该功能只在MySQL 5.7和Percona 5.7版本里支持。之前的版本,全文索引对中文支持不友好,所以更多的公司选择用第三方开源软件Sphinx做全文索引。
注意 Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL、PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,让应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP、Python、Perl、Ruby等,同时为MySQL 设计了一个存储引擎插件。
如今在MySQL 5.7版本里,提供了一个内置全文索引支持中文的ngram解析器插件,MariaDB 10.1并不提供此插件。它的工作原理为:例“生日快乐”四个字,当参数设置为ngram_token_size = 2 (默认两个中文单词)时,那么ngram解释器将解释为“生日”“快乐”,ngram_token_size参数不可动态修改,所以事先要规划好以几个单词作为搜索条件,避免搜索的结果不准确。
下面对该功能进行测试。这里以三个单词为准,即ngram_token_size = 3(加入my.cnf配置里),其表结构如图2-30所示。

注意 使用ngram解释器,这些参数将失效:innodb_ft_min_token_size、innodb_ft_max_token_size、ft_min_word_len和ft_max_word_len。
然后插入测试数据,如图2-31所示。

现在用如下命令查询数据:
- select * from articles where MATCH(title,body) AGAINST ('数据库' IN BOOLEAN MODE);
查询后的结果如图2-32所示。

通过执行计划器可以看到已经利用上了title这个索引,并且只需要扫描一行即可查出结果。
但这里的停止词(stopwords)设计有一个缺陷。停止词就是指不想让用户在搜索的时候能搜到“李洪志大师” “法轮大法”等词汇,需要事先定义好停止词,这样就不会被搜索到。前面说到的设计缺陷是指你必须事先就定义好,假如日后还想再定义停止词“活摘器官”,则需要重建一次全文索引,如果表很大,那么会很费时间。
下面看例子。
首先定义一张停止词(stopwords)表用来保存敏感词汇,表结构如图2-33所示。
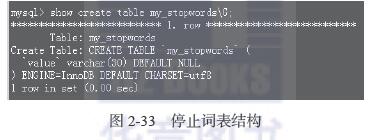
然后往这个停止词表里插入数据库词汇,并且执行如下语句使其生效。
- SET GLOBAL innodb_ft_server_stopword_table = 'test/my_stopwords';
结果如图2-34所示。

再对其中的参数进行说明,这里的test是数据库;my_stopwords是表。
注意 停止词(stopwords)表要和主表放在同一个数据库Schema下。
新开启一个会话终端,再次执行查询语句:
- select * from articles where MATCH(title,body) AGAINST ('数据库' IN BOOLEAN MODE);
会发现停止词(stopwords)并没有生效,如图2-35所示。

这时必须重建一次全文索引,使其生效,如图2-36所示。
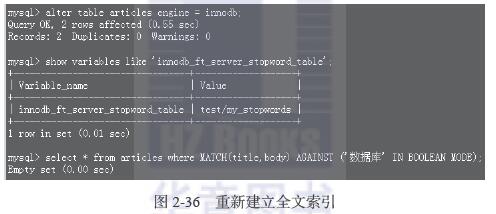
这样的操作已经查询不到关键字为“数据库”的记录了。