官方文档:http://spark.apache.org/
第一部分: spark 整体的相关的介绍
一、什么是spark
基于官网的介绍:
- Apache Spark™ is a fast and general engine for large-scale data
processing.【对于处理大规模的数据的快速并且通用的引擎】 - Apache Spark is an open source cluster computing system that
aims to make data analytics fast【其是开放源码的集群计算系统,旨在快速分析数据】 - both fast to run and fast to wrtie【快速运行,快速写入】
总结来说如下:
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是Scala编写,方便快速编程。
二、spark技术栈
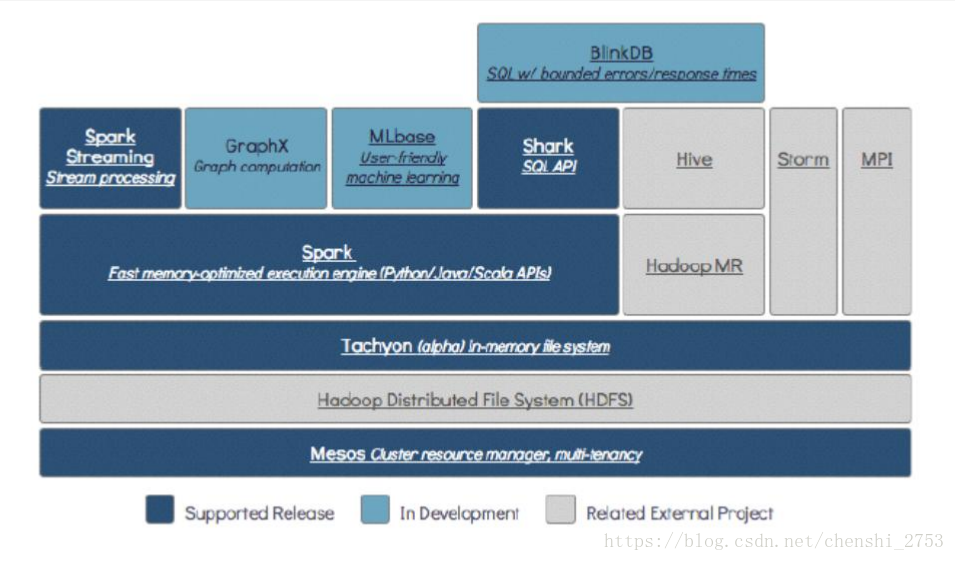
总结:
与hadoop相关的有 HDFS,MR,Hive
与yarn相关:ResourceManager 和 NodeManager
自身核心技术:SparkCore,SparkStreaming,SparkSql
三、spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
四、spark的运行模式
- Local
多用于本地测试,如在eclipse,idea中写程序测试等。 - Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。 - Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。 - Mesos
资源调度框架。
备:要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn
第二部分: SparkCore
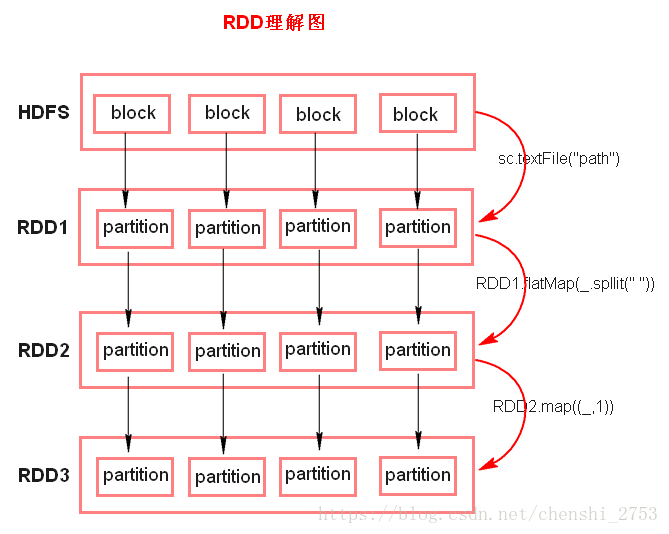
一、RDD的理解
概念
RDD(Resilient Distributed Dateset),弹性分布式数据集。RDD的五大特性:
- 1.RDD是由一系列的partition组成的。
- 2.函数是作用在每一个partition(split)上的。
- 3.RDD之间有一系列的依赖关系。
- 4.分区器是作用在K,V格式的RDD上。
- 5.RDD提供一系列最佳的计算位置。Partiotion对外提供数据处理的本地化,计算移动,数据不移动。
RDD理解图:
- 注意:
- textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。
- RDD实际上不存储数据,存储的是计算逻辑,这里方便理解,暂时理解为存储数据。
什么是K,V格式的RDD?
- 如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
哪里体现RDD的弹性(容错)?
- partition 数量,大小没有限制,体现了RDD的弹性。Partiotion个数可以控制 。可以提高并行度。
- RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
哪里体现RDD的分布式?
- RDD是由Partition组成,partition是分布在不同节点上的。
RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
二、Spark任务执行原理
Lineage 的概念,可理解成从上至下一串的RDD的关系是一个血统。它是一个DAG有向无环图。
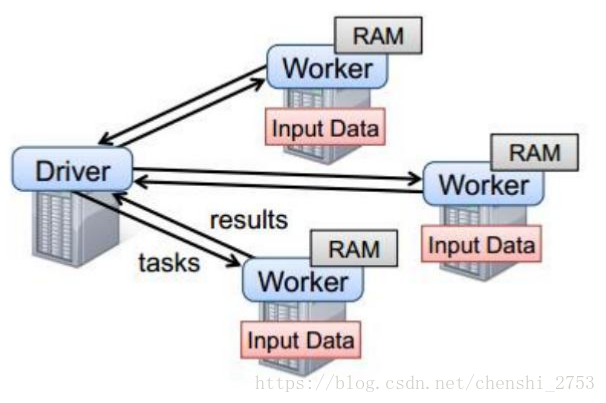
图解:每个worker和Driver都是在不同节点上的一个jvm进程。其中所有的worker都归属一个master(只管理不存放数据)的主节点管理。worder基于RAM(内存)的处理数据后的结果给Driver。但是如果worker中的计算结果过于的大,就不要返给Driver了,不然一会有OOM(内存溢出)发生。
总结如下:
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
Driver与集群节点之间有频繁的通信。
Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
三、spark代码流程
1、创建sparkConf对象
- 1.设置运行模式
- 2.可以设置Application name
- 3.可以设置运行模式以及资源需求
既: SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“xxx”)
2.创建SparkContext(conf)
- 集群的唯一入口
- 由SparkContext创建RDD
既: JavaSparkContext sc = new JavaSparkContext(conf);
3.基于Spark的上下文创建一个RDD,对RDD进行处理。
既: JavaRDD lines = sc.textFile(“./words”);4.使用Transformation 类算子对RDD进行转换
5.使用Action算子触发Transformation类算子执行(决定spark应用程序中job数)
6.关闭Spark上下文对象SparkContext。
四、对转换算子的理解
概念:
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
Transformation类算子
1.filter
过滤符合条件的记录数,true保留,false过滤掉。
2.map
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
3.flatMap
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
4.sample
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。(True,fraction,long)
True 抽样放回
Fraction 一个比例 float 大致 数据越大 越准确
第三个参数:随机种子,抽到的样本一样 方便测试。
5.reduceByKey
将相同的Key根据相应的逻辑进行处理。
6.sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序。
Sortby在java中没有。Action行动算子
概念:
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
Action类算子
1.count
返回数据集中的元素数。会在结果计算完成后回收到Driver端。
返回行数
会将结果回收到Driver端
2.take(n)
返回一个包含数据集前n个元素的集合。(array)
有几个partiotion 会有几个job触发
3.first
first=take(1),返回数据集中的第一个元素。
4.oreach
循环遍历数据集中的每个元素,运行相应的逻辑。
5.collect
将计算结果回收到Driver端。当数据量很大时就不要回收了,会造成oom.
会将结果回收到Driver端
通过图解总结:

一段伪代码理解Action和Transformations算子的执行过程
lines = sc.textFile(“hdfs://...”) // 1
errors = lines.filter(_.startsWith(“ERROR”)) // 2
Mysql_errors = errors.filter(_.contain(“MySQL”)).count // 3
http_errors = errors.filter(_.contain(“Http”)).count // 4 分析:
1和2中的textFile和filter属于转换算子,先不执行,等到了3中的count为Action算子时,才开始触发执行,只是运行时候发现前面的没有运行导致结果为空,就会回去找前一段的代码执行,比如3发现为空,就会去执行errors的2的代码, 2执行任然为空,就回去执行lines的1的代码。这样,就全部触发执行了。
demo演示两种类型的算子:
Scala版:
/**
* Transformations Actoion 算子相关的方法的使用
*/
object WordCount_Transformations {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("chenshi")
val sc = new SparkContext(conf)
val lines : RDD[String] = sc.textFile("./words")
/** Action算子 -- collect 使用 回收结果到Driver 注意:foreach不会回收到Driver端**/
val result = lines.collect()
result.foreach(println)
/**Action算子 -- first的使用 取第一行**/
/*val result = lines.first();
println(result)*/
/**Action算子 -- take的使用 统计前多少行**/
/*val result = lines.take(3)
result.foreach(println)*/
/**Action算子 -- count的使用 统计多少行**/
/*val result = lines.count()
println(result)*/
/** Transformations sample 抽样算子的使用 **/
/*val result = lines.sample(true, 0.1, 100)
result.foreach(println)*/
/**Transformations filter 转换算子的使用 **/
/*val result = lines.filter(line=>{
//println("======")
!line.equals("chen xiao")})// 返回true的留下,false过虑掉
result.foreach(println) */
}Java版:
public class TransformAndActionTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("chenSpark");
// conf.set("", "");
/** SparkContext 是通往集群的通道 **/
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("./words");
/** Action 算子 -- take 的使用 **/
List<String> takes = lines.take(3);
for (String take : takes) {
System.out.println(take);
}
/** Action 算子 -- count 的使用 **/
/*
* long count = lines.count(); System.out.println(count);
*/
/**Transformations sample 的使用 **/
/*
* lines.sample(true, 0.1, 100).foreach(new VoidFunction<String>() {
*
* @Override public void call(String arg0) throws Exception {
* System.out.println(arg0); } });
*/
/**Transformations map 的使用 **/
/*
* lines.map(new Function<String, String>() {
*
* @Override public String call(String arg0) throws Exception { return arg0 +
* "~"; } }).foreach(new VoidFunction<String>() {
*
* @Override public void call(String arg0) throws Exception {
* System.out.println(arg0); } });
*/
/**Transformations filter 的使用 **/
/*
* lines.filter(new Function<String, Boolean>() {
*
* @Override public Boolean call(String lines) throws Exception { return
* lines.equals("chen shi"); } }).foreach(new VoidFunction<String>() {
*
* @Override public void call(String arg0) throws Exception {
* System.out.println(arg0); } });
*/
}
五、RDD的持久化
cache
cache = persist()=persist(StorageLevel.MEMORY_ONLY)
默认将数据存放在内存中RDD 持久化级别persist
可以手动指定持久化级别

常用的级别如下:
memory_only、mory_only_ser、memory_and_disk、memory_and_disk_ser
备:
MEMORY_AND_DISK:先往内存中放数据,内存不够再放磁盘
MEMORY_AND_DISK_SER:“_2”级别代表数据有副本尽量避免使用“_2”和DISK_ONLY级别
cache和persist注意点:
1. cache和persist都是懒执行,需要action类算子触发执行
2. 对一个RDD进行cache或者persist之后可以赋值给一个变量,下次直接使用这个变量就是使用持久化的数据
3. cache/persist之后不能紧跟action算子
操作举例:
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("chenshi")
val sc = new SparkContext(conf)
var lines = sc.textFile("./hs_err_pid6324.log")
lines = lines.persist(StorageLevel.MEMORY_ONLY)测试样例:
object Rdd_Persistence {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("chenshi")
val sc = new SparkContext(conf)
var lines = sc.textFile("./hs_err_pid6324.log")
/** cache() 默认将数据持久化到内存中 **/
//lines.cache() // 最原始的方式,建议使用设置下面的级别
lines = lines.persist(StorageLevel.MEMORY_ONLY) // 具体的级别见上图
/* 第一次是从磁盘读取的,其时间为time1,然后放在缓存中,第二次直接从取,时间为time2*/
val time1 = System.currentTimeMillis()
val count1 = lines.count()
val time1_1 = System.currentTimeMillis()
println("count1="+count1+" ,time="+(time1_1-time1))
val time2 = System.currentTimeMillis()
val count2 = lines.count()
val time2_2 = System.currentTimeMillis()
println("count2="+count2+" ,time="+(time2_2-time2))
sc.stop()
}
checkpoint
不仅可以将数据持久化到磁盘,还可以切断RDD之间的依赖关系,checkpoint也是懒执行
checkpoint流程1.Spark job执行完之后,spark会从finalRDD从后往前回溯
2.当回溯到对某个RDD进行了checkpoint,会对这个RDD标记
3.回溯完成之后,Spark会重新计算标记RDD的结果,然后将结果保存到Checkpint目录中
4.切断与之前RDD的依赖关系
优化:对RDD进行checkpoint之前最好先cache下
如果RDD之间计算逻辑非常复杂,lineage非常长,适用
备:就算checkpoint的文件被删了,执行的时候还会从头去读
举例如下:(需要新建文件夹:checkPointDir)
object CheckPointTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("chenshi")
val sc = new SparkContext(conf)
sc.setCheckpointDir("./checkPointDir")
var lines = sc.textFile("./hs_err_pid6324.log")
lines.checkpoint()
val time1 = System.currentTimeMillis()
val count1 = lines.count()
val time1_1 = System.currentTimeMillis()
println("count1="+count1+" ,time="+(time1_1-time1))
val time2 = System.currentTimeMillis()
val count2 = lines.count()
val time2_2 = System.currentTimeMillis()
println("count2="+count2+" ,time="+(time2_2-time2))
sc.stop()
}
运行完成后在新建的目录下会生成文件,此文件就是记录了checkpoint的信息。保存的数据信息以及元数据的信息