版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hongbin_xu/article/details/82932431
ResNet v1
1、四个问题
-
要解决什么问题?/ 用了什么办法解决?
- 理论上来说,深层网络的效果至少不会比浅层网络差。
- 对于浅层网络A,深层网络B,假设B的前面部分与A完全相同,后面部分都是恒等映射,这样B至少也会与A性能相同,不会更差。
- 在深层网络中存在梯度消失/梯度爆炸(vanishing/exploding gradients)。
- 归一初始化(normalized initialization)和中间归一化(intermediate normalization)在很大程度上解决了这一问题,它使得数十层的网络在反向传播的随机梯度下降(SGD)上能够收敛。
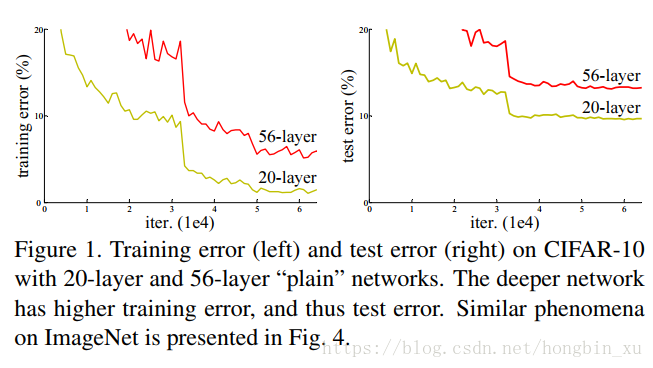
- 训练深层网络时会出现退化(degrdation):随着网络深度的增加,准确率达到饱和(不足为奇)然后迅速退化。
- 提出深度残差网络来解决这一问题。
- 这一退化并不是由过拟合导致的,而是网络过深导致难以训练。论文中给出的例子中深层网络的训练和测试误差都比浅层网络的更高,如下图。
- 理论上来说,深层网络的效果至少不会比浅层网络差。
-
效果如何?
- 在ImageNet上进行了相关实验展示了前面提到的退化问题以及评估深度残差网络,结果表明:
- 极深的残差网络是很容易优化的,但是对应的“plain”网络(仅是堆叠了层)在深度增加时却出现了更高的错误率。
- 深度残差网络能够轻易的由增加层来提高准确率,并且结果也大大优于以前的网络。
- 在ImageNet上进行了相关实验展示了前面提到的退化问题以及评估深度残差网络,结果表明:
-
还存在什么问题?
- 论文中实验了一个超过1000层的模型,该1202层的模型的测试结果比110层的模型要差,尽管训练错误率差不多。这很有可能是过拟合导致的,可能还需要更强大的正则化方法比如maxout或者dropout来对网络进行改进。
2、论文概述
2.1、残差单元
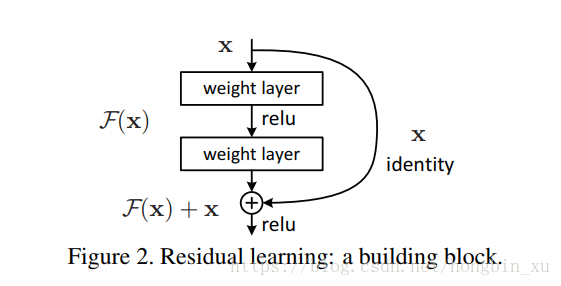
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping
- 设计残差单元的初衷:
- 相比于使用几层网络来拟合一个隐藏的非线性映射,让网络来学习它的残差会更容易一些,即训练残差比原始函数更容易。
- 极端情况下,如果恒等映射(identity mapping)更理想,那么将残差网络变为0比堆叠多个非线性层来拟合恒等映射更容易。
2.2、shortcut连接
- 残差块通过shortcut连接实现。
- 恒等shortcuts(identity shortcuts):要求两个输入的维度相同。
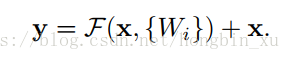
- 映射shortcuts(projection shortcuts):如果两个输入的维度不同,可以给shortcut连接加上一个线性映射 。
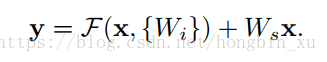
- shortcuts实现的三种选项:
- 对增加的维度使用0填充,所有的shortcuts是无参数的 。
- 对增加的维度使用projection shortcuts,其它使用identity shortcuts 。
- 所有的都采用projection shortcuts 。
- 三种选项相计较:
- 2略好于1,可以认为是1中填充的0并没有进行残差学习。
- 3略好于2,可以将其归结于更多的projection shortcuts引入了更多的参数。
- 1、2、3几个模型的差距很小,说明了projection shortcuts对于解决退化(degradation)问题不是必须得。
- 为了减少复杂度和模型尺寸,不采用模型3,而是选择模型2。
2.3、瓶颈结构
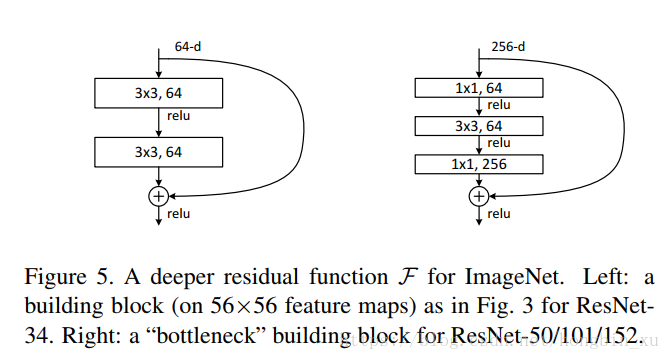
- 第一个 卷积负责减小维度,让中间的 卷积获得更少的通道数, 第二个 卷积负责增加维度。整个架构类似瓶颈,可以减少计算复杂度。
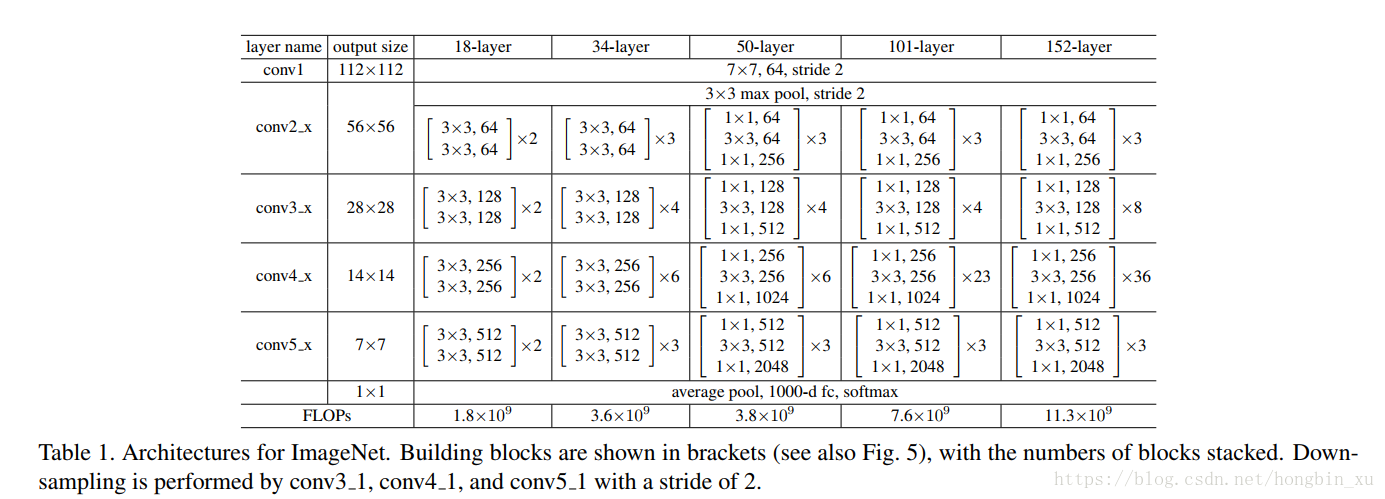
2.4、网络结构
2.5、训练细节
- 图像增强:从原始图像或水平翻转图像中随机采样一个 的crop。
- 图像预处理:减去均值。
- 卷积结构:每个卷积层后,都接一个batch normalization(BN)。
- 超参数:batch size为256;学习率为0.1,当测试集上的错误率平稳后就将学习率除以10;采用SGD,权值衰减设置为0.0001,动量为0.9;整个模型迭代 次;
- 测试时,融合多个模型的结果,分别计算多尺度图片的结果,对结果的评分取均值。(调整图像的大小使它的短边长度分别为 )