1.伙伴链接
2.分工
丁水源:
字符统计;行数统计;单词统计;(不同于个人项目的做法。)主函数接口整合。
黄毓明:
单词及词组词频统计;附加题;爬取;
3.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | ||
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 | ||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | ||
| · Design | · 具体设计 | ||
| · Coding | · 具体编码 | ||
| · Code Review | · 代码复审 | ||
| · Test | · 测试(自我测试,修改代码,提交修改) | ||
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ||
| 合计 |
4.关键代码及其解释
爬取:
我们选择用Python来完成网页信息爬取,主要思路是先解析出CVPR2018的网址结构,然后用select()通过类名'.ptitle'筛选出title对应元素,再遍历select()返回的list,筛选出href,得到相对网址,对所得到的网址进行内容爬取,也是利用select()进行筛选,将得到的Title与Abstract按指定格式写入result.txt
爬取部分截图:
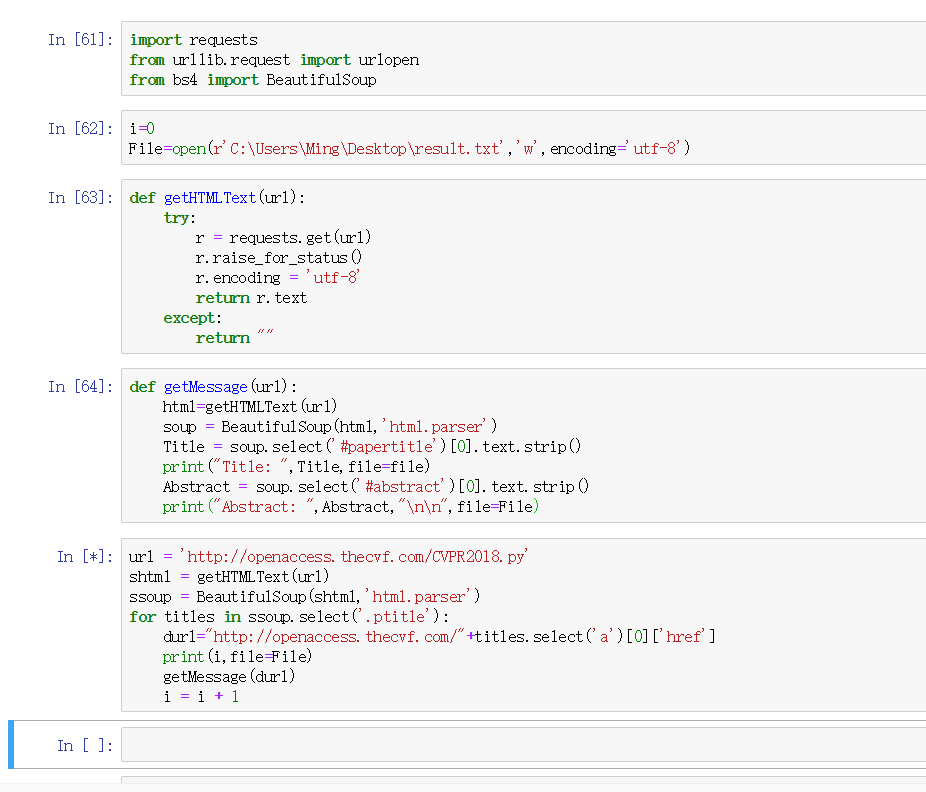
主要代码组织及其框架:
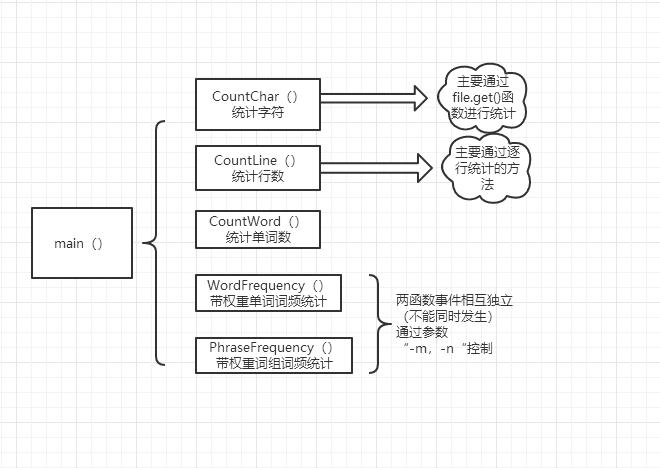
关键函数代码内部主要组织思想流程图:
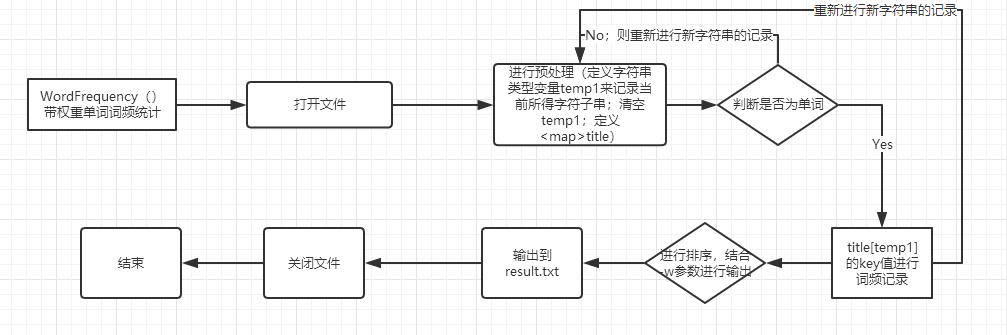
(WordFrequency() :带权重单词词频统计)
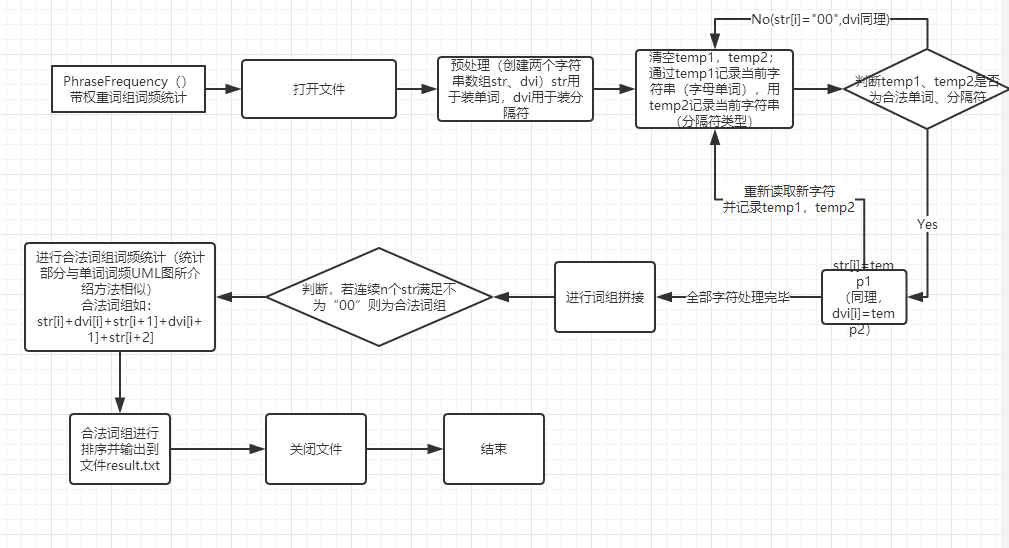
(PhraseFrequency() 带权重的词组词频统计)
WordFrequency() :带权重的词频统计代码解释;
5.附加题设计
6.(性能分析)及其单元测试
7.Githu插入:
8.困难与收获
1.爬取,其实一开始我们是比较烦恼该如何去进行爬取的,但是后来经过小伙伴的努力,我们还是解决了这个问题!(开心~O(∩_∩)O
2.对题目的整体把握。本次的题目其实比较有把握去完成,(十分感谢前几次实践的积累~~~!!)但是尽管如此,我们还是在函数接口上,以及一些函数细节上把握出现了一些偏差,以至于我们花了不少时间进行调试。但是最终还是全部完成啦~~
3.附加题的想法。关于附加题,我们一开始还是比较迷茫的。但是当我们在完成主要任务的过程中,我们便萌发了一些想法,最终也比较顺利的完成附加题的展示。
4.对于细节的把握不够。在制作的过程中,我们时不时地会发现,我们漏了题目的哪些细节,以至于我们必须随着项目的进度一次一次的阅读题目,我们感觉对于“读透题目”也是一个十分重要的技能!!能节约十分多的时间和资源!
9.评价
我的小伙伴“黄毓明”同学: 虽然他自称他是佛系队友,但是!!!!我还是十分敬佩他的,他总能够在我们项目的一些“瓶颈”期时提出一些比较新颖的想法,以及解决问题的方法,总能够给我们这个两人小团体带来一些方向和曙光!和黄毓明同学一起合作,我感觉我自己也学到了很多,也成长了很多,十分荣幸能和他结对完成项目!@黄毓明~~ 一起加油鸭~!!!!
10.进度表