elasticsearch原理
Master/Slave架构 VS P2P 环形结构
Master-Slave
master 节点负责管理整个系统,监视 slave 节点的运行状态,同时为其下的每一个 slave 节点分配存储的范围,是查询和写入的入口.master 节点一般全局只有 1个,该节点的状态将严重影响整个系统的性能,当 master 节点宕机时,会引起整个系统的瘫痪.实践中,经常设置多个副本 master 节点,通过联机热备的方式提高系统的容错性.P2P 环形结构
P2P结构中没有master节点
Master-Slave结构的系统设计简单,可控性好,但 master
中心节点易成为瓶颈(bigtable为master节点不成为瓶颈做了很多措施);P2P环形结构的系统无中心节点,自协调性好,扩展方便,但可控性较差,且系统设计比master-slave 结构的系统要复杂.
Hbase,bigtable,es和HDFS一样采用master/slave架构。
hbase存多读少,不适合高并发查询,适合存数据; es是全文检索,适合日志分析日志统计之类。
es概述
ES 在 Master 被选举之前是一个 P2P 的系统,但是当 Master 被选取后,它的管理本质上是 Master 和 slave的模式。
Elasticsearch 看名字就能大概了解下它是一个弹性的搜索引擎。首先弹性隐含的意思是分布式,单机系统是没法弹起来的,然后加上灵活的伸缩机制,就是这里的 Elastic 包含的意思。它的搜索存储功能主要是 Lucene 提供的,Lucene 相当于其存储引擎,它在之上封装了索引,查询,以及分布式相关的接口。
Elasticsearch是一个实时(索引数据到能被搜索大概1s左右)的分布式搜索和分析引擎,主要用于全文搜索,结构化搜索以及分析。Elasticsearch使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理,可以说是一个开箱即用的分布式实现,其内部定义了大量的默认值。Elasticsearch并不仅仅是Lucene这么简单,它不但包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
扫描二维码关注公众号,回复: 3646020 查看本文章
ES提供了两套API(内部调用都指向同一个地方)分别是基于curl的rest API和Java API,通过API不仅能对数据的CURD进行处理,还能对索引及es集群进行关联
es的基本概念
Elasticsearch的底层搜索是以lucene来实现的。es其主要是提供了一个分布式的框架来扩展了lucene,从而实现大数据量的,分布式搜索功能。其实现思想很简单,将大数据量分而治之,哈希分成多份,然后对每一份进行“lucene处理”——用lucene索引、检索,最后将每份结果合并返回。
Lucene中包含了四种基本数据类型,分别是:
Index:索引,由很多的Document组成。
Document:由很多的Field组成,是Index和Search的最小单位。
Field:由很多的Term组成,包括Field Name和Field Value。
Term:由很多的字节组成。一般将Text类型的Field Value分词之后的每个最小单元叫做Term。

es 中的几个核心概念
- 集群(Cluster)一组拥有共同的 cluster name 的节点。
- 节点(Node) 集群中的一个 Elasticearch 实例。
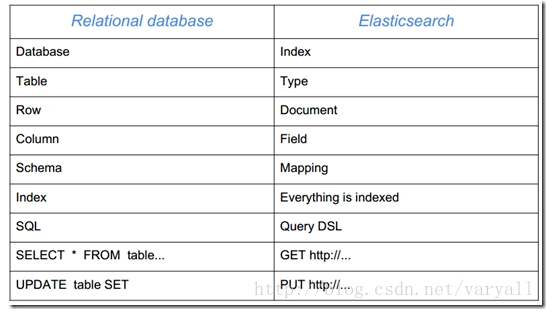
- 索引(Index) 相当于关系数据库中的database概念,一个集群中可以包含多个索引。这个是个逻辑概念。
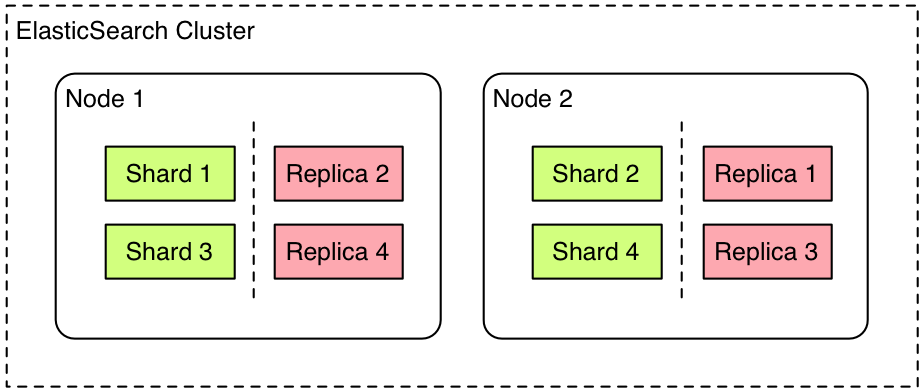
- 主分片(Primary shard) 索引的子集,索引可以切分成多个分片,分布到不同的集群节点上。分片对应的是 Lucene 中的索引。
- 副本分片(Replica shard)每个主分片可以有一个或者多个副本。
- 类型(Type)相当于数据库中的table概念,mapping是针对 Type 的。同一个索引里可以包含多个 Type。
- Mapping 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建。
- 文档(Document) 相当于数据库中的row。
- 字段(Field)相当于数据库中的column。
- 分配(Allocation) 将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。
- gateway: 代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
es的索引数据结构
传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用倒排索引(inverted index)来达到相同目的,倒排索引中用到的数据结构是FST树
es优点
elasticsearch主要优势是:速度快,使用方便,分布式的,检索,功能强大。
ES官方的想做的是ELK结合起来做日志分析等工作。估计这也是它最多的应用场景。
Elasticsearch 现在的主要目标市场已经从站内搜索转移到了监控与日志数据的收集存储和分析,也就是大家常谈论的ELK。
Elasticsearch 现在主要的应用场景有三块。站内搜索,主要和 Solr 竞争,属于后起之秀。NoSQL json文档数据库,主要抢占 Mongo 的市场,它在读写性能上优于 Mongo,同时也支持地理位置查询,还方便地理位置和文本混合查询,属于歪打正着。监控,统计以及日志类时间序的数据的存储和分析以及可视化,这方面是引领者。
es架构
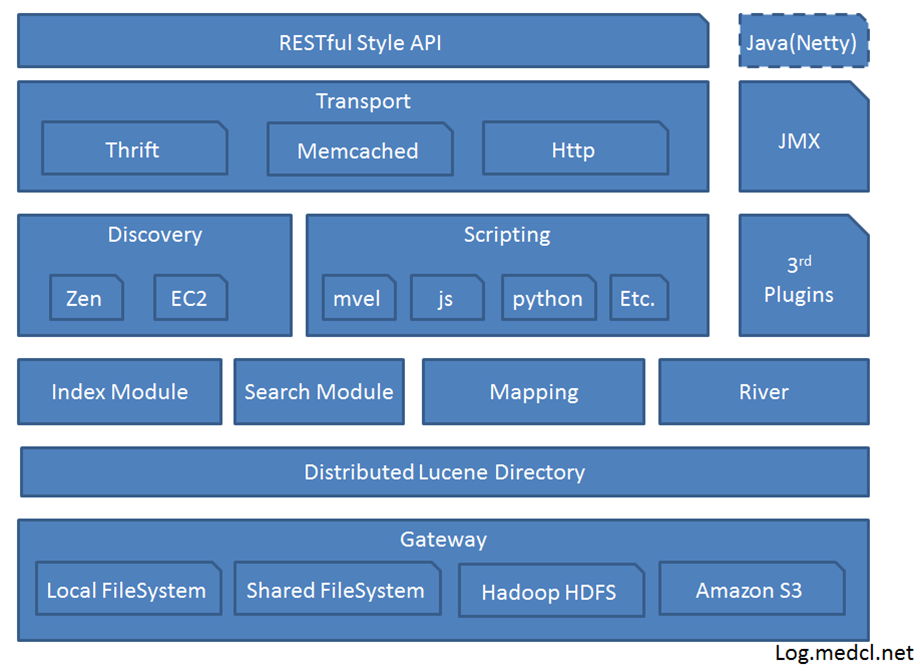
Gateway是ES用来存储索引的文件系统,支持多种类型。
Gateway的上层是一个分布式的lucene框架。
Lucene之上是ES的模块,包括:索引模块、搜索模块、映射解析模块等
ES模块之上是 Discovery、Scripting和第三方插件。Discovery是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure。Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低。
ES也支持多种第三方插件。
再上层是ES的传输模块和JMX.传输模块支持多种传输协议,如 Thrift、memecached、http,默认使用http。JMX是java的管理框架,用来管理ES应用。
最上层是ES提供给用户的接口,可以通过RESTful接口或java api和ES集群进行交互。
服务发现以及选主 ZenDiscovery
- 节点启动后先ping(这里的ping是 Elasticsearch 的一个RPC命令。如果 discovery.zen.ping.unicast.hosts 有设置,则ping设置中的host,否则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点)Ping的response会包含该节点的基本信息以及该节点认为的master节点。
- 选举开始,先从各节点认为的master中选,规则很简单,按照id的字典序排序,取第一个。
- 如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举。
- 最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己。
- 如果当前节点是master,则开始等待节点数达到 minimum_master_nodes(最小候选节点数),然后提供服务。
- 如果当前节点不是master,则尝试加入master。
Elasticsearch 将以上服务发现以及选主的流程叫做 ZenDiscovery 。由于它支持任意数目的集群(1-N),所以不能像 Zookeeper/Etcd那样限制节点必须是奇数,也就无法用投票的机制来选主,而是通过一个规则,只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的。但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题,大多数解决方案就是设置一个quorum值,要求可用节点必须大于quorum(一般是超过半数节点),才能对外提供服务。而 Elasticsearch 中,这个quorum的配置就是 discovery.zen.minimum_master_nodes 。
es是如何实现Master选举的
Elasticsearch的选举是ZenDiscovery模块负责的,通过多播或单播技术来发现同一个集群中的其他节点并与它们连接。
一个节点如何选取它自己认为的master节点?
它会对所有可以成为master的节点(node.master: true)根据nodeId字典排序,,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
多播和单播
基于以下假设: 集群由cluster.name设置项相同的节点自动连接而成,同一个网段中存在多个独立的集群.Zen 发现机制是ElasticSearch中默认的用来发现新节点的功能模块,而且集群启动后默认生效。Zen发现机制默认配置是用多播来寻找其它的节点。如果各个模块工作正常,该节点就会自动添加到与节点中集群名字(cluster.name)一样的集群,同时其它的节点都能感知到新节点的加入。在比较大的集群中,多播发现机制可能会产生太多不必要的流量开销,Zen发现机制引入了第二种发现节点的方法:单播模式。关于名词多播和单播:
链接:https://www.zhihu.com/question/29360024/answ
- 多播:当节点并非集群的一部分时(比如节点只是刚刚启动或者重启 ),它会发送一个多播的ping请求到网段中,该请求只是用来通知所有能连接到节点和集群它已经准备好加入到集群中。
- 单播: 关闭多播,就可以安全地使用单播。当节点不是集群的一部分时(比如节点重启,启动或者由于某些错误从集群中断开),节点会发送一个ping请求到事先设置好的地址中,来通知集群它已经准备好加入到集群中了。
为了安全考虑,阿里一般用单播模式。
ElasticSearch运行时会启动两个探测进程。一个进程用于从主节点向集群中其它节点发送ping请求来检测节点是否正常可用。另一个进程的工作反过来了,其它的节点向主节点发送ping请求来验证主节点是否正常且忠于职守
es是如何避免脑裂现象的
可以通过discovery.zen.minimum_master_nodes
这个参数的设置来避免脑裂,设置为(N/2)+1。
es的集群只有一个节点的话可以有副本吗?
Elasticsearch 禁止同一个分片的主分片和副本分片在同一个节点上,所以如果是一个节点的集群是不能有副本的。
集群如何恢复以及容灾
分布式系统的一个要求就是要保证高可用。如果是故障导致节点挂掉,Elasticsearch 就会主动allocation。但如果节点丢失后立刻allocation,稍后节点恢复又立刻加入,会造成浪费。Elasticsearch的恢复流程大致如下:
- 集群中的某个非master节点丢失网络连接
- 如果该节点上的分片有副本,那么master提升该节点上的所有主分片的在其他节点上的副本为主分片。cluster集群状态变为 yellow ,因为副本数不够
等待一个超时设置的时间,如果丢失节点回来就可以立即恢复(默认为1分钟,通过 index.unassigned.node_left.delayed_timeout 设置)。如果该分片已经有写入,则通过translog进行增量同步数据。
否则将副本分配给其他节点,开始同步数据。 - 但如果该节点上的分片没有副本,则无法恢复,集群状态会变为red,表示可能要丢失该分片的数据了。
如果是主节点master挂掉怎么办呢?当从节点们发现和主节点连接不上了,那么他们会自己决定再选举出一个节点为主节点。但是这里有个脑裂的问题,假设有5台机器,3台在一个机房,2台在另一个机房,当两个机房之间的联系断了之后,每个机房的节点会自己聚会,推举出一个主节点。
这个时候就有两个主节点存在了,当机房之间的联系恢复了之后,这个时候就会出现数据冲突了。解决的办法就是设置参数: discovery.zen.minimum_master_nodes
为3(超过一半的节点数),那么当两个机房的连接断了之后,就会以大于等于3的机房的master为主,另外一个机房的节点就停止服务了。
es搜索的过程描述(默认搜索方式Query Then Fetch)
Query Then Fetch
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤,第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。
搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch
在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
es集群分片的读写操作流程
1、路由计算(routing)和副本一致性(replica)
- routing
Elasticsearch针对路由计算选择了一个很简单的方法,计算如下:
routing = hash(routing) % number_of_primary_shards
每个数据都有一个routing参数,默认情况下,就使用其_id值,将其_id值计算hash后,对索引的主分片数取余,就是数据实际应该存储到的分片ID
由于取余这个计算,完全依赖于分母,所以导致Elasticsearch索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,索引数据不可读。
- 副本一致性(replica)
作为分布式系统,数据副本可算是一个标配。Elasticsearch数据写入流程。自然涉及副本,在有副本配置的情况下,数据从发向Elasticsearch节点,到接到Elasticsearch节点响应返回,流向如下
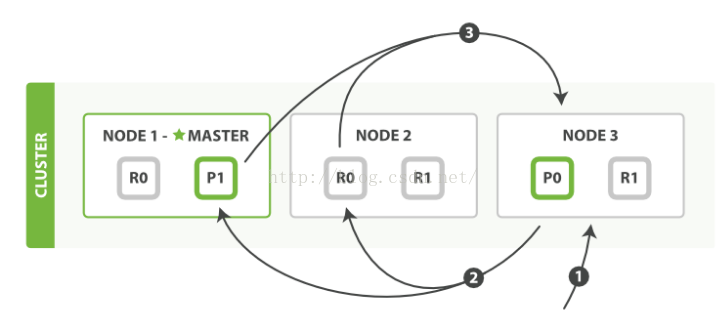
1)客户端请求发送给master Node1节点,这里也可以发送给其他节点
2)Node1节点用数据的_id计算出数据应该存储在shard0上,通过cluster state信息发现shard0的主分片在Node3节点上,Node1转发请求数据给Node3,Node3完成数据的索引,索引过程在上篇博客中详细介绍了。
3)Node3并行转发数据给分配有shard0的副本分片Node1和Node2上。当收到任一节点汇报副本分片数据写入成功以后,Node3即返回给初始的接受节点Node1,宣布数据写入成功。Node1成功返回给客户端。
2、shard的allocate配置
上文介绍了分片的索引过程,通过路由计算可以确定文本所在的分片id,那么分片在集群中的分配策略是如何确定的?
一般来说,某个shard分配在哪个节点上,是由Elasticsearch自动决定的。以下几种情况会触发分配动作。
新索引生成
索引的删除
新增副本分片
节点增减引发的数据均衡
es中的shard(分片)
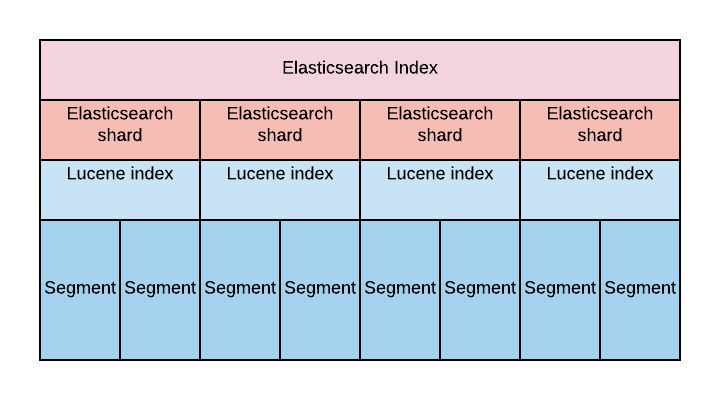
Shard 实际上是一个 Lucene 的一个实例(Lucene Index),但往往一个 Elastic Index 都是由多个 Shards (primary & replica)构成的。
特别注意,在单个 Lucene 实例里最多包含2,147,483,519 (= Integer.MAX_VALUE - 128) 个 Documents。
Lucene Index结构
一个 Lucene Index 在文件系统的表现上来看就是存储了一系列文件的一个目录。一个 Lucene Index 由许多独立的 segments 组成,而 segments 包含了文档中的词汇字典、词汇字典的倒排索引以及 Document 的字段数据(设置为Stored.YES的字段),所有的 segments 数据存储于 _.cfs的文件中。
Segment
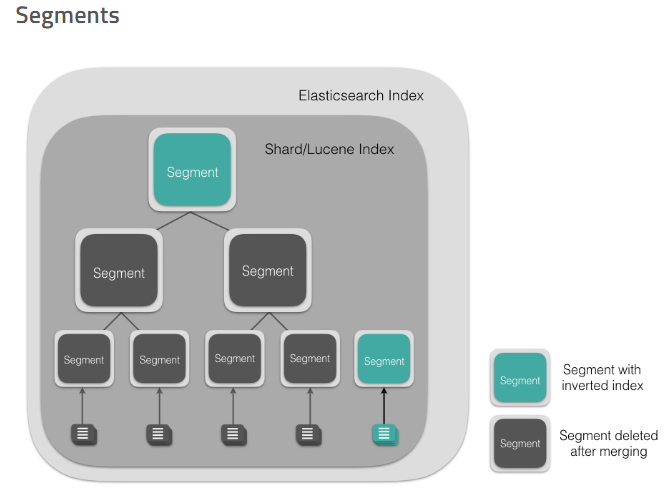
Segment 直接提供了搜索功能的,ES 的一个 Shard (Lucene Index)中是由大量的 Segment 文件组成的,且每一次 fresh 都会产生一个新的 Segment 文件,这样一来 Segment 文件有大有小,相当碎片化。ES 内部则会开启一个线程将小的 Segment 合并(Merge)成大的 Segment,减少碎片化,降低文件打开数,提升 I/O 性能。
Segment 文件是不可变更的。当一个 Document 更新的时候,实际上是将旧的文档标记为删除,然后索引一个新的文档。在 Merge 的过程中会将旧的 Document 删除掉。具体到文件系统来说,文档 A 是写入到 .cfs 文件里的,删除文档 A 实际上是在.del文件里标记某个 document 已被删除,那么下次查询的时候则会跳过这个文档,是为逻辑删除。当归并(Merge)的时候,老的 segment 文件将会被删除,合并成新的 segment 文件,这个时候也就是物理删除了。
新建index,但是还未插入数据时的目录结构:
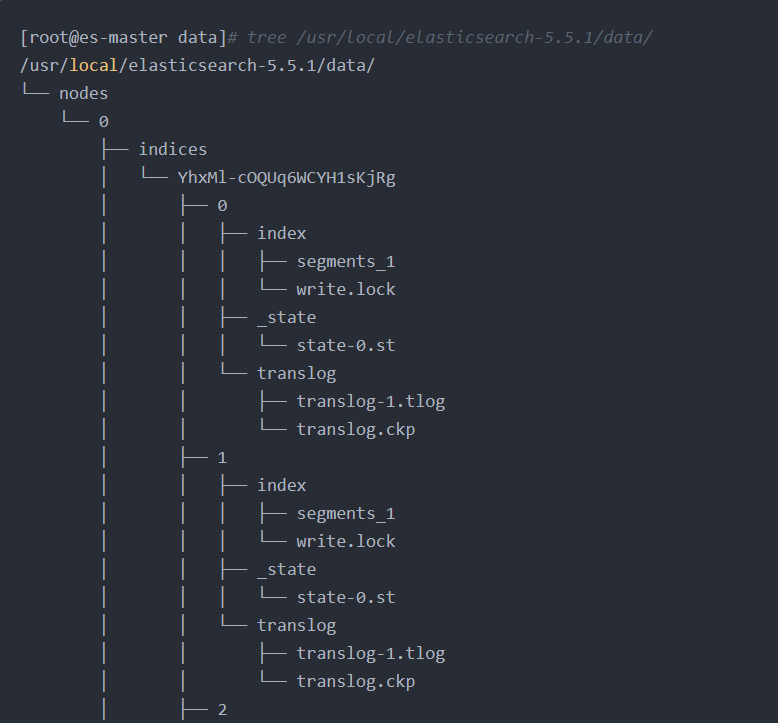
插入数据之后会多很多文件:
存储原文_source的文件.fdt .fdm .fdx;
存储倒排索引的文件.tim .tip .doc;
用于聚合排序的列存文件.dvd .dvm;
全文检索文件.pos .pay .nvd .nvm等。
加载到内存中的文件有.fdx .tip .dvm,
其中.tip占用内存最大,而.fdt . tim .dvd文-件占用磁盘最大
另外segment较小时文件内容是保存在.cfs文件中,.cfe文件保存Lucene各文件在.cfs文件的位置信息,这是为了减少Lucene打开的文件句柄数。
存储文件类型比较可见:https://www.itcodemonkey.com/article/8954.html
参考链接
https://zhuanlan.zhihu.com/p/33671444
https://yq.aliyun.com/articles/581877
https://www.cnblogs.com/LBSer/p/4119841.html
https://my.oschina.net/u/2935389/blog/754674
https://blog.csdn.net/yangwenbo214/article/details/77802331
https://www.jianshu.com/p/2cac077e05cf