBook = copy(readbook)接下来就是从readBook中(也就是原excel中,注意这里读取数据的时候必须从原excel中读取)取得要修改的工作表,然后使用copybook取到相同工作表,使用进行修改操作,最后把修改的内容保存到
读取到要修改的工作表,如:
readSheet = readBook.sheet_by_index(0)注意:
上面这种读sheet的方法是xlrd模块中的方法,它是没有write()方法,所以是不能写的。
然后将要修改的sheet或整个excel文档拷贝一份:
copyBook = copy(readbook) #拷贝整个excel
copyBook = copy(readSheet) #拷贝第一张表,然后拿到要修改的表
writeSheet = copybook.get_sheet(0)
上面的通过get_sheet()获取的sheet是有write()方法,所以能写。
然后进行修改操作,如:
writeSheet.write(1,0,'asd')#修改表一种的第二行第一个单元格内容当然,上面的实例只是一个简单的写操作,我们还可做一些更复杂的写操作,修改完数据以后,将新的excel表保存并覆盖旧的excel表即可,这就实现了对excel修改的操作需求。
copybook.save('c:\\t2.xls')注意:
读必须从原表中读取,写必须写入拷贝的表中。
下面是一个修改已存在excel的实例:修改t2.xls,并将里面小写字母变成大写字母
import xlrd
from xlutils.copy import copy
#打开excel文档并将内容读取到内存
readbook = xlrd.open_workbook('c:\\t2.xls')
#将excel内容拷贝一份
copybook = copy(readbook)
for i in range(len(readbook.sheets())) :
'''
遍历excel文档中的每个工作表,进行下面的处理
'''
#获得拷贝excel中的表i
sheet = copybook.get_sheet(i)
#获取原excel文档中的表i
readSheet = readbook.sheet_by_index(i)
for row in range(readSheet.nrows) :
'''
对表i中的单元格数据做如下处理
'''
for col in range(readSheet.ncols) :
cell = readSheet.cell(row, col).value
print "type is :", type(cell),cell
if type(cell) in (str, unicode) :
'''
判断一下读取出来的单元格数据格式,
如果为str和unicode的字符串,就调用字符串的upper函数,
将小写改成大写。
'''
res = cell.upper()#把小些改大写
sheet.write(row, col, res)#将修改的内容写入拷贝的excel中
#sheet.write(row, col, '中文'.decode('GBK'))
#将拷贝的excel保存并覆盖原来的excel文件
copybook.save('c:\\wcx\\t2.xls')
编码问题
借助上面的例子,我们来讨论一下Python中编码的问题。
在介绍编码前,先介绍一下Python中判断字符编码的一些函数:
方法一:
isinstance()函数,如:
s = 'ad'
isinstance(s, unicode) #判断s是否是Unicode字符串
方法二:
print type(s).__name__ #看看字符串s是普通字符串还是Unicode字符串方法三:
使用chardet模块进行字符编码判断。
#安装chardet模块
pip install chardet
#导入该模块
import chardet
>>> t
'sdf'
>>> type(t)
<type 'str'>
>>> chardet.detect(t)
{'confidence': 1.0, 'encoding': 'ascii'}
Python中的字符串类型有两种,一种是str类型,一种是Unicode类型。除了Unicode类型的字符串外,其他编码的字符串都是str类型的。例:
>>> s = u'中国'
>>> type(s)
<type 'unicode'>
>>> t = "sdf"
>>> type(t)
<type 'str'>
看下面这个例子:
>>> s = u'中国'
>>> type(s)
<type 'unicode'>
>>> str(s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
为什么会报错呢?
首先我们查看一下我们系统默认编码:
>>> import sys
>>> sys.getdefaultencoding()#查看系统默认编码
'ascii'
从结果可以看出,系统默认编码时ASCII码,ASCII码编码中一个字符只占一个字节,而Unicode编码中一个字符占2个字节(因为要表示中文汉字)。
当调用str()函数将一个Unicode字符串转str类型时,如果我们没有指定编码,就会采用系统默认编码(ascii)对Unicode字符进行编码,但是ascii码和Unicode编码的字符所占字节数不一致,那些非ascii编码的字符就不能被转化,这就是为什么会报UnicodeEncodeError这个错。
那到底str和Unicode之间怎么转呢?
这就需要用到Python提供的解码(decode)和编码(encode)函数了,其实str是Unicode字符串编码(encode)后的字符串,相反的Unicode就是str解码(decode)后的字符串,这样str和Unicode之间转换起来就简单了。如:
>>> s = u'中国'
>>> type(s)
<type 'unicode'>
>>> g = s.encode('gbk')
>>> type(g)
<type 'str'>
>>> u = s.encode('utf-8')
>>> type(u)
<type 'str'>
>>> str(g)
'\xd6\xd0\xb9\xfa'
>>> str(u)
'\xe4\xb8\xad\xe5\x9b\xbd'
>>> t = "asdf"
>>> c = t.decode('ascii')
>>> type(c)
<type 'unicode'>
不过我们还有另一个种处理办法:
那就是将系统默认缺省编码改成utf-8,如下:
>>> import sys
>>> reload sys
>>> sys.setdefaultencoding('utf-8')
utf-8是一种针对Unicode的可变长度字符编码,它用1到6个字节编码Unicode字符,所以显示中文。将系统默认编码设置为utf-8后,就可以直接使用str()函数直接转化Unicode字符了,不用再使用编码解码函数了。如:
>>> s = u"表单"
>>> str(s)
'\xe8\xa1\xa8\xe5\x8d\x95'
网络上传的json、excel、字节流等数据串都被转化成Unicode字符,这样更通用。所以我们从excel中读取出来的数据只要是字符类型的都会被转成Unicode字符(通常需要判断一下),而我们程序中通常都用的是utf-8,所以需要将Unicode转化成uft-8后再处理这些字符,处理完后,再转成Unicode的通过网络传回去,这样保持传回去的字符集和获得的字符集编码一样,就会不出现乱码。
在上面修改excel实例程序中,写了这么一句,虽然被注释了:
sheet.write(row, col, '中文'.decode('GBK'))这句的目的是,让写入excel中的中文不出现乱码,这里设计到一个内码的概念。
什么叫内码呢?
内码是指计算机汉字系统中使用的二进制字符编码,是沟通输入、输出与系统平台之间的交换码,通过内码可以达到通用和高效率传输文本的目的。
而win默认gbk作为系统内部编码,所以要想显示正确的中文,就需要将GBK解码成Unicode,然后传输给excel。