原文链接:https://proandroiddev.com/improving-proguard-name-obfuscation-83b27b34c52a
改进ProGuard名称混淆
文中,我将展示如何加强ProGuard的名称模糊处理,使攻击者难以对代码进行逆向工程,以及如何有助于防止不正确混淆造成的许多错误。
告诉你一个秘密:ProGuard实际上是一个代码优化器。其中一个优化的副作用恰恰是给结果字节码添加了一些名称混淆,即类和方法名称的短接和重用。实际的好处是,生成的二进制文件更小和更好的可压缩性(更小的二进制文件可以更快加载到堆中,即减少延迟)。
ProGuard名称混淆是如何工作的
ProGuard使用字典来定义要重命名包,类或方法的内容。有一个默认字典只包含字母a-z。
考虑下面这个类:
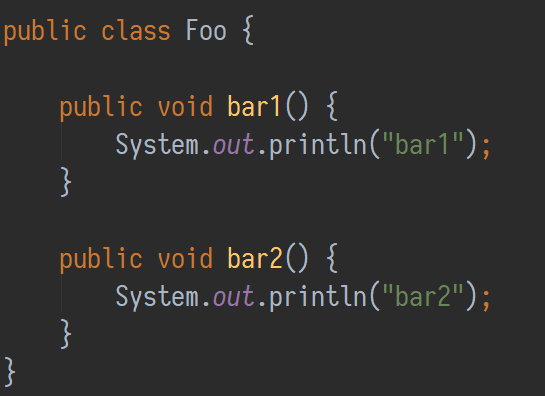
使用ProGuard优化时,从处理Foo.class开始。ProGuard会检查它的字典,第一个条目是字母a。这个包里没有这个名字的类,所以Foo.class被命名为a.class。接下来是方法的重命名:使用相同的策略,bar1()变成a(),bar2()变成b()。结果类的Java语法表示如下所示:

现在如果你添加一个新类Foobar.class,它被命名为b.class等等。如果包中有26个以上的类,名字会变长:aa.class,ab.class等。
防止确定性名称混淆
名称混淆处理是确定性的。有一个预定义顺序(我猜这是词典学),因此Foo.class仍然是a.class,在添加第二个类后,方法仍然分别是a()和b()。这并不意味着永远不变。如果添加了一个类,这个类按顺序排列位于其他类的中间,则混淆映射将会改变,但通常情况下该映射在构建中会保持不变。
从安全角度来看,这不是最佳选择。例如,如果攻击者知道应用程序的版本1中a.b()是许可证检查逻辑,如果它仍然是a.b(),那么在版本2中很容易找到相同的逻辑。
使用自定义名称混淆字典
ProGuard允许定义如下字典:(参见官方手册获取更多信息)
-obfuscationdictionary method-dictionary.txt
-packageobfuscationdictionary package-dictionary.txt
-classobfuscationdictionary class-dictionary.txt格式只是一个简单的文本文件,每行都有一个条目,忽略以#开头的行和空行。
# A custom method dictonary
NUL
CoM4
COm9
lpt2
com5有可能对这些文件有一点乐趣。 例如,在ProGuard发行版中,有一些替代字典的例子。这个文件包含的名称将使得无法从Windows中提取包中的类(例如.jar),因为它会创建非法的文件名。另一个版本经过优化,可以通过在字节码格式中使用常见的小关键字来实现尽可能最好的压缩。另一种选择是使用Java关键字作为类和方法名称,这些名称在字节码格式中允许创建非常令人困惑的调用堆栈。
无论哪种方式,这都会有点改善名称混淆,但如果它是完全确定性的,我们仍然存在问题。
随机化字典
Eric Lafortune,ProGuard(和商业版本DexGuard)的作者打算混淆是确定的(请参阅此特性的关于字典随机化的请求),但有一个简单的技巧可以解决这个问题:在我们的构建工具中, 在执行ProGuard前,只需生成一个随机字典文件。
以Android Gradle构建过程为例,可以在ProGuard任务之前动态添加运行的任务:
tasks.whenTaskAdded { currentTask ->
//Android Gradle plugin may change this task name in the future
def prefix = 'transformClassesAndResourcesWithProguardFor'
if (currentTask.name.startsWith(prefix)) {
def taskName = currentTask.name.replace(prefix,
'createProguardDictionariesFor')
task "$taskName" {
doLast {
createRandomizedDictonaries()
}
}
//append scramble task to proguard task
currentTask.dependsOn "$taskName"
}
}现在,任务在中需要做如下操作:
- 从临时文件读取所有可能的字段条目
- 对输入项目进行洗牌; 不要选择100%的输入,而是选择例如100%的随机数。60-90%,因此映射不能在构建之间轻松转换将条目写入文件
- 使用
-obfuscationdictionary将文件引用ProGuard中 - 对类字典
-classobfuscationdictionary重复上述步骤
附加功能
建议的另一个功能是可以将所有类重新打包为一个包。这个配置会将所有的类移动到一个根级包o
-repackageclasses 'o'这也可以用上述类似的逻辑动态设置。
为了更容易的调试,您可以打印出组装好的ProGuard配置文件(使用多个配置文件时)
-printconfiguration proguard-merge-config.txt使用随机名称混淆的结果
请注意,每个构建版本都会有一个实际上独特的混淆映射。所以在Android构建中,每个构建变体(flavor或构建类型)将创建非常不同的调用栈。因此,请小心保留Gradle中所有版本,flavor和构建类型的所有映射以及Maven中的所分类器。
但这不是一个缺点。许多Android开发者至少经历过一次的错误:持续混淆名称,这使得迁移变得不可能。这通常发生在使用Json数据绑定序列化器时,它通过反射读取类和方法名并转换它们,或者使用*.getClass().getName()与SharedPreferences或Databases一起使用。最糟糕的部分是:通常不会被注意到,因为名称混淆映射可能会保留相同的版本。例如
{
"xf": {
"a": "Foo",
"ce": {
"tx": [{
"by": "Foobar",
"bv": 137
}]
}
}
}通过强制每次构建不同的映射,像这样的错误将立即出现,实质上为ProGuard映射创建了快速失败功能。
总结
- ProGuard的名称混淆是确定性的,因此,当代码只有一点变化时,映射通常在多个版本中保持不变
- 可为混淆创建随机字典并告诉ProGuard使用它们,因此每个构建都将具有唯一的映射,这使得攻击者难以对代码进行反向工程
- 随机名称混淆还具有充当常见的ProGuard配置问题的故障快速处理的优点