理解web路由:
路由:URL到函数的映射
Router与route:
Route是一条路由:
如:/users - - > 调用 getAllUsers()函数
/users/count/ - - > 调用 getUsersCount()函数
就是把路径与函数进行一一对应,通过路径信息调用特定的函数
Routers则负责管理route与函数之间的映射关系

服务器路由:(此部分为转载)
以Express为例,
app.get('/', (req, res) => {
res.sendFile('index')
})
app.get('/users', (req, res) => {
db.queryAllUsers()
.then(data => res.send(data))
})这里定义了两条路由:
- 当访问/的时候,会返回index页面
- 当访问/users的时候,会从数据库中取出所有用户数据并返回
客户端路由:
客户端常为浏览器,路由的映射函数一般是对DOM的操作,不同的路径显示不同的页面组件:
(1)基于Hash
Hash路由兼容性更好
url中的#后面部分为hash:
实例:
const url = require('url')
var result = url.parse('http://example.com/a/b/#/foo/bar')
console.log(result)
运行结果:
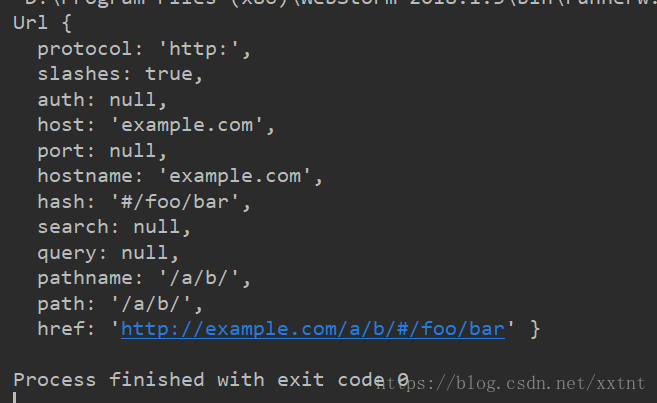
可以通过键值对的方式获取想要的结果,如果获取Hash的内容:
则可以调用result.hash 或者 result[‘hash’]
Hash实现路由的时候,会触发hashchange事件,引起hash值的变化,从而加载出不同的dom
实例:
window.onhashchange = function() {
var hash = window.location.hash;
var path = hash.substring(1);
switch (path) {
case '/':
showHome();
break;
case '/users':
showUsersList();
break;
default:
show404NotFound();
}
};
实现简单的路由,监听window.onhashchange事件来实现:
当路径为“/”调用首页
当路径为”/users”调用用户列表
其他的,则返回404页面
String.substring(arg1,arg2);
参数1为起始索引值,参数2位结束索引值,返回两个索引值之间的字符,包含第一个参数指向的字符,不包含第二个参数指向的字符。
实例:
var string = "halleo ";
var str1 = string.substring(1);
运行结果:
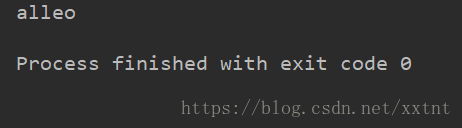
当只有一个参数时,返回当前参数的索引值(包括)指向的字符到结尾所有字符
var string = "halleo ";
var str1 = string.substring(4,-1);
console.log(str1);
运行结果:
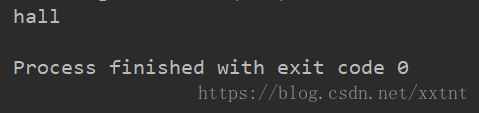
当第二个参数为负数(不论值为多少),返回开始到第一个参数(正数)指向的索引值的字符(不包括)。
var string = "halleo ";
var str1 = string.substring(-1,-6);
console.log(str1);
运行结果:
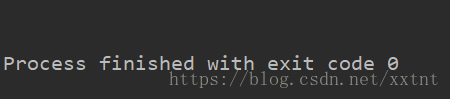
当两结果都为负数时,返回空字符串
var string = "halleo ";
var str1 = string.substring(0,10);
console.log(str1);
运行结果:

当结尾指向的索引值大于字符串的范围,则返回从开始索引值指向的字符到后面所有字符
基于History API
基于Hisotry API的路由更加直观
HTML5 History API可以在不刷新页面的情况下,直接改变URL,可以通过监听popstate事件。
Popstate事件:
当活动历史记录条目更改是,会触发该事件,popstate事件的state属性包含历史条目的状态对象的副本
调用history.pushState()或者是history.replaceState()不会触发popstate事件,只有用户点击浏览器的回退按钮、或者是调用history.back()函数
区别:(转载)
假设服务器只有如下文件(script.js被index.html所引用):
/-
|- index.html
|- script.js
基于Hash的路径有:
http://example.com/
http://example.com/#/foobar
基于History API的路径有:
http://example.com/
当直接访问http://example.com/的时候,两者的行为是一致的,都是返回了index.html文件。
当从http://example.com/跳转到http://example.com/#/foobar或者http://example.com/foobar的时候,也都是正常的,因为此时已经加载了页面以及脚本文件,所以路由跳转正常。
当直接访问http://example.com/#/foobar的时候,实际上向服务器发起的请求是http://example.com/,因此会首先加载页面及脚本文件,接下来脚本执行路由跳转,一切正常。
当直接访问http://example.com/foobar的时候,实际上向服务器发起的请求也是http://example.com/foobar,然而服务器端只能匹配/而无法匹配/foobar,因此会出现404错误。
因此如果使用了基于History API的路由,需要改造服务器端,使得访问/foobar的时候也能返回index.html文件,这样当浏览器加载了页面及脚本之后,就能进行路由跳转了。
动态路由:
以上内容都是静态内容,静态内容的路由都是固定的。
动态的内容则不是,我们可以通过传递参数而获取某个用户的信息,而不是单独设置一条静态路由。
例如:
Express
App.get(‘user/:id’,(req,res,next) =>{
//……
});
Flask:
@app.route('/user/<user_id>');
def get_user_info(user_id):
pass
/foobar和/foobar/比较类似,具体行为根据服务器的实习来看
在Express中两者几乎一致,而在flask中类似lunix末尾有斜线表示文件夹,没有则表示文件
(转载例子)
Server.js的代码
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
router.js代码
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
index.js代码
var server = require("./server");
var router = require("./router");
server.start(router.route);
在router.js创建映射的函数和关系,