数据结构指数据的组织方式,着重于数据之间的相互关系。数据库指一定规则存储在一起的数据集合,向外提供查询、插入、更新、删除等服务,着重于数据的存储与管理。数据结构通常与内存有关,数据库通常与硬盘有关。
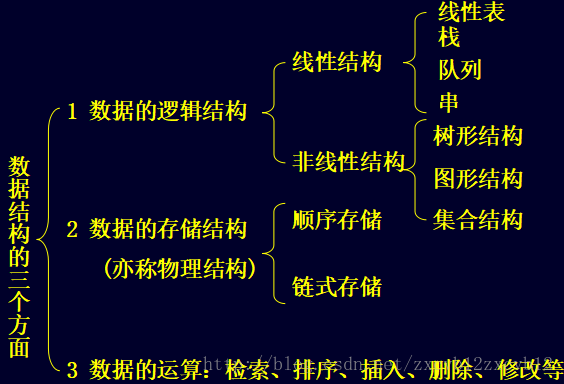
数据元素之间固有的逻辑关系——数据逻辑结构;
数据元素及关系在计算机内的表示——数据存储结构;
对数据结构的操作——算法。
基本术语:
是计算机处理的信息的某种特定的符号表示形式
两类数据元素:
不可分割的“原子”型数据元素:整数"5",字符 "N" 等
多个数据项构成的数据元素,数据项是数据不可分割的最小标识单位。
例如:
整数数据对象集合:N={0,±1,±2,…},
字母字符数据对象集合:C={‘A’,‘B’,…,‘Z’}。
数据结构:
特点:数据元素集合相同,而其上的关系不同,则构成的数据结构不同。
内容:
数据的逻辑结构
数据的存储结构
数据的操作
数据结构的形式定义:
数据结构是一个二元组 DS = ( D,R ) 其中:D是数据元素的有限集,R是D上关系的有限集。
序偶:有序对。例如:<班主任,班长1>
前驱:序偶中第一元素为第二元素的前驱
后继:序偶中第二元素为第一元素的后继
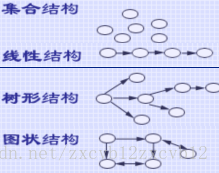
数据元素及其关系在计算机内的表示。
逻辑结构可以映射为以下 四种存储结构:
1、顺序存储结构:把逻辑上相邻的数据元素存储在物理位置也相邻的存储单元中,借助元素在存储器中的相对位置来表示数据元素 之间的逻辑关系。
2、链式存储结构:借助指针表达数据元素间的逻辑关系。不要求逻辑上相邻的数据元素在物理位置上也相邻。
3、索引存储结构:在存储数据元素的同时,还建立附加的索引表。通过索引表,可以找到存储数据元素的节点。
4、散列存储结构:根据散列函数和处理冲突的方法确定数据元素的存储位置
“抽象”指与具体实现无关,仅考虑能做什么,而不考虑如何做。
形式描述
ADT = ( D,R,P ) 其中:D 是数据对象, R 是 D 上的关系集, P 是 D 的基本操作集。
数据抽象
用ADT描述程序处理的实体时,强调的是其本质的特征、其所能完成的功能以及它和外部用户的接口(即外界使用它的方法)。
数据封装
将实体的外部特性和其内部实现细节分离,并且对外部用户隐藏其内部实现细节。
抽象数据类型的实现 :
面向对象——类
面向过程——结构体
分析:定义——实部+i虚部
实部和虚部的取值范围——实数
复数的操作——+、-、×、%
ADT复数的数据类型抽象 数据对象:
D = {e1,e2 | 实数 } 数据关系:
R1 = {<e1,e2> | e1是复数的实部,e2是复数的虚部 }
用两个实数来表示复数,将复数定义为两个实数的有序对,并约定实部是前驱,虚部是后继。
基本操作:
InitComplex( &Z, v1, v2 )
操作结果:构造复数Z,其实部和虚部分别被赋以参数v1和v2的值。
操作结果:用 ImagPart 返回复数Z的虚部值。
分析:定义——长、宽
长和宽的取值范围——实数
矩形的操作——初始化(构造)矩形、计算矩形的
周长和面积
ADT RECtangle is
数据对象:D = {e1,e2 | 实数 } 数据关系:R1 = {<e1,e2> | e1是长,e2是宽 }
基本操作:
InitRectangle(r,len,width);
操作结果:初始化矩形长和宽
Circumference(r);
操作结果:计算矩形周长
Area( r );
操作结果:计算矩形面积
算法:
1、有穷性: 对于任意一组合法的输入值,在执行有穷步骤之后一定能结束。
2、确定性:每条指令必须有确切的含义,不能有二义性。
3、可行性:算法中描述的操作都是用已经实现的基本运算组成。
输入:可以有0、1、或多个输入量。
输出:它是一组与"输入"有确定关系的量值,是算法进行信息加工后得到的结果,这种确定关系即为算法的功能。
举个例子:
void exam1()
{
n=2;
while (n%2==0)
n=n+2;
cout<<n<<endl;
}
void exam2()
{
y=0;
x=5/y;
cout<<x<<‘,’<<y<<endl;
}
结果:(1)算法是一个死循环,违反了算法的有穷性特征。(2)算法包含除零错误,违反了算法的可行性特征
算法的设计准则:
1、正确性
除了应该满足算法说明中写明的“功能”之外,应对各组典型的带有苛刻条件的输入数据得出正确的结果 。
2、健壮性
算法应对非法输入的数据作出恰当反映或进行相应处理,一般情况下,应向调用它的函数返回一个表示错误或错误性质的值。
3、可读性
易于理解、实现和调试。
4、高效性
执行时间短(时间效率)、占用存储空间少(空间效率)
时间复杂度:
一般用算法中语句被执行的次数来表示算法的时间效率(算法的时间复杂度)。
【例1-8】分析下面程序段的时间复杂度。
(1) int i,sum=0;
(2) for(i=0;i<n;i++)
(3) sum=sum+i;
(4) return sum;
T(n)=2n+3,且T(n)是n数量级的。
渐进时间复杂度:忽略次要语句的执行次数,只对重要的语句(原操作)和执行最频繁的语句进行计数,同时对计算结果只取其最高次幂,且略去系数不写。
渐近时间复杂度常简称为时间复杂度,用大O表示。
T(n)=2n+3=O(n)
也就是只求出T(n)的最高阶,忽略其低阶项和常系数,这样既可简化T(n)的计算,又能比较客观地反映出当n很大时,算法的时间性能。
例如,T(n)=3n2-5n+10000=O(n2)
一个没有循环的算法的基本运算次数与问题规模n无关,记作O(1),也称作常数阶。
一个只有一重循环的算法的基本运算次数与问题规模n的增长呈线性增大关系,记作O(n),也称线性阶。
其余常用的还有平方阶O(n2)、立方阶O(n3)、对数阶O(log2n)、指数阶O(2n)等。
各种不同数量级对应的值存在着如下关系:
O(1)<O(log2n)<O(n)<O(n*log2n)<O(n2)<O(n3)<O(2n)<O(n!)
例子:
int fun(int n)
{
int i,j,k,s;
s=0;
for (i=0;i<=n;i++)
for (j=0;j<=n;j++)
for (k=0;k<=n;k++)
s++;
return(s);
} 该算法的基本操作是语句s++,其频度: T(n)=O(n3) 则该算法的时间复杂度为O(n3)。
总结: 数据结构(逻辑结构、存储结构)
抽象数据类型(数据与操作)
算法的时间效率(时间复杂度)