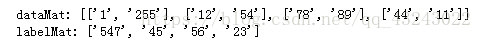好多时候我们要读取txt文件获得数据,并把数据的按行或者按列存放到列表中,从而生成特征和类别标签。今天读了好几个都没有成功,最后发现,数据间的分隔符十分重要,总结一下经验。
数据间的分隔符是空格
读取的代码如下所示:
file=open('ll.txt')
dataMat=[]
labelMat=[]
for line in file.readlines():
curLine=line.strip().split(" ")
floatLine=map(float,curLine)#这里使用的是map函数直接把数据转化成为float类型
dataMat.append(floatLine[0:2])
labelMat.append(floatLine[-1])
print 'dataMat:',dataMat
print 'labelMat:',labelMat
print np.shape(dataMat)
可以看到,读出的数据dataMat 是一个由每行前两列组成的二维数组,labelMat 是由每行的最后一列组成的列表
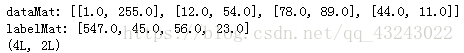
注意:
- 看到程序里读取每一行的时候,会有line.strip().split(“ ”),这里,strip() 是为了删除开始和结尾的空格符(仅限头和尾处);
- 后面的split(" ") 就很重要了,它是划分这一行里的每个元素,括号里“ ”表示的是以空格作为分割符,来分割这一行的元素(不是行与行之间的分割);
- 这里元素之间只有一个空格,如果是多个空格,则无法读取,因为空格也会成为元素,且空格无法转换成浮点型(错误如下):ValueError: could not convert string to float:
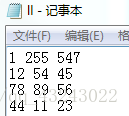
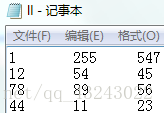
数据间分隔符是制表符 \t
这类文件类似于从excel中复制生成的,每个数据元素的间隔是制表符 \t ,下图中数据就是从excel中复制而来的:
读取的代码如下:
file=open('ll.txt')
dataMat=[]
labelMat=[]
for line in file.readlines():
curLine=line.strip().split("\t")
floatLine=map(float,curLine)#这里使用的是map函数直接把数据转化成为float类型
dataMat.append(floatLine[0:2])
labelMat.append(floatLine[-1])
print 'dataMat:',dataMat
print 'labelMat:',labelMat
print np.shape(dataMat)
print np.array(dataMat)

注意:
与空各类的间隔符相比,这里只是strip(“ ”)一项有改动:strip("\t"),也就是以制表符作为每一行内元素的分割标志。如果仍用 strip(“ ”) ,会出现如下错误:ValueError: invalid literal for float(): 1 255 547
因为行内没有空格,所以读取了整行为一个元素:1,\t,255,\t547所以错误显示无法转换为浮点型
千万不要忘记 map(float, line),如果没有转换成float这一步,则读出的均为字符串: