上一篇文章机器学习实战之K近邻方法心得体会我详细的讲解了K近邻方法,短短几天就很受大家的热捧,这更加坚定了我写下去的决心(其实那篇文章也就100+的浏览量,哈哈哈哈,我才不会逼着你们去看那篇文章的) 打算写这篇决策树的文章时,本以为会写的很快,因为它内容也就那么多,而且涉及的知识点也不深。可哪想被我这个爱钻研得人(其实是爱钻牛角啦,哈哈,我是个厚颜无耻的人,大家请自动忽略)一点一点剖析,最后竟发现历时三天还是无法动笔。虽然这其中有上课没时间的缘故,但自己还是最这个进度不满意。所以觉得无论无何还是先把自己的心得写出来,虽然还有一个小part没弄懂,我将会在最后写出来(毕竟不完美的才是最完美的,嘿嘿),也希望各位大佬能给我些指导。好了,废话比比完了,现在进入正文了(严肃脸).这一篇我将介绍ID3算法,C4.5算法,CART算法这三个主要的决策树算法
1 决策树的相关概念
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系
决策树学习的损失函数:通常是正则化的极大似然函数
决策树学习的策略:是以损失函数为目标函数的最小化
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。
剪枝:决策树可能对训练数据有很好的分类能力,但可能发生过拟合现象.。所以需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点.
特征选择:如果特征数量很多,在决策树学习开始时对特征进行选择,只留下对训练数据有足够分类能力的特征。
信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验嫡H(D)与特征A给定条件下D的经验条件嫡H(D|A)之差,即
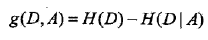
决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。


|D|表示其样本容量,即样本个数。设有K个类Ck,k=1,2,...,K,|Ck|为属于类Ck的样本个数。根据特征A的取值将D划分为n个子集D1,D2,...,Dn,|Di|为Di的样本个数。记子集Di中属于类Ck的样本的集合为Dik。
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据集的经验嫡大的时候,信息增益值会偏大,反之,信息增益值会偏小。

信息增益比:特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验H(D)之比:

好了,大致的概念是介绍完了(其实这一大段都是借鉴别人的,原谅一个文笔不好的理工男) 下面就开始介绍具体的决策树了
2. ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征。


ID3算法简单的说就是每次选择信息增益最大的特征进行分类,然后根据选择的特征构建整个树。
ID3算法只有分类树算法没有回归树算法
ID3算法只有树的生成,所以该算法生成的树容易产生过拟合
所以综合以上几点,都觉得ID3算法训练出来的分类器就是一弱分类器,适用范围很小,不推荐大家使用(写了这么多大家还是要看下去的啊) 下面就是老规矩贴源码了 我的编程环境是Python2.7 可能在Python3.6中出现一些语法问题,大家注意了
from math import log
import operator
# 创建本地数据集
def createDataSet():
dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
# 计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
# 按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):
reDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
reDataSet.append(reducedFeatVec)
return reDataSet
# 选择最好的数据集划分方式
def chooseBestFeatureToDplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 返回出现次数最多的分类名称
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter, reverse=True)
return sortedClassCount[0][0]
# 创建树的函数代码
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToDplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
if __name__ == '__main__':
myDat, labels = createDataSet()
reDat = splitDataSet(myDat, 0, 1)
myTree = createTree(myDat, labels)
print(myTree)下面这个是相应的图,大家看完之后会有个更直接的形象

好了,ID3算法就将这么多了,因为也确实也没什么好讲的啦,下面将讲解C4.5算法
2. C4.5算法
与ID3算法相似,不同是用信息增益比来选择特征。

以信息增益作为训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正
但在我看来:不能进行剪枝处理的决策树都不是最好的决策树,而且C4.5决策树目前应用最多的也是分类树,所以尽管它相较于ID3分类树有了一些改进,也不推荐大家使用。下面贴源码参考
import operator
from math import log
# 创建本地数据集
import treePlotter
def createDataSet():
dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
def calcShannonEntOfFeature(dataSet, feat):
numEntries = len(dataSet)
labelCounts = {}
for feaVec in dataSet:
currentLabel = feaVec[feat]
if currentLabel not in labelCounts:
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
# 按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):
reDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
reDataSet.append(reducedFeatVec)
return reDataSet
def chooseBestFeatureToSplit(dataSet):
# last col is label
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEntOfFeature(dataSet, -1)
bestInfoGainRate = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEntOfFeature(subDataSet, -1)
infoGain = baseEntropy - newEntropy
iv = calcShannonEntOfFeature(dataSet, i)
# value of the feature is all same,infoGain and iv all equal 0, skip the feature
if iv == 0:
continue
infoGainRate = infoGain / iv
if infoGainRate > bestInfoGainRate:
bestInfoGainRate = infoGainRate
bestFeature = i
return bestFeature
# 返回出现次数最多的分类名称
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter, reverse=True)
return sortedClassCount[0][0]
# 创建树的函数代码
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
if __name__ == '__main__':
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
lensesTree = createTree(lenses, lensesLabels)
print(lensesTree)
treePlotter.createPlot(lensesTree)下面是相应的图

好了,这两个Low比的决策树终于介绍完了(两个决策树的作者此时会不会跑出来打我,哈哈哈哈,开个玩笑哈)。下面我将会着重介绍CART分类和回归树,以及它们相应的剪枝算法。机器学习实战这本书上只给了CART回归树这个算法,可能是觉得分类树比较简单吧。我这个老实娃还是把分类树这个算法也一并给大家供大家参考(不要感动的一塌糊涂啊!!!)