一.浏览器代理
1.直接处理:
1.1在setting中配置浏览器的各类代理:
user_agent_list=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", ......
]
1.2然后在各个请求中调用:
import random from setting import user_agent_list headers= { "Host":"", ...... "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", } def parse(self,response): ...... user_agent=random.choice(user_agent_list) self.header["User-Agent"]=user_agent yeild scrapy.Request(request_url,headers=self.headers,callback=...)
1.3缺点:
使用麻烦,各个请求都要调用,而且耦合性高。
2.使用downloader-middlewares:
2.1使用downloader-middleware(setting中默认是注销了的):

2.2useragent源码如下(默认的User-Agent为Scraoy,可以直接在setting中配置USER_AGENT="......"就会替换Scrapy如红框中):
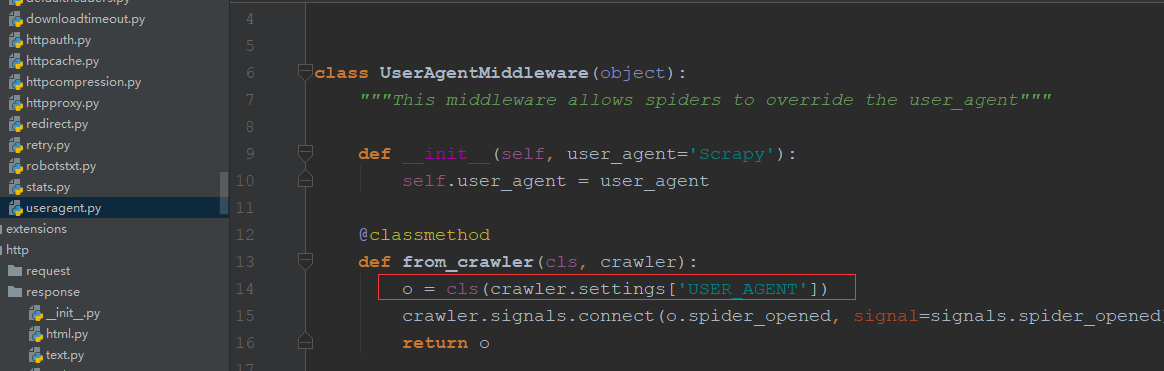
2.3自定义useragentmiddleware(需要在setting中将默认的middleware致为none或数字比自定以的小):

官网简介
2.3.1直接重写函数:
#这样能实现,写一个random()函数选择代理,但维护user_agent_list很麻烦,需要重启spider class RandomUserAgentMiddleware(object): #随机选择User-Agent def __init__(self,crawler): super(RandomUserAgentMiddleware,self).__init__() self.user_agent_list=crawler.setting.get("user_agent_list","") @classmethod def from_crawler(cls,crawler): return cls(crawler) def process_request(self,request,spider): request.headers.setdefault('User-Agent',random())
2.3.2fake_useragent的使用:
安装:pip install fake_useragent
使用:
from fake_useragent import UserAgent ...... class RandomUserAgentMiddleware(object): #随机选择User-Agent,所有浏览器 def __init__(self,crawler): super(RandomUserAgentMiddleware,self).__init__() self.ua = UserAgent() @classmethod def from_crawler(cls,crawler): return cls(crawler) def process_request(self,request,spider): request.headers.setdefault('User-Agent',self.ua.random)
class RandomUserAgentMiddleware(object): # 随机选择User-Agent def __init__(self, crawler): super(RandomUserAgentMiddleware, self).__init__() self.ua = UserAgent() #RANDOM_UA_TYPE为setting中配置的浏览器类型 self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random") @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): #函数里定义函数(动态语言闭包特性),获取是哪种浏览器类型的随机 def get_ua(): #相当于取self.ua.ua_type return getattr(self.ua, self.ua_type) request.headers.setdefault('User-Agent', get_ua())
2.3.3自定义中间件配置:

二.IP代理设置
1.重启路由器:
IP在绝大多数情况会变,用本机IP比用代理IP爬取速度更快。
2.代理IP原理:
1.本机向代理服务器发起请求访问某个网站——>
2.代理服务器访问请求的网站——>
3.数据返回给代理服务器——>
4.代理服务器把数据返回给本机。
3.免费ip网站获取ip(西刺网):


1 # _*_ encoding:utf-8 _*_ 2 __author__ = 'LYQ' 3 __date__ = '2018/10/6 17:16' 4 import requests 5 from scrapy.selector import Selector 6 import MySQLdb 7 8 conn = MySQLdb.Connect(host="localhost", user="root", passwd="112358", db="xici", charset="utf8") 9 cursor = conn.cursor() 10 11 12 def crawl_ips(): 13 headers = { 14 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" 15 } 16 for i in range(1, 3460): 17 re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers) 18 selector = Selector(text=re.text) 19 ip_lists = selector.css('#ip_list tr') 20 get_ips = [] 21 for ip_list in ip_lists[1:]: 22 speed = ip_list.css(".bar::attr(title)").extract_first() 23 if speed: 24 speed = float(speed.split('秒')[0]) 25 texts = ip_list.css("td::text").extract() 26 ip = texts[0] 27 port = texts[1] 28 proxy_type = ip_list.xpath("td[6]/text()").extract_first() 29 get_ips.append((ip, port, proxy_type, speed)) 30 for ip_info in get_ips: 31 cursor.execute( 32 "INSERT REPLACE INTO proxy_ips(ip,port,type,speed) VALUES('{0}','{1}','{2}','{3}')".format(ip_info[0], 33 ip_info[1], 34 ip_info[2], 35 ip_info[3]) 36 ) 37 conn.commit() 38 39 40 class Get_ip(object): 41 def judge_ip(self, ip, port): 42 # 判断ip是否可用 43 http_url = 'https://www.baidu.com' 44 proxy_url = 'https://{0}:{1}'.format(ip, port) 45 try: 46 proxy_dict = { 47 'http': proxy_url 48 } 49 response = requests.get(http_url, proxies=proxy_dict) 50 except: 51 print("该ip:{0}不可用".format(ip)) 52 self.delete_ip(ip) 53 return False 54 else: 55 code = response.status_code 56 if code >= 200 and code < 300: 57 print("ip:{0}有效".format(ip)) 58 return True 59 else: 60 print("该ip:{0}不可用".format(ip)) 61 self.delete_ip(ip) 62 return False 63 64 def delete_ip(self, ip): 65 delete_sql = """ 66 delete from proxy_ips where ip='{0}' 67 """.format(ip) 68 cursor.execute(delete_sql) 69 conn.commit() 70 return True 71 72 def get_random_ip(self): 73 random_sql = """ 74 SELECT ip,port from proxy_ips ORDER BY RAND() LIMIT 1 75 """ 76 result = cursor.execute(random_sql) 77 for ip_info in cursor.fetchall(): 78 ip = ip_info[0] 79 port = ip_info[1] 80 judge_re=self.judge_ip(ip, port) 81 if judge_re: 82 return 'http://{0}:{1}'.format(ip,port) 83 else: 84 return self.get_random_ip() 85 86 if __name__=='__main__': 87 # crawl_ips() 88 get_ip = Get_ip() 89 a = get_ip.get_random_ip()
4.ip代理中间件书写:
class RandomProxyMiddleware(object): #动态代理ip的使用 def process_request(self, request, spider): get_ip=Get_ip() request.meta['proxy']=get_ip.get_random_ip()
5.开源库的使用(scrapy_proxy处理ip):
scrapy-crawla,haipproxy,scrapy-proxies等,可以在github上查看