版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_37050372/article/details/83096397
我们之前的OffSet都是交给broker自己管理的,现在我们希望自己管理。
我们可以通过zookeeper进行管理。
我们在程序中想要使用zookeeper,那么就肯定会有api允许我们操作。
new ZKGroupTopicDirs()注意:这里使用客户端的时候导包为:
import org.I0Itec.zkclient.ZkClient
我们可以看到这个api需要两个参数,
一个是group的id另一个就是topic主题
他返回的其实就是一个拼接的字符串,我们可以看一下源码:

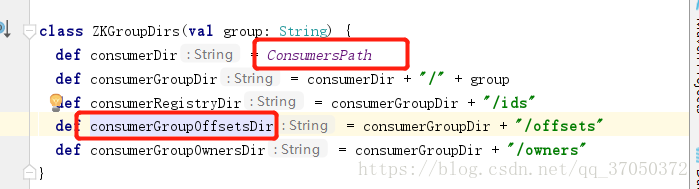
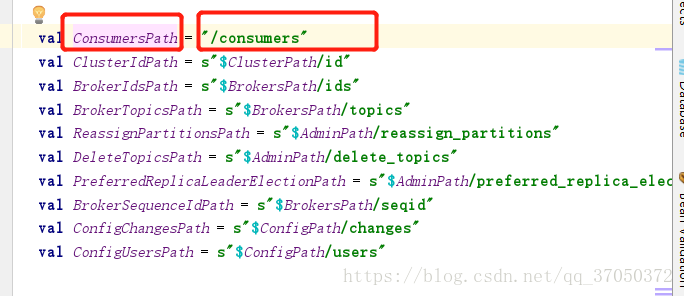
生成的目录结构
* /customer/g100/offsets/wordcount这里拼接的字符串是不包括分区的,因为这个分区是动态值。
/**
* 如果我们自己维护偏移量
* 问题:
* 1.程序在第一次启动的时候,应该从什么开始消费数据?earliest
* 2.程序如果不是第一次启动的话,应该从什么位置开始消费数据?
* 上一次自己维护的偏移量接着往后消费,比如上一次存储的offset=88
*/那么我们如何判断是否是第一次连接呢?
我们可以去zookeeper目录下看一下:

我们可以看到暂时consumer目录下只有这两个。
所以我们判断程序是否第一次执行,我们只需要判断这个目录底下有没有生成我们的新目录即可。
我们这里设置的groupId是g100
所以我们需要判断的是
/customer/g100/offsets/wordcount下面有没有孩子节点,如果有,说明之前维护过偏移量,如果没有的话说明程序是第一次执行。
如果是之前启动过则在该目录下会有生成好的序列的分区号。
类似于这样:
代码如下:
package com.test.sparkStreaming
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.common.TopicPartition
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.kafka.common.serialization.StringDeserializer
object KafkaDirect_ZK_Offset {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf: SparkConf = new SparkConf().setAppName("KafkaDirect_ZK_Offset").setMaster("local[*]")
val ssc: StreamingContext = new StreamingContext(conf,Seconds(5))
val groupId = "g100"
/**
* kafka参数列表
*/
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> "marshal:9092,marshal01:9092,marshal02:9092,marshal03:9092,marshal04:9092,marshal05:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false:java.lang.Boolean)
)
val topic = "wordcount"
val topics = Array(topic)
/**
* 如果我们自己维护偏移量
* 问题:
* 1.程序在第一次启动的时候,应该从什么开始消费数据?earliest
* 2.程序如果不是第一次启动的话,应该从什么位置开始消费数据?
* 上一次自己维护的偏移量接着往后消费,比如上一次存储的offset=88
*/
val zKGroupTopicDirs: ZKGroupTopicDirs = new ZKGroupTopicDirs(groupId,topic)
/**
* 生成的目录结构
* /customer/g1/offsets/wordcount
*/
val offsetDir: String = zKGroupTopicDirs.consumerOffsetDir
//zk字符串连接组
val zkGroups = "marshal:2181,marshal01:2181,marshal02:2181,marshal03:2181,marshal04:2181,marshal05:2181"
//创建一个zkClient连接
val zkClient: ZkClient = new ZkClient(zkGroups)
//子节点的数量
val childrenCount: Int = zkClient.countChildren(offsetDir)
//子节点的数量>0就说明非第一次
val stream = if(childrenCount>0){
println("已经启动过")
//用来存储我们已经读取到的偏移量
var fromOffsets = Map[TopicPartition,Long]()
(0 until childrenCount).foreach(partitionId => {
val offset = zkClient.readData[String](offsetDir+s"/$partitionId")
fromOffsets += (new TopicPartition(topic,partitionId) -> offset.toLong)
})
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Assign[String,String](fromOffsets.keys.toList,kafkaParams,fromOffsets)
)
}
else{
println("第一次启动")
KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](topics,kafkaParams)
)
}
stream.foreachRDD(
rdd => {
//转换rdd为Array[OffsetRange]
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))
//计算逻辑
maped.foreach(println)
//自己存储数据,自己管理
for(o <-offsetRanges){
//写入到zookeeper,第二个参数为是否启动安全
ZkUtils(zkClient,false).updatePersistentPath(offsetDir+"/"+o.partition,o.untilOffset.toString)
}
}
)
ssc.start()
ssc.awaitTermination()
}
}第一次执行结果如下:


我们再看zookeeper的目录:
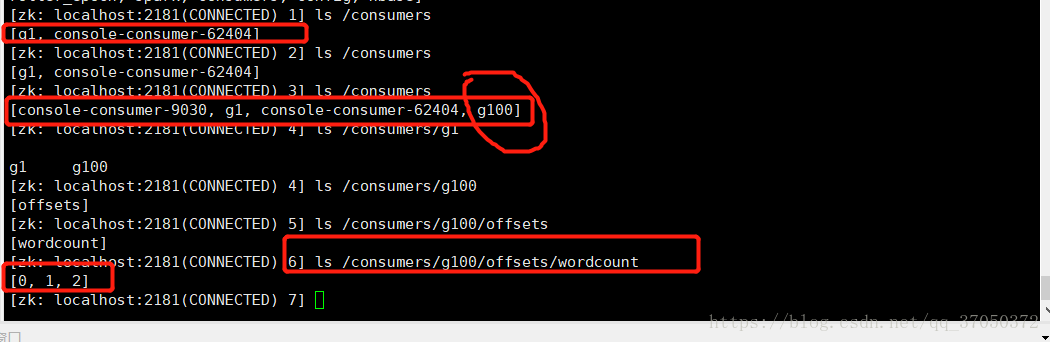
然后我们第二次执行,结果如下:

已经消费过的数据就不会再消费了。