本章uboot代码分析是基于全志A33平台,uboot代码版本是U-boot-2011.09。
Bootloader概念介绍:
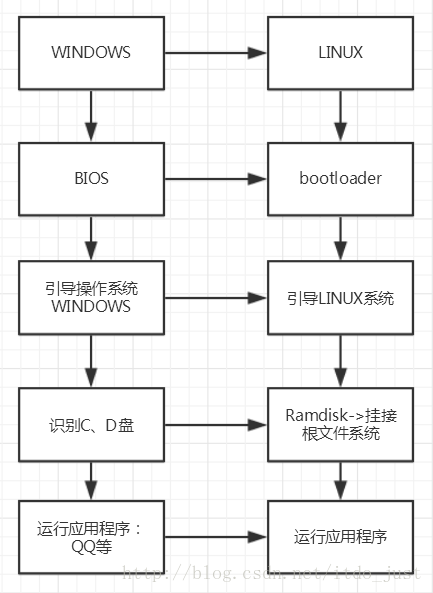
在嵌入式操作系统中,BootLoader是在操作系统内核运行之前运行。可以初始化硬件设备、建立内存空间映射图,从而将系统的软硬件环境带到一个合适状态,以便为最终调用操作系统内核准备好正确的环境。在嵌入式系统中,通常并没有像BIOS那样的固件程序(注,有的嵌入式CPU也会内嵌一段短小的启动程序),因此整个系统的加载启动任务就完全由BootLoader来完成。在一个基于ARM7TDMI core的嵌入式系统中,系统在上电或复位时通常都从地址0x00000000(视CPU而定)处开始执行,而在这个地址处安排的通常就是系统的BootLoader程序。
对应的示意图如下:
代码分析:
拿到uboot代码的第一我们可以使用指令来编译一下试试看,我分析的代码是基于全志A33平台的,编译代码指令如下:
make sun8iw5p1
make 这个过程主要涉及到两个文件,顶层的Makefile文件和mkconfig文件,mkconfig文件是一个脚本,通过文件的注释可以了解到它的作用。
# Script to create header files and links to configure
# U-Boot for a specific board.
#
# Parameters: Target Architecture CPU Board [VENDOR] [SOC]要了解整个程序的框架我们要从解析Makefile开始,打开根目录下的Makefile文件。
一般根目录下的Makefile会有很多个配置文件项,他们一般有如下参数:
Target ARCH CPU Board name Vendor SoC Options这些参数会指名芯片的一些信息,uboot根据这些信息来编译生成目标,但是上面的这款芯片(sun8iw5p1)我没有在Makefile里面找到相关的目标定义,不过在Makefile看下来可以找到这样的一段代码:
sinclude $(obj).boards.depend
$(obj).boards.depend: boards.cfg
awk '(NF && $$1 !~ /^#/) { print $$1 ": " $$1 "_config; $$(MAKE)" }' $< > $@一般obj为空,因此有一个隐藏文件 .boiards.depend
我们可以从根目录.boiards.depend里面找到下面这一句代码
sun8iw5p1: sun8iw5p1_config; $(MAKE)执行的时候sun8iw5p1目标就是这里来的
上面那一句的意思如下:
$< >是输入文件(boards.cfg),$@是目标本身(.boards.depend) ,如果文件中某行不为空,第一个元素不为‘~’和‘#’就将其以print
{ print $$1 ": " $$1 "_config; $$(MAKE)" }
" $$1 "_config; $$(MAKE)"的格式输出到文件$@中,最终生成的.boards.depend也可以通过在uboot目录命令行执行下面语句得到这个.boards.depend
awk '(NF && $$1 !~ /^#/) { print $$1 ": " $$1 "_config; $$(MAKE)" }' boards.cfg >.boards.depend接着来看其中的意思:

sun8iw5p1:sun8iw5p1_config; $$(MAKE)
意思如下:
sun8iw5p1 依赖于 sun8iw5p1_config
$$(MAKE)的意思就是make
如果放在一行需要加个分号。换行的$(MAKE)用tab开头所以整句的意思就是先构建 sun8iw5p1_config 随后执行 make
sun8iw5p1: sun8iw5p1_config; $$(MAKE)== make sun8iw5p1_config&&make接着在Makefile里面可以看下下面的几行代码:
%_config:: unconfig
@$(MKCONFIG) -A $(@:_config=)%在Makefile中作为通配符用来通配任意长度的字符,因此当我们执行 make sun8iw5p1_config的时候就会匹配到%_config这条语句。::在Makefile中用来强制执行下面的命令,所以匹配到%_config之后,就会去执行 unconfig
unconfig:
@rm -f $(obj)include/config.h $(obj)include/config.mk \
$(obj)board/*/config.tmp $(obj)board/*/*/config.tmp \
$(obj)include/autoconf.mk $(obj)include/autoconf.mk.depunconfig的作用是去除原来的配置信息。然后去执行下面这条:
@$(MKCONFIG) -A $(@:_config=)这条命令,@的作用是用来去除回显, $(MKCONFIG) 在前面被定义为
MKCONFIG := $(SRCTREE)/mkconfig这里可以试着将上面 MKCONFIG 前面的 @ 去掉,然后执行make sun8iw5p1_config,可以通过回显看到以下内容:
/……/u-boot-2011.09/mkconfig –A sun8iw5p1
Configuring for sun8iw5p1 board…所以我们执行make sun8iw5p1 _config实际上被解析成:
/……/u-boot-2011.09/mkconfig –A sun8iw5p1接下来可以打开 mkconfig 看下里面做了什么:
#首先定义一些变量供后面填充
APPEND=no # Default: Create new config file
BOARD_NAME="" # Name to print in make output
TARGETS=""
arch=""
cpu=""
board=""
vendor=""
soc=""
options=""
#$表示参数的个数,这里我们的参数是2个
#-a表示逻辑与
#传入的指令为: mkconfig -A sun8iw5p1
#条件符合
if [ \( $# -eq 2 \) -a \( "$1" = "-A" \) ] ; then
# Automatic mode
#这里是执行egrep命令( egrep命令是一个搜索文件获得模式,使用些命令可以任意搜索文件中的字符串和符号,也可以为你搜索一个多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字、一个句子。);
#-i参数是指:当进行比较时忽略字符的大小写;
#^是指:行首,用法举例。^[fuck]表示:以fuck开头的行;
#[[:space:]]是指:空格或tab;
#^[[:space:]]则是指:以空格或tab开头的行; #*则是指:匹配零个或多个先前字符。如:'*grep'匹配所有一个或多个空格后紧跟grep的行;
#${2}是指:第二个参数的内容,即sun8iw5p1;
#||是指:和我们c语言的或的用法一样,前面成立的时候,后面不执行;
line=`egrep -i "^[[:space:]]*${2}[[:space:]]" boards.cfg` || {
echo "make: *** No rule to make target \`$2_config'. Stop." >&2
exit 1
}
#@设置shell,就理解成重新录入参数,以此最终shell的参数如下:
set ${line}
# add default board name if needed
#@如果传人的参数的总个数为3个,才执行set命令,这里不成立
[ $# = 3 ] && set ${line} ${1}
fi所以上面的代码就是指在boards.cfg文件中搜索以
${2}(即sun8iw5p1)
开头的行,匹配成功后,把改行保存到变量line中,因此后面的${line}的内容就是:
sun8iw5p1 arm armv7 sun8iw5 sunxi sun8iw5所以这里最终执行的命令被改为:
./mkconfig sun8iw5p1 arm armv7 sun8iw5 sunxi sun8iw5接着mkconfig后面的代码:
#如果参数个数大于0个,执行下面的,成立
while [ $# -gt 0 ] ; do
#类似于c中的switch,这里没有符号的case条件
case "$1" in
--) shift ; break ;;
-a) shift ; APPEND=yes ;;
-n) shift ; BOARD_NAME="${1%_config}" ; shift ;;
-t) shift ; TARGETS="`echo $1 | sed 's:_: :g'` ${TARGETS}" ; shift ;;
*) break ;;
esac
done
#如果参数个数小于4,退出,这里不成立
[ $# -lt 4 ] && exit 1
#如果参数个数大于7,退出,这里不成立
[ $# -gt 7 ] && exit 1
# Strip all options and/or _config suffixes
#1%_config表示去掉后面的'_config' CONFIG_NAME=sun8iw5p1
CONFIG_NAME="${1%_config}"
#BOARD_NAME = sun8iw5p1
[ "${BOARD_NAME}" ] || BOARD_NAME="${1%_config}"
#target=sun8iw5p1
target="$1"
#arch=arm
arch="$2"
#cpu=armv7
cpu="$3"
if [ "$4" = "-" ] ; then
board=${BOARD_NAME}
else
#board=sun8iw5
board="$4"
fi
#参数个数大于4,vendor=sunxi
[ $# -gt 4 ] && [ "$5" != "-" ] && vendor="$5"
#参数个数大于5,soc=sun8iw5
[ $# -gt 5 ] && [ "$6" != "-" ] && soc="$6"
#参数个数不大于6,这个不成立
[ $# -gt 6 ] && [ "$7" != "-" ] && {
# check if we have a board config name in the options field
# the options field mave have a board config name and a list
# of options, both separated by a colon (':'); the options are
# separated by commas (',').
#
# Check for board name
tmp="${7%:*}"
if [ "$tmp" ] ; then
CONFIG_NAME="$tmp"
fi
# Check if we only have a colon...
if [ "${tmp}" != "$7" ] ; then
options=${7#*:}
TARGETS="`echo ${options} | sed 's:,: :g'` ${TARGETS}"
fi
}
#这里不成立
if [ "${ARCH}" -a "${ARCH}" != "${arch}" ]; then
echo "Failed: \$ARCH=${ARCH}, should be '${arch}' for ${BOARD_NAME}" 1>&2
exit 1
fi
#该步骤就是打印大家常见的:Configuring for smdkc100 board...
if [ "$options" ] ; then
#不成立
echo "Configuring for ${BOARD_NAME} - Board: ${CONFIG_NAME}, Options: ${options}"
else
#成立
echo "Configuring for ${BOARD_NAME} board..."
fi
#
# Create link to architecture specific headers
#
#这里执行分支
if [ "$SRCTREE" != "$OBJTREE" ] ; then
mkdir -p ${OBJTREE}/include
mkdir -p ${OBJTREE}/include2
cd ${OBJTREE}/include2
rm -f asm
ln -s ${SRCTREE}/arch/${arch}/include/asm asm
LNPREFIX=${SRCTREE}/arch/${arch}/include/asm/
cd ../include
mkdir -p asm
else
cd ./include
#删除现有的asm连接文件
rm -f asm
#重新让asm指向\arch\arm\include\asm
#问:为什么要建立这样的连接文件呢?
#答:是为了在源码中写代码的方便,比如:
#include <asm/type.h> 源码中的书写形式!!!!
#但是当执行完配置命令后,就相当于#include <asm-arm/type.h>。这样方便支持多种架构,根据架构名(arm)临时生成
ln -s ../arch/${arch}/include/asm asm
fi
rm -f asm/arch
if [ -z "${soc}" ] ; then
ln -s ${LNPREFIX}arch-${cpu} asm/arch
else
#重新让include/asm/arch指向arch-sun8iw5
ln -s ${LNPREFIX}arch-${soc} asm/arch
fi
if [ "${arch}" = "arm" ] ; then
rm -f asm/proc
#建立链接asm/proc到proc-armv
ln -s ${LNPREFIX}proc-armv asm/proc
fi
#
# Create include file for Make
#
#该步骤就是创建一个头文件(即include/config.mk),用于顶层的Makefile的宏控
echo "TARGET = ${target}" > config.mk
echo "ARCH = ${arch}" >> config.mk
echo "CPU = ${cpu}" >> config.mk
echo "BOARD = ${board}" >> config.mk
[ "${vendor}" ] && echo "VENDOR = ${vendor}" >> config.mk
[ "${soc}" ] && echo "SOC = ${soc}" >> config.mk
# Assign board directory to BOARDIR variable
if [ -z "${vendor}" ] ; then
BOARDDIR=${board}
else
BOARDDIR=${vendor}/${board}
fi
#
# Create board specific header file
#
#创建开发板相关的头文件inlucde/config.h
if [ "$APPEND" = "yes" ] # Append to existing config file
then
echo >> config.h
else
> config.h # Create new config file
fi
echo "/* Automatically generated - do not edit */" >>config.h
for i in ${TARGETS} ; do
i="`echo ${i} | sed '/=/ {s/=/ /;q; } ; { s/$/ 1/; }'`"
echo "#define CONFIG_${i}" >>config.h ;
done
#以下就是填充config.h中的内容了:>是新建、>>是追加
cat << EOF >> config.h
#define CONFIG_BOARDDIR board/$BOARDDIR
#include <config_cmd_defaults.h>
#include <config_defaults.h>
#include <configs/${CONFIG_NAME}.h>
#include <asm/config.h>
EOF
exit 0可以看到在 include/config.mk 的内容如下
TARGET = sun8iw3p1
ARCH = arm
CPU = armv7
BOARD = sun8iw3
VENDOR = sunxi
SOC = sun8iw3至此单板的配置算是完成了,接着继续回到顶层Makefile,Makefile先是定义了一些目录,然后获取刚生成的config.mk的配置信息,确定编译工具链,定义生成目标 start.o,添加库文件,生成目标文件u-boot.bin。
我们看下它是如何生成目标u-boot.bin
#生成以下目标
ALL-y += $(obj)u-boot.srec $(obj)u-boot.bin $(obj)System.map $(obj)u-boot-$(TARGET).bin搜索得到u-boot.bin依赖于u-boot
#后面那个u-boot是elf格式的,需要生成二进制格式的u-boot.bin
$(obj)u-boot.bin: $(obj)u-boot
$(OBJCOPY) ${OBJCFLAGS} -O binary $< $@
$(BOARD_SIZE_CHECK)查看u-boot的依赖如下:
$(obj)u-boot: depend \
$(SUBDIRS) $(OBJS) $(LIBBOARD) $(LIBS) $(LDSCRIPT) $(obj)u-boot.lds
$(GEN_UBOOT)
ifeq ($(CONFIG_KALLSYMS),y)
smap=`$(call SYSTEM_MAP,u-boot) | \
awk '$$2 ~ /[tTwW]/ {printf $$1 $$3 "\\\\000"}'` ; \
$(CC) $(CFLAGS) -DSYSTEM_MAP="\"$${smap}\"" \
-c common/system_map.c -o $(obj)common/system_map.o
$(GEN_UBOOT) $(obj)common/system_map.o
endif直接看最后一项“GEN_UBOOT”
GEN_UBOOT = \
UNDEF_SYM=`$(OBJDUMP) -x $(LIBBOARD) $(LIBS) | \
sed -n -e 's/.*\($(SYM_PREFIX)__u_boot_cmd_.*\)/-u\1/p'|sort|uniq`;\
cd $(LNDIR) && $(LD) $(LDFLAGS) $(LDFLAGS_$(@F)) $$UNDEF_SYM $(__OBJS) \
--start-group $(__LIBS) --end-group $(PLATFORM_LIBS) \
-Map u-boot.map -o u-boot这段指令非常多,我们可以使用取巧的办法,直接编译uboot,查看uboot生成的log来查看执行了什么,查看关键词“UNDEF_SYM”,这里取出关键的几句如下:
cd /home/zephyr/zephyr/a33_linux/sina33-qt-7inch/lichee/brandy/u-boot-2011.09 && /home/zephyr/zephyr/a33_linux/sina33-qt-7inch/lichee/brandy/u-boot-2011.09/../gcc-linaro/bin/arm-linux-gnueabi-ld -pie -T u-boot.lds -Bstatic $UNDEF_SYM arch/arm/cpu/armv7/start.o
--start-group api/libapi.o arch/arm/cpu/armv7/libarmv7.o
...
...
/home/zephyr/zephyr/a33_linux/sina33-qt-7inch/lichee/brandy/u-boot-2011.09/arch/arm/lib/eabi_compat.o -L./openssl -lssl -lcrypto -L /home/zephyr/zephyr/a33_linux/sina33-qt-7inch/lichee/brandy/gcc-linaro/bin/../lib/gcc/arm-linux-gnueabi/4.6.3 -lgcc -Map u-boot.map -o u-boot链接文件依赖于链接脚本 u-boot.lds 和后面的源材料 start.o 以及后面所有的lib库,最后生成 u-boot ,他们是根据 u-boot.lds 来组织成 uboot 的, u-boot.lds 链接脚本标示了这些文件的代码段,只读数据段,数据段,和u_boot_cmd段(这个段是uboot自己定义的段区),他们的链接地址是从“0x4A000000(根据不同芯片不同)”开始
的,这里第一个运行的程序是 start.o ,开始地址是 0x4A000000 ,后面我们可以从第一个文件 start.S 来分析uboot的功能。
感谢网友提供的参考资料:
https://www.cnblogs.com/CoderTian/p/5986188.html
http://blog.csdn.net/ultraman_hs/article/details/52745259
http://www.cfanz.cn/?c=article&a=read&id=50173