【正规代孕生育中心】【微:13802269370】代孕包成功,代孕包性别,供卵代孕北京三代试管婴儿选性别,供卵试管婴儿代孕,十年老品牌代孕公司
生命不息,折腾不止,趁着最近工作不是太忙继续我的编程之路的学习。
年龄大了,很多东西做过一遍就容易忘记,所谓“好记性不如烂笔头”,对于知识还是记录下来比较容易保存,既是给自己留个笔记,也可以分享给其他有需要的人。废话少说,以下记录我的spark学习之旅:
一、准备工作
1.准备三台服务器.一台作为master,另外两台作为slave
我这里准备了三台服务器,对应的IP分别是
master:10.10.10.88;
slave1:10.10.20.18,
slave2:10.10.20.19
2.分别修改三台服务器的hosts文件,具体如下:
vim /etc/hosts
127.0.0.1 localhost 10.10.10.88 spark-master 10.10.11.18 spark-slave1 10.10.11.19 spark-slave2
3.设置免密登陆,生成公钥和私钥
登陆master机器,执行如下命令
[root@spark-master /]# ssh-keygen -t rsa
一直敲回车,最后生成密钥

Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): /root/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:Nn0sHWtXvvMtgVaDyr2NlBha3RCDiHo4MNgpWkxFUOg root@VM_10_45_centos The key's randomart image is: +---[RSA 2048]----+ | =oB+ . . .o. | |o O . . . .. | |.+ o o ..+ .| |. E + . .oooo+o | | o S+o=*+...| | ...++*.. .| | o + + | | o o +| | .o| +----[SHA256]-----+ [root@spark-master /]#
4. 将上一步中生成的公钥文件分别复制到slave1和slave2服务器上
[root@spark-master data]# scp /root/.ssh/id_rsa.pub [email protected]:/data/ [root@spark-master data]# scp /root/.ssh/id_rsa.pub [email protected]:/data/
分别进入slave1和slave2服务器器,将公钥导入授权文件中
[root@spark-slave1 /]# cd data [root@spark-slave1 data]# ls id_rsa.pub [root@spark-slave1 data]# cat id_rsa.pub >> /root/.ssh/authorized_keys
返回master服务器,测试授权是否成功
#测试slave1 [root@spark-master ~]# ssh spark-slave1 Last login: Mon Oct 15 15:46:27 2018 from 10.10.10.88
#测试slave2 [root@spark-master ~]# ssh spark-slave2 Last login: Mon Oct 15 15:56:30 2018 from 10.10.10.88
5.安装jdk
检查一下是否安装jdk,如果没有请先安装,我这里因为已经安装好jdk,所以就略去了安装的步骤,如果没有安装过的请自己上网查找。
[root@spark-master ~]# java -version java version "1.8.0_152" Java(TM) SE Runtime Environment (build 1.8.0_152-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode) [root@spark-master_centos ~]#
6.scala安装与配置
1.下载
scala官网下载地址:https://www.scala-lang.org/download/,找到要下载的版本,我这里选择的是scala-2.12.7.tgz。我在下载过程中一直失败,然后网上查了下,有人说把地址换成 http://downloads.typesafe.com/scala/2.12.7/scala-2.12.7.tgz,PS:后面的版本号可以根据实际情况自己更改,果然很快就下载好了。
2.安装与配置
#切换到scala安装目录 [root@spark-master ~]# cd /opt/scala/ #解压安装包 [root@spark-master scala]# tar -xvf scala-2.12.7.tgz -C /opt/scala/ scala-2.12.7/ scala-2.12.7/man/ scala-2.12.7/man/man1/ scala-2.12.7/man/man1/fsc.1 scala-2.12.7/man/man1/scalac.1 scala-2.12.7/man/man1/scalap.1 scala-2.12.7/man/man1/scaladoc.1 scala-2.12.7/man/man1/scala.1 scala-2.12.7/doc/ scala-2.12.7/doc/licenses/ scala-2.12.7/doc/licenses/mit_tools.tooltip.txt scala-2.12.7/doc/licenses/mit_jquery.txt scala-2.12.7/doc/licenses/bsd_asm.txt scala-2.12.7/doc/licenses/bsd_jline.txt scala-2.12.7/doc/licenses/apache_jansi.txt scala-2.12.7/doc/License.rtf scala-2.12.7/doc/README scala-2.12.7/doc/LICENSE.md scala-2.12.7/doc/tools/ scala-2.12.7/doc/tools/scala.html scala-2.12.7/doc/tools/css/ scala-2.12.7/doc/tools/css/style.css scala-2.12.7/doc/tools/index.html scala-2.12.7/doc/tools/scaladoc.html scala-2.12.7/doc/tools/scalap.html scala-2.12.7/doc/tools/scalac.html scala-2.12.7/doc/tools/images/ scala-2.12.7/doc/tools/images/external.gif scala-2.12.7/doc/tools/images/scala_logo.png scala-2.12.7/doc/tools/fsc.html scala-2.12.7/bin/ scala-2.12.7/bin/scalap.bat scala-2.12.7/bin/scala scala-2.12.7/bin/scalac.bat scala-2.12.7/bin/fsc.bat scala-2.12.7/bin/scaladoc.bat scala-2.12.7/bin/scala.bat scala-2.12.7/bin/scalap scala-2.12.7/bin/scalac scala-2.12.7/bin/fsc scala-2.12.7/bin/scaladoc scala-2.12.7/lib/ scala-2.12.7/lib/scala-library.jar scala-2.12.7/lib/scala-compiler.jar scala-2.12.7/lib/jline-2.14.6.jar scala-2.12.7/lib/scala-reflect.jar scala-2.12.7/lib/scalap-2.12.7.jar scala-2.12.7/lib/scala-swing_2.12-2.0.3.jar scala-2.12.7/lib/scala-parser-combinators_2.12-1.0.7.jar scala-2.12.7/lib/scala-xml_2.12-1.0.6.jar #编辑配置文件 [root@spark-master scala]# vim /etc/profile #在文件中增加如下环境变量的配置 export SCALA_HOME=/opt/scala/scala-2.12.7 export PATH=$PATH:$SCALA_HOME/bin
#然后ESC,并wq!保存后退出编辑 #使环境变量生效 [root@spark-master scala]# source /etc/profile #检查配置是否成功 [root@spark-master scala]# scala -version Scala code runner version 2.12.7 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc. [root@spark-master scala]#
安装配置完成之后,按照同样的步骤安装到另外两台slave机器上。
二、hadoop分布式安装与配置
1.下载hadoop
hadoop可以通过Apache的官网进行下载,我这里选择的是2.8.5版本https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz ,下载时请选择 hadoop-2.x.y.tar.gz这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
2.把安装文件上传到目标服务器
首先把hadoop安装文件上传到master服务器的/opt/hadoop目录里,然后再分别拷贝到slave1和slave2服务器上
#从master服务器拷贝到slave1服务器上
[root@spark-master ~]# scp /opt/hadoop/hadoop-2.8.5.tar.gz root@spark-slave1:/opt/hadoop/hadoop-2.8.5.tar.gz 100% 235MB 117.1MB/s 00:02
#从master服务器拷贝到slave2服务器上
[root@spark-master ~]# scp /opt/hadoop/hadoop-2.8.5.tar.gz root@spark-slave2:/opt/hadoop/ hadoop-2.8.5.tar.gz 100% 235MB 108.0MB/s 00:02
[root@spark-master ~]#
3.解压并安装文件
#解压安装包到/opt/hadoop目录下
[root@spark-master ~]# tar -xvf /opt/hadoop/hadoop-2.8.5.tar.gz -C /opt/hadoop/
4.配置hadoop环境变量
#编辑/etc/profile文件 [root@spark-master ~]# vi /etc/profile #在文件后面增加以下配置项 export HADOOP_HOME=/opt/hadoop/hadoop-2.8.5 export PATH==$PATH:$HADOOP_HOME/bin
5.修改配置文件
一共需要修改6个配置文件,位于安装路径下etc/hadoop目录下. 分别是hadoop-env.sh、core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml和slaves文件
(1).修改hadoop-env.sh文件
#编辑hadoop-env.sh文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.sh [root@spark-master ~]#
#修改JAVA_HOME为本机配置的jdk路径
export JAVA_HOME=/usr/java/jdk1.8.0_152
(2).修改core-site.xml文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/core-site.xml
#增加如下配置
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark-master:9100</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-dir</value>
</property>
</configuration>
(3).修改hdfs-site.xml文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/hdfs-site.xml
#增加如下配置
<configuration>
<property>
<name>dfs.name.dir</name>
<value>file:/tmp/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:/tmp/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 如果没有配置以下项则启动时会出现类似secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode 这种错误-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>spark-master:50090</value>
</property>
</configuration>
(4).修改mapred-site.xml文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/mapred-site.xml
#增加如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- history服务器信息-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>spark-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>spark-master:19888</value>
</property>
</configuration>
(5).修改yarn-site.xml文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/yarn-site.xml
#增加如下配置项
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 是否开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志服务器的地址,work节点使用 -->
<property>
<name>yarn.log.server.url</name>
<value>http://spark-master:19888/jobhistory/logs/</value>
</property>
<!-- 配置日志过期时间,单位秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>spark-master:8099</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark-master</value>
</property>
</configuration>
(6).修改slaves文件
[root@spark-master ~]# vi /opt/hadoop/hadoop-2.8.5/etc/hadoop/slaves #增加如下配置项 spark-slave1 spark-slave2
(7).以上6个文件修改好之后把master服务器上最新文件同步到slave1和slave2的安装目录下,并覆盖掉之前的
[root@spark-master hadoop]# scp hadoop-env.sh root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.sh 100% 46 2.3MB/s 00:00 [root@spark-master hadoop]# scp hadoop-env.sh root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.sh [root@spark-master hadoop]# scp core-site.xml root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/core-site.xml 100% 46 2.1MB/s 00:00 [root@spark-master hadoop]# scp core-site.xml root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/core-site.xml 100% 1114 683.1KB/s 00:00 [root@spark-master hadoop]# scp hdfs-site.xml root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/hdfs-site.xml 100% 1278 750.7KB/s 00:00 [root@spark-master hadoop]# scp hdfs-site.xml root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/hdfs-site.xml 100% 1278 2.0MB/s 00:00 [root@spark-master hadoop]# scp mapred-site.xml root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/mapred-site.xml 100% 1146 2.3MB/s 00:00 [root@spark-master hadoop]# scp mapred-site.xml root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/mapred-site.xml 100% 1146 699.1KB/s 00:00 [root@spark-master hadoop]# scp yarn-site.xml root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/yarn-site.xml 100% 1649 3.3MB/s 00:00 [root@spark-master hadoop]# scp yarn-site.xml root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/yarn-site.xml 100% 1649 882.5KB/s 00:00 [root@spark-master hadoop]# scp slaves root@spark-slave1:/opt/hadoop/hadoop-2.8.5/etc/hadoop/slaves 100% 36 93.0KB/s 00:00 [root@spark-master hadoop]# scp slaves root@spark-slave2:/opt/hadoop/hadoop-2.8.5/etc/hadoop/slaves
(8).初始化namenode
[root@spark-master ~]# hdfs namenode -format 18/10/17 11:28:08 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: user = root STARTUP_MSG: host = spark-master/127.0.0.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.8.5 #后面还有一大串信息,这里略去。。。。。。。。。。。。。。。。。。。。。。。。。。
6.启动hadoop集群
#cd到hadoop安装路径下的/opt/hadoop/hadoop-2.8.5/sbin目录
[root@spark-master sbin]# ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [spark-master] root@spark-master's password: spark-master: starting namenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-namenode-spark-master.out spark-slave1: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-spark-slave1.out spark-slave2: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-spark-slave2.out Starting secondary namenodes [spark-master] root@spark-master's password: spark-master: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-secondarynamenode-spark-master.out starting yarn daemons starting resourcemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-resourcemanager-spark-master.out spark-slave2: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-spark-slave1.out spark-slave1: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-spark-slave2.out [root@spark-master sbin]#
7.查看hadoop运行节点
通过浏览器查看HDFS信息 ,在浏览器中输入http://10.10.10.88:50070
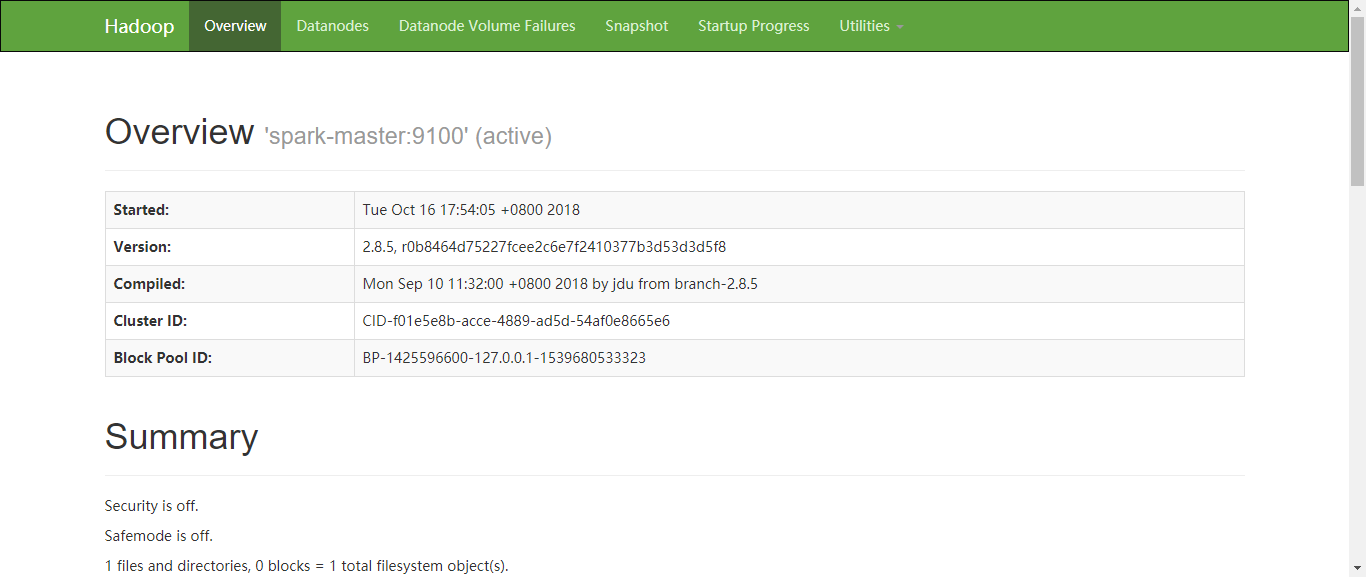
通过浏览器查看Yarn信息,在浏览器中输入http://10.10.10.88:8099
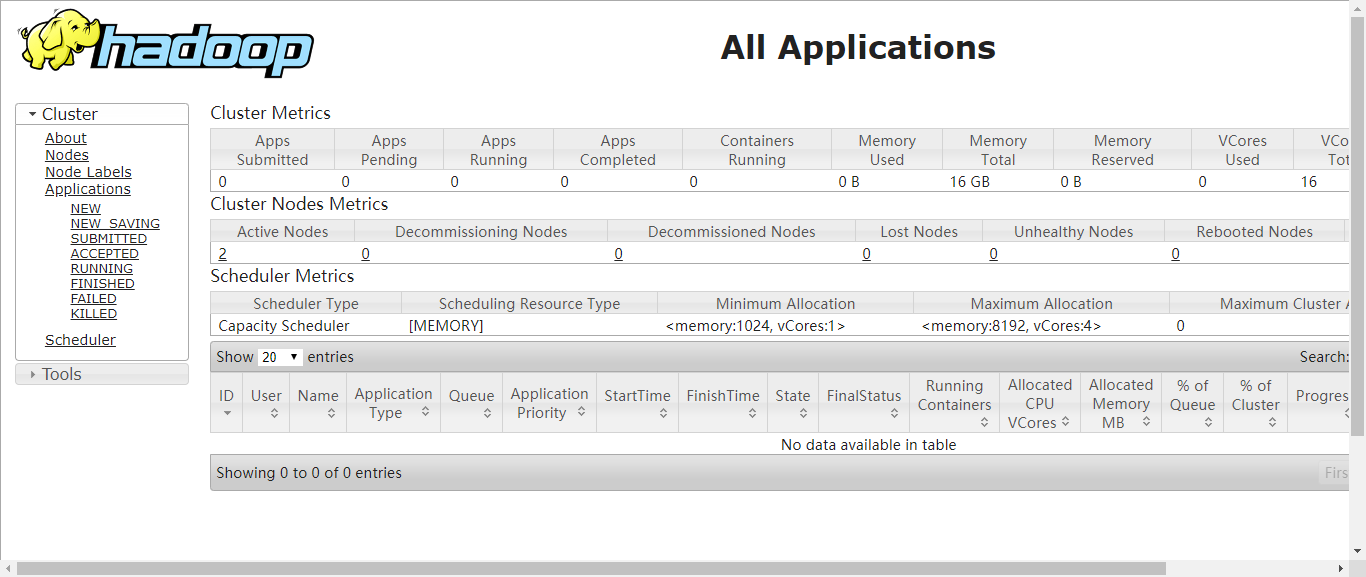
至此hadoop分布式集群的安装与配置已经完成,下一步会进行spark的安装与配置。