版权声明:转载注明出处 https://blog.csdn.net/J0Han/article/details/82926557
一.基本概念
- 张量:张量就是多维数组(列表),用“阶”表示张量的维度。
0阶张量称为标量,表示一个单独的数;如 S=123;
1阶张量称为向量,表示一个一维数组;如V=[1,2,3]
2阶张量称为矩阵,表示一个二维数组,可以有i行j列个元素; - 基于TensorFlow的神经网络:用张量表示数据,用计算图搭建神经网络,用会话(Session)执行计算图,优化线上的权重(参数),得到模型。
- TensorFlow的数据类型有float32和int32等
二.举例
实现TensorFlow的加法:
import tensorflow as tf # 导入TensorFlow
a = tf.constant([[1.0, 2.0]]) # 定义张量
b = tf.constant([[3.0], [4.0]])
# 上面有提到 二阶张量实际就是矩阵
result = a+b
print(result)
打印结果:
Tensor("add:0", shape=(2, 2), dtype=float32)
这个表示节点,也是一个张量,名称为add:0。上面有提到如果想要计算出结果,可以用会话(Session)计算结果,将代码改成:
import tensorflow as tf
a = tf.constant([[1.0, 2.0]])
b = tf.constant([[3.0], [4.0]])
result = a+b
# 使用Session计算结果
with tf.Session() as sess:
print(sess.run(result))
运行结果:
[[4. 5.]
[5. 6.]]
三.搭建简单的计算图
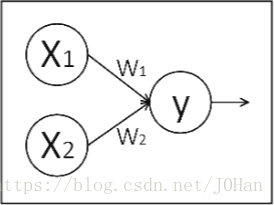
神经网络的基本模型就是神经元,而神经元的基本模型就是数学中的乘,加运算。我们来搭建如下的计算图:
图中X1和X2表示输入,W1和W2分别是 输入到y的权重,即y = x1w1 + x2w2
我们可以使用TensorFlow的tf.matmul()方法来实现,用代码实现如下:
import tensorflow as tf
a = tf.constant([[1.0, 2.0]])
b = tf.constant([[3.0], [4.0]])
# 用matmul()实现a,b矩阵的乘法
y = tf.matmul(a, b)
print(y)
执行结果:
Tensor("MatMul:0", shape=(1, 1), dtype=float32)
执行结果表示y只是一个张量,只是在计算过程中的一个节点,并没有进行运算,如果想要进行运算,同上使用会话(Session)就行,将代码改成:
import tensorflow as tf
a = tf.constant([[1.0, 2.0]])
b = tf.constant([[3.0], [4.0]])
y = tf.matmul(a, b)
with tf.Session() as sess:
# 打印出计算结果
print(sess.run(y))
执行结果:
[[11.]]
这表示y的计算结果就是11;因为根据矩阵乘法:1×3 + 2×4 = 11
四.神经网络的参数
神经网络的参数是指神经元线上的权重w,用变量表示,一般会先随机生成这些参数,最后经过反向传播(后面会提到)不断优化参数。 使用tf.Variable生成参数w,tf.Variable的参数就是生成w的方式,在神经网络中常用的生成随机数/数组的函数如下:tf.random_normal() # 生成正太分布的随机数
tf.truncated_normal() # 生成去掉过大偏离点的正态分布随机数
tf.random_uniform() # 生成均匀分布随机数
tf.zeros() # 生成全0数组
tf.ones() # 生成全1数组
tf.fill() # 生成全定值数组
tf.constant() # 生成给定值的数组