理论
k-means方法是一种常用的聚类方法,其目标是最小化
其中是第i个簇的中心。直接优化上式有难度,故k-means算法采用一种近似方法。
简单来说,k-means算法由两个步骤循环组成:
1. 计算每个sample到各个簇中心的距离,将该sample的类标赋为距离最近的簇的类标;
2. 按照sample的类标重新计算各个簇中心
k-means算法有两个输入参数需要用户指定,一个是簇的个数,另一个是循环次数
代码
# -*- coding: utf-8 -*-
"""
k-means algorithm
From 'Machine Learning, Zhihua Zhou' Ch9
Model: k-means clustering algorithm
Dataset: P202 watermelon_4.0 (watermelon_4.0.npy)
@author: weiyx15
"""
import numpy as np
import matplotlib.pyplot as plt
class kMeans:
def load_data(self, filename):
self.x = np.load(filename)
self.m = self.x.shape[0] # sample number
self.d = self.x.shape[1] # feature dimension
def __init__(self, kk, repeat):
self.load_data('watermelon_4.0.npy')
self.k = kk # cluster number
self.rep = repeat # iteration timess
self.P = np.zeros((self.k, self.d)) # cluster center vector
for i in range(self.k): # initialize vector P
self.P[i, :] = self.x[int(self.m/self.k*i), :]
self.L = np.zeros((self.m,),dtype=int)# cluster labels
def getLabel(self, xi): # INPUT a sample, OUTPUT its label
dmin = np.inf
jmin = 0
for j in range(self.k):
dij = np.linalg.norm(xi - self.P[j, :])
if dij < dmin:
dmin = dij
jmin = j
return jmin
def train(self):
for r in range(self.rep):
cnt = np.zeros((self.k,))
for i in range(self.m):
self.L[i] = self.getLabel(self.x[i, :])
cnt[self.L[i]] = cnt[self.L[i]] + 1
for i in range(self.k):
S = sum(self.x[self.L==i, :])
self.P[i, :] = S / cnt[i]
def plot_data(self):
color = ['r', 'b', 'y']
plt.figure()
for i in range(self.k):
plt.plot(self.P[i,0], self.P[i,1], color[i%self.k]+'*')
for i in range(self.k):
plt.plot(self.x[self.L == i, 0], self.x[self.L == i, 1],\
color[i%self.k]+'.')
if __name__ == '__main__':
km = kMeans(3, 10)
km.train()
km.plot_data()结果
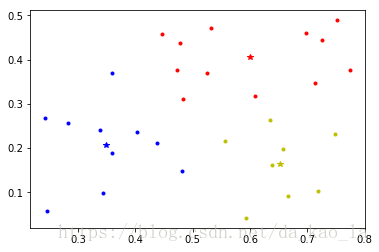
西瓜数据集4.0用k-means算法3聚类10次迭代后的结果如下图所示,其中"*"表示簇中心。