转载地址:https://blog.csdn.net/baimafujinji/article/details/50570824
聚类是将相似对象归到同一个簇中的方法,这有点像全自动分类。簇内的对象越相似,聚类的效果越好。支持向量机、神经网络所讨论的分类问题都是有监督的学习方式,现在我们所介绍的聚类则是无监督的。其中,K均值(K-means)是最基本、最简单的聚类算法。
学习更多机器学习算法原理并了解在R中如何实现机器学习的技术,你还可以参考我的《R语言实战:机器学习与数据分析》(电子工业出版社出版)一书。

在K均值算法中,质心是定义聚类原型(也就是机器学习获得的结果)的核心。在介绍算法实施的具体过程中,我们将演示质心的计算方法。而且你将看到除了第一次的质心是被指定的以外,此后的质心都是经由计算均值而获得的。
首先,选择K个初始质心(这K个质心并不要求来自于样本数据集),其中K是用户指定的参数,也就是所期望的簇的个数。每个数据点都被收归到距其最近之质心的分类中,而同一个质心所收归的点集为一个簇。然后,根据本次分类的结果,更新每个簇的质心。重复上述数据点分类与质心变更步骤,直到簇内数据点不再改变,或者等价地说,直到质心不再改变。
基本的K均值算法描述如下:
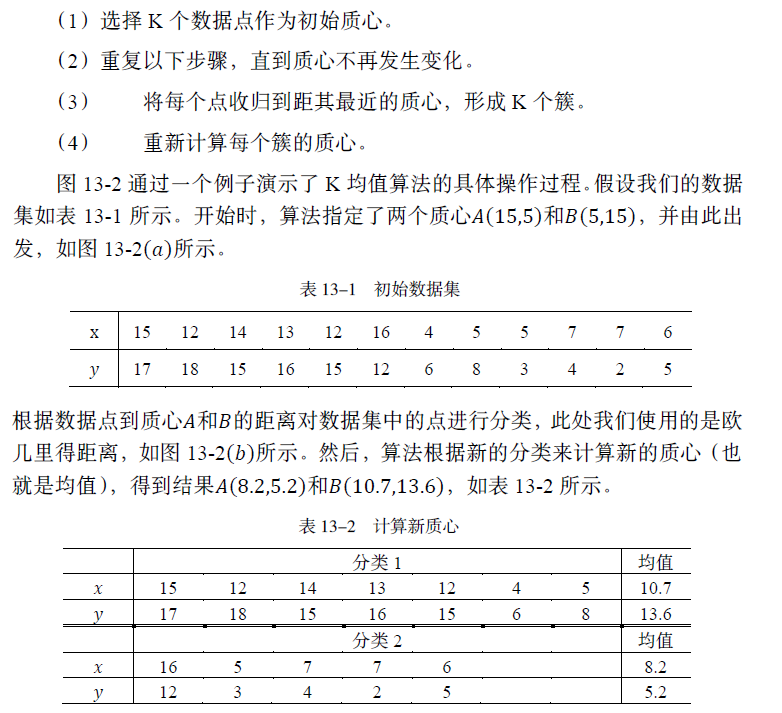
根据数据点到新质心的距离,再次对数据集中的数据进行分类,如图13-2(c)所示。然后,算法根据新的分类来计算新的质心,并再次根据数据点到新质心的距离,对数据集中的数据进行分类。结果发现簇内数据点不再改变,所以算法执行结束,最终的聚类结果如图13-2(d)所示。
对于距离函数和质心类型的某些组合,算法总是收敛到一个解,即K均值到达一种状态,聚类结果和质心都不再改变。但为了避免过度迭代所导致的时间消耗,实践中,也常用一个较弱的条件替换掉“质心不再发生变化”这个条件。例如,使用“直到仅有1%的点改变簇”。
尽管K均值聚类比较简单,但它也的确相当有效。它的某些变种甚至更有效, 并且不太受初始化问题的影响。但K均值并不适合所有的数据类型。它不能处理非球形簇、不同尺寸和不同密度的簇,尽管指定足够大的簇个数时它通常可以发现纯子簇。对包含离群点的数据进行聚类时,K均值也有问题。在这种情况下,离群点检测和删除大有帮助。K均值的另一个问题是,它对初值的选择是敏感的,这说明不同初值的选择所导致的迭代次数可能相差很大。此外,K值的选择也是一个问题。显然,算法本身并不能自适应地判定数据集应该被划分成几个簇。最后,K均值仅限于具有质心(均值)概念的数据。一种相关的K中心点聚类技术没有这种限制。在K中心点聚类中,我们每次选择的不再是均值,而是中位数。这种算法实现的其他细节与K均值相差不大,我们不再赘述。
最后我们给出一个实际应用的例子。(代码采用我最喜欢用做数据挖掘的R语言来实现)
一组来自世界银行的数据统计了30个国家的两项指标,我们用如下代码读入文件并显示其中最开始的几行数据。可见,数据共分三列,其中第一列是国家的名字,该项与后面的聚类分析无关,我们更关心后面两列信息。第二列给出的该国第三产业增加值占GDP的比重,最后一列给出的是人口结构中年龄大于等于65岁的人口(也就是老龄人口)占总人口的比重。

为了方便后续处理,下面对读入的数据库进行一些必要的预处理,主要是调整列标签,以及用国名替换掉行标签(同时删除包含国名的列)。

如果你绘制这些数据的散点图,不难发现这些数据大致可以分为两组。事实上,数据中有一半的国家是OECD成员国,而另外一半则属于发展中国家(包括一些东盟国家、南亚国家和拉美国家)。所以我们可以采用下面的代码来进行K均值聚类分析。
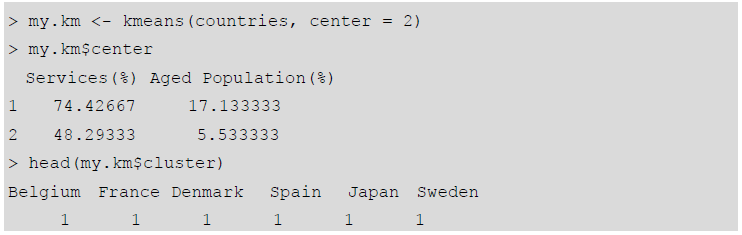
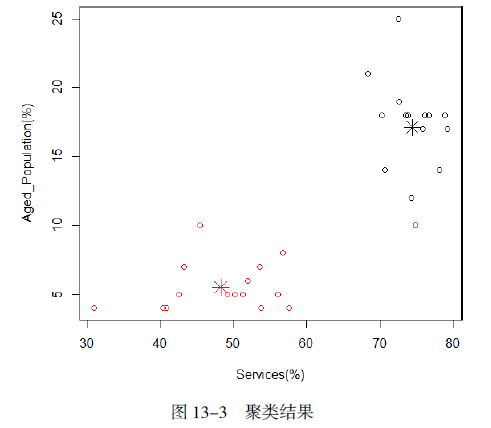
对于聚类结果,限于篇幅我们仍然只列出了最开始的几条。但是如果用图形来显示的话,可能更易于接受。下面是示例代码。

上述代码的执行结果如图13-3所示。
另外一种与k-means非常类似的算法是k-median算法。此处已经无需再详细介绍k-中值算法的细节了,基本上和k-means一样,只是把所有均值出现的地方换成中值而已。这个思想看起好像很不起眼,但是你还别说,k-median算法还真的存在,而且是k-means算法的一个重要补充和改进。
用python实现的代码入下:(详细代码见https://github.com/yantijin/Lean_DataMining)
#coding=utf-8
from collections import defaultdict
from math import sqrt
from random import uniform
"""
需要定义的函数:
计算聚类中心;
计算两点之间距离;
将所有点按照距离中心点的距离分类;
随机生成k个中心点
"""
"""
计算两点之间的距离
INPUT:
data1,data2: data of the point
OUTPUT:
distance between data1 and data2
"""
def get_distance(data1,data2):
dimensions = len(data1)
dis = 0
for dimension in range(dimensions):
dis =dis +(data1[dimension]-data2[dimension])**2
return sqrt(dis)
"""
计算聚类中心
INPUT:
data_set: an list consists of list
OUTPUT:
center: calculate center of the input datas
"""
def cal_center(data_set):
center = []
dimensions = len(data_set[0])
amount = len(data_set)
for dimension in range(dimensions):
point_sum = 0
for data in data_set :
point_sum = point_sum +data[dimension]
center.append(point_sum/amount)
return center
"""
根据现有分类,重新计算聚类中心
INPUT:
assignments: a list that assign each data to a center
data_set: an list consists of list
OUTPUT:
center: update center by the assignments and data_set
"""
def update_center(assignments, data_set):
center = []
dt = defaultdict(list)
for assignment, data in zip(assignments, data_set):
dt[assignment].append(data)
for points in dt.values():
center.append(cal_center(points))
return center
"""
将所有点按照距离中心点的距离分类
INPUT:
data_set: an list consists of list
center: clustering center until now
OUTPUT:
assignments: assign each data for a center
"""
def assign_point(data_set, center):
len_centers = len(center)
len_data_sets = len(data_set)
assignments = []
for len_data_set in range(len_data_sets):
shortest_dis = float("inf")
assignment = -1
for len_center in range(len_centers):
dis = get_distance(data_set[len_data_set], center[len_center])
if dis < shortest_dis :
shortest_dis = dis
assignment = len_center
assignments.append(assignment)
return assignments
"""
随机生成k个中心点
INPUT:
data_set: an list consists of list
k: num of centers that wants for clustering
OUTPUT:
init_center: init random center
"""
def generate_init_center(data_set, k):
dimensions = len(data_set[0])
center = []
min_max = defaultdict(float)
for data in data_set:
for dimension in range(dimensions):
min_key = 'min_%d' % dimension
max_key = 'max_%d' % dimension
val = data[dimension]
if min_key not in min_max or val < min_max[min_key]:
min_max[min_key] = val
if max_key not in min_max or val > min_max[max_key]:
min_max[max_key] = val
# 此步要产生k个在min和max之间的data
for _k in range(k):
data = []
for dimension in range(dimensions):
min_val = min_max['min_%d' % dimension]
max_val = min_max['max_%d' % dimension]
data.append(uniform(min_val, max_val))
center.append(data)
return center
"""
k_means算法实现
INPUT:
data_set: an list consists of list
k: num of centers that wants for clustering
OUTPUT:
"""
def kmeans(data_set, k):
center = generate_init_center(data_set, k)
assignments = assign_point(data_set, center)
new_center = update_center(assignments, data_set)
while new_center != center:
center = new_center
assignments = assign_point(data_set, center)
new_center = update_center(assignments, data_set)
return zip(assignments, data_set), new_center
"""
文件读写
"""
def fileread(filepath):
file_object = open(filepath)
data = []
data1 = []
try:
for line in file_object.readlines():
line.replace('\n', '', 1)
tmp = line.split(' ')
tmplen = len(tmp)
for nm in range(tmplen):
data1.append(float(tmp[nm]))
data.append(data1)
data1=[]
finally:
file_object.close()
return data
if __name__== "__main__":
filepath = input("请输入文件地址及命名\n")
data_set = fileread(filepath)
k = 3
zip, center = kmeans(data_set, k)
for i in zip:
print(i)
print(center)注意文件输入数据的格式应该按照如下来写,
3 3
4 10
9 6
14 8
18 11
21 7