1.简介
Elastic (官网:https://www.elastic.co) 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用,通过简单的REST api 隐藏了lucene的复杂性,从而让全文搜索变得简单。
2.安装
下载地址:https://www.elastic.co/downloads/elasticsearch
#我的系统信息
$uname -a
Linux iZ23iuzu9fvZ 2.6.32-696.20.1.el6.x86_64 #1 SMP Fri Jan 26 17:51:45 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
#下载并解压
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.1.tar.gz
$ tar -zxvf elasticsearch-6.4.2.tar.gz
#启动 Elastic
$ ./bin/elasticsearch注意:不能使用root账户启动;
如果这时报错"max virtual memory areas vm.maxmapcount [65530] is too low",要运行下面的命令。
$ sudo sysctl -w vm.max_map_count=262144如果一切正常,Elastic 就会在默认的9200端口运行。这时,打开另一个命令行窗口,请求该端口,会得到说明信息。
$ curl localhost:9200
{
"name" : "mvQoSGm",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "4vUSt2_AQFSj5LZDVgR74g",
"version" : {
"number" : "6.4.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "04711c2",
"build_date" : "2018-09-26T13:34:09.098244Z",
"build_snapshot" : false,
"lucene_version" : "7.4.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3.安装 中文分词插件IK
ik插件地址: https://github.com/medcl/elasticsearch-analysis-ik
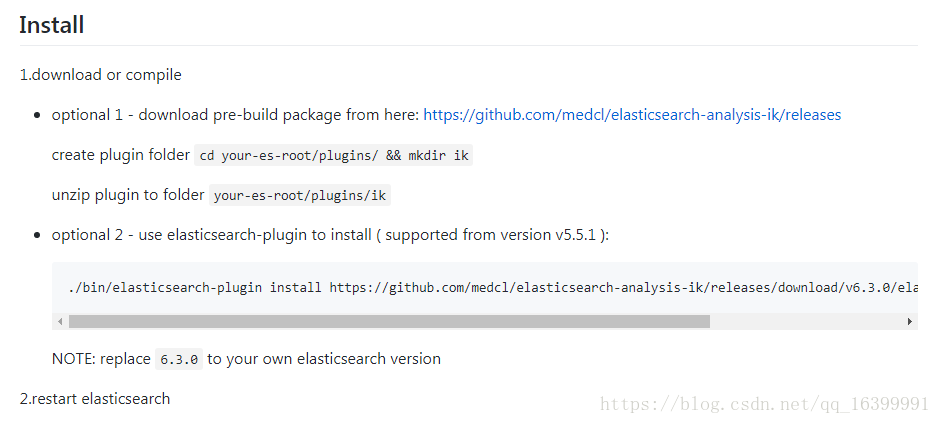
我使用了方法1 进行下载安装;
#下载与你的es版本想对应的版本
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.1/elasticsearch-analysis-ik-6.4.1.zip
......
#解压
$ unzip elasticsearch-analysis-ik-6.4.1.zip
......
#完成后重启es通过_analyze 分析分词器 standard 和ik
#默认的standard
$ curl -XGET -H "Content-Type: application/json" "http://localhost:9200/_analyze?pretty=true" -d'{"text":"公安部:各地校车将享最高路权"}';
{
"tokens" : [
{
"token" : "公",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "安",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "部",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "各",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "地",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "校",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "车",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "将",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 7
},
{
"token" : "享",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "最",
"start_offset" : 10,
"end_offset" : 11,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "高",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 10
},
{
"token" : "路",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 11
},
{
"token" : "权",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 12
}
]
}
ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
$curl -XGET -H "Content-Type: application/json" "http://localhost:9200/_analyze?pretty=true" -d'{"text":"公安部:各地校车将享最高路权","analyzer": "ik_max_word"}';
{
"tokens" : [
{
"token" : "公安部",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "公安",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "部",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "各地",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "校车",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "将",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "享",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "最高",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "路",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "权",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 9
}
]
}
$ curl -XGET -H "Content-Type: application/json" "http://localhost:9200/_analyze?pretty=true" -d'{"text":"公安部:各地校车将享最高路权","analyzer": "ik_smart"}';
{
"tokens" : [
{
"token" : "公安部",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "各地",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "校车",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "将",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "享",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "最高",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "路",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "权",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 7
}
]
}
可以看到 standard只是分成一个个的汉字,ik更加的智能。
4.创建 一个索引
参考官网文档Indices APIs :https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
官方例子:
curl -X PUT "localhost:9200/twitter" -H 'Content-Type: application/json' -d'
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}
'
-d指定了你的参数,我把这些参数放到了json文件中,
#createindex.json
{
"setings" : {
"refresh_interval":"5s", #代表创建新的索引后,不会立即生效,5s后刷新 默认1s
"number_of_shards" : 1, #索引分片
"number_of_replicas" : 0 #副本
},
"mappings" : {
"product" : {
"dynamic":false,
"properties" : {
"productid" : {
"type" : "long"
},
"name":{
"type":"text",
"index":true,
"analyzer":"ik_max_word"
},
"short_name":{
"type":"text",
"index":true,
"analyzer":"ik_max_word"
},
"desc":{
"type":"text",
"index":true,
"analyzer":"ik_max_word"
}
}
}
}
}
然后 使用 -d‘@your jsonFile’指定你的json文件。下边我创建了一个索引名称为product(自己定义)的索引。
curl -H "Content-Type: application/json" -XPUT "http://localhost:9200/product?pretty=true" -d'@createindex.json'返回:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "product"
}
说明创建成功。
5.添加数据
官网文档 Document APIs:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html;
我这里给上边创建的product索引添加一条数据
curl -X PUT "localhost:9200/product/product/1?pretty=true" -H 'Content-Type: application/json' -d'
{
"productid" : 1,
"name" : "测试添加索引产品名称",
"short_name" : "测试添加索引产品短标题",
"desc" : "测试添加索引产品描述"
}
'
运行后返回结果如下,创建成功。

6.查询
官方文档Search APIs :https://www.elastic.co/guide/en/elasticsearch/reference/current/search.html
查询上边建立的product文档
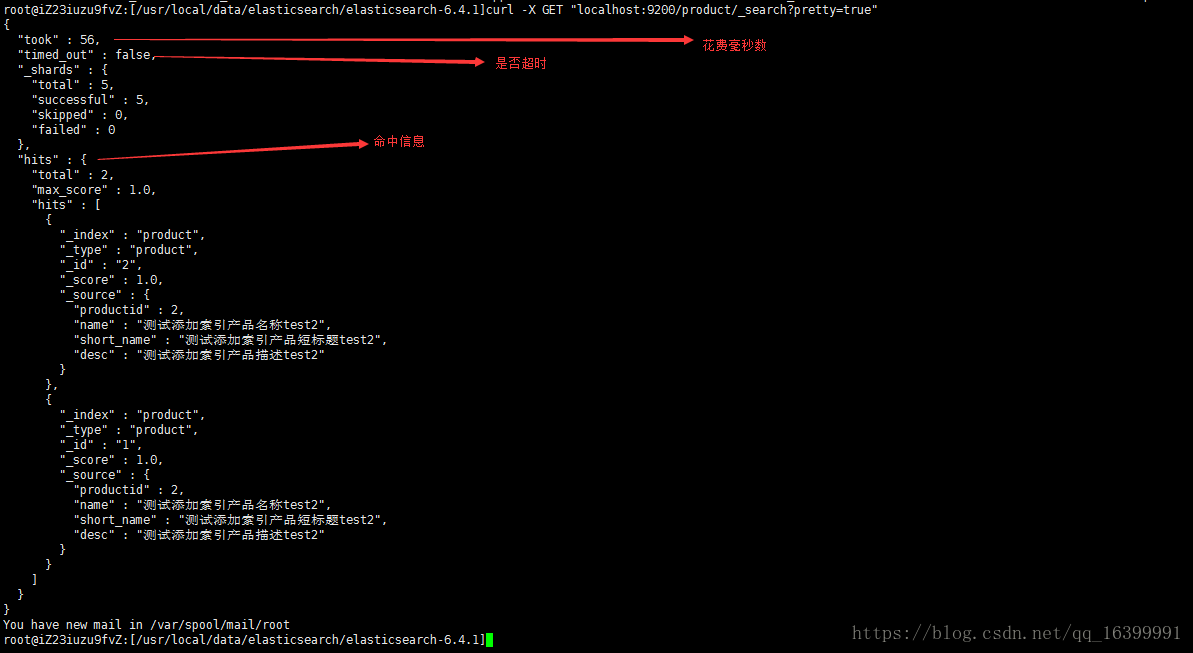
查询了所有
curl -X GET "localhost:9200/product/_search?pretty"

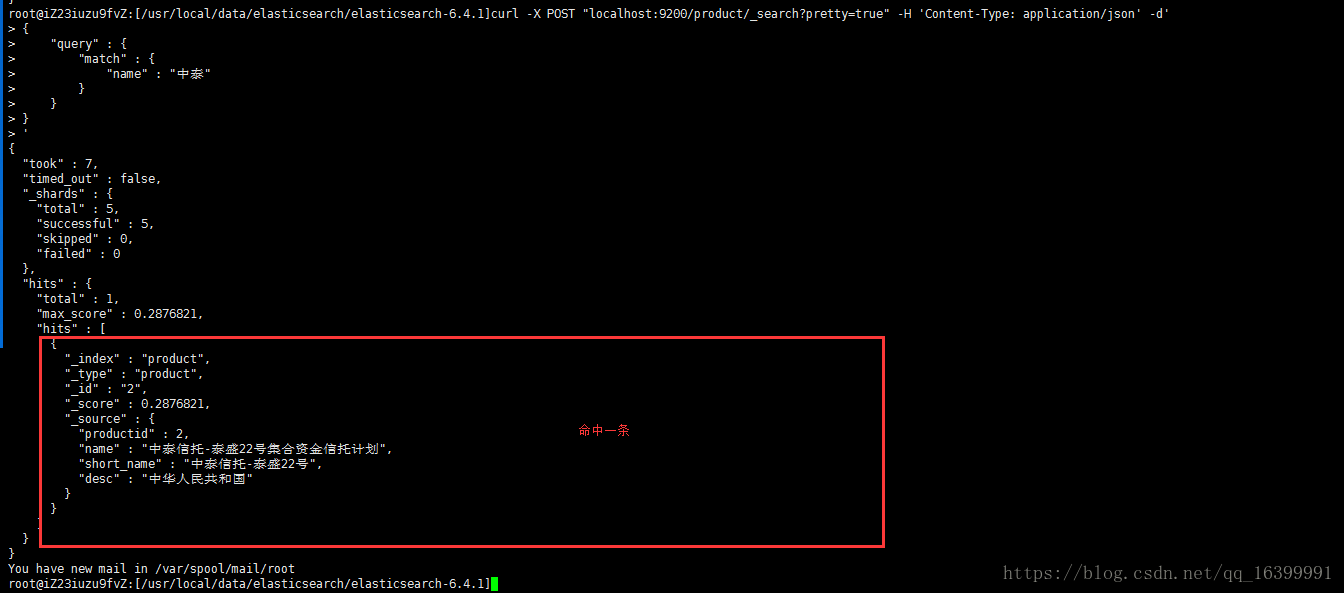
匹配单个name
curl -X POST "localhost:9200/product/_search?pretty=true" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : {
"name" : "中泰"
}
}
}
'
可以看到只返回了一条数据:
匹配多个字段
下边匹配desc 和short_name 为中华
curl -X POST "localhost:9200/product/_search?pretty=true" -H 'Content-Type: application/json' -d'
{
"query" : {
"multi_match" : {
"query":"中华",
"fields" : ["desc","short_name"]
}
}
}
'
返回结果如下:

ik还支持高亮信息,详情可参考ik官网。
------------------------
参考 阮一峰老师博客 :http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html