wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
ssh-keygen -t rsa
# cat id_rsa.pub>> authorized_keys
# ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
# ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
# cat id_rsa.pub>> authorized_keys
# ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
# ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
# scp authorized_keys root@server2:/root/.ssh/
# scp authorized_keys root@server3:/root/.ssh/
# scp known_hosts root@server2:/root/.ssh/
# scp known_hosts root@server3:/root/.ssh/[root@master localfiles]# hdfs dfs -mkdir /user
[root@master localfiles]# hdfs dfs -mkdir /user/root
[root@master localfiles]# hdfs dfs -mkdir /user/root/input
[root@master localfiles]# hdfs dfs -mkdir /user/root/output
[root@master localfiles]# hdfs dfs -put ./testHdfs.txt /user/root/inputHadoop HA 原理概述
为什么会有 hadoop HA 机制呢?
HA:High Available,高可用
在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SPOF:A Single Point of Failure)。 对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件 升级),那么整个集群将无法使用,直到 NameNode 重新启动
那如何解决呢?
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点, 确保 NameNodes 中只有一个处于 Active 状态,其他的处在 Standby 状态。其中 ActiveNameNode 负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一 旦 ActiveNameNode 出现问题能够快速切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提 供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则 读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一 致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换, Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需 要配置 NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。


集群规划
描述:hadoop HA 集群的搭建依赖于 zookeeper,所以选取三台当做 zookeeper 集群 ,总共准备了四台主机,分别是 hadoop1,hadoop2,hadoop3,hadoop4 其中 hadoop1 和 hadoop2 做 namenode 的主备切换,hadoop3 和 hadoop4 做 resourcemanager 的主备切换
四台机器
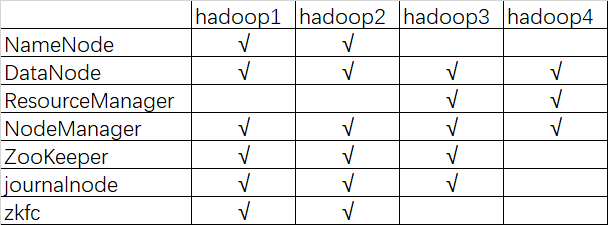
集群服务器准备
1、 修改主机名
2、 修改 IP 地址
3、 添加主机名和 IP 映射
4、 添加普通用户 hadoop 用户并配置 sudoer 权限
5、 设置系统启动级别
6、 关闭防火墙/关闭 Selinux
7、 安装 JDK 两种准备方式:
1、 每个节点都单独设置,这样比较麻烦。线上环境可以编写脚本实现
2、 虚拟机环境可是在做完以上 7 步之后,就进行克隆
3、 然后接着再给你的集群配置 SSH 免密登陆和搭建时间同步服务
8、 配置 SSH 免密登录
集群安装
1、安装 Zookeeper 集群
具体安装步骤参考之前的文档http://www.cnblogs.com/qingyunzong/p/8619184.html
2、安装 hadoop 集群
(1)获取安装包
从官网或是镜像站下载
http://mirrors.hust.edu.cn/apache/
(2)上传解压缩
[hadoop@hadoop1 ~]$ ls
apps hadoop-2.7.5-centos-6.7.tar.gz movie2.jar users.dat zookeeper.out
data log output2 zookeeper-3.4.10.tar.gz
[hadoop@hadoop1 ~]$ tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C apps/(3)修改配置文件
配置文件目录:/home/hadoop/apps/hadoop-2.7.5/etc/hadoop
修改 hadoop-env.sh文件
[hadoop@hadoop1 ~]$ cd apps/hadoop-2.7.5/etc/hadoop/
[hadoop@hadoop1 hadoop]$ echo $JAVA_HOME
/usr/local/jdk1.8.0_73
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh 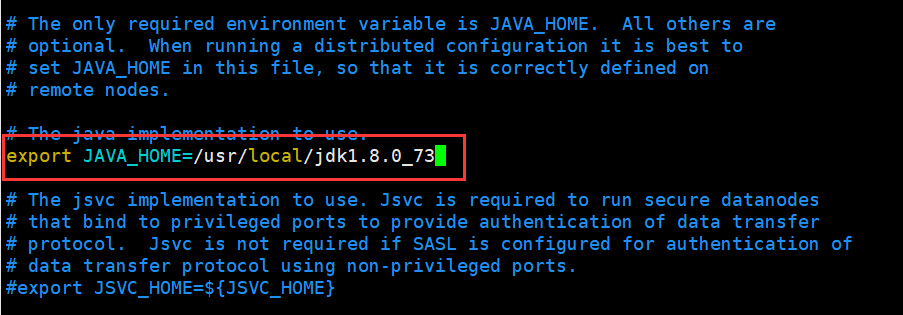
修改core-site.xml
[hadoop@hadoop1 hadoop]$ vi core-site.xml<configuration>
<!-- 指定hdfs的nameservice为myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off
</description>
</property>
</configuration>
修改hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml <configuration> <!-- 指定副本数 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 配置namenode和datanode的工作目录-数据存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/hadoopdata/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/hadoopdata/dfs/data</value> </property> <!-- 启用webhdfs --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致 dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。 配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。 例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符 --> <property> <name>dfs.nameservices</name> <value>myha01</value> </property> <!-- myha01下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.myha01</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn1</name> <value>hadoop1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn1</name> <value>hadoop1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn2</name> <value>hadoop2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn2</name> <value>hadoop2:50070</value> </property> <!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表 该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId journalId推荐使用nameservice,默认端口号是:8485 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/myha01</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/data/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.myha01</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>ha.failover-controller.cli-check.rpc-timeout.ms</name> <value>60000</value> </property> </configuration>
修改mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vi mapred-site.xml<configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 指定mapreduce jobhistory地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop1:10020</value> </property> <!-- 任务历史服务器的web地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop1:19888</value> </property> </configuration>
修改yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml <configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
修改slaves
[hadoop@hadoop1 hadoop]$ vi slaves hadoop1
hadoop2
hadoop3
hadoop4(4)将hadoop安装包分发到其他集群节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop2:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop3:$PWD
[hadoop@hadoop1 apps]$ scp -r hadoop-2.7.5/ hadoop4:$PWD(5)配置Hadoop环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
本人是用的hadoop用户安装的
[hadoop@hadoop1 ~]$ vi .bashrcexport HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin: 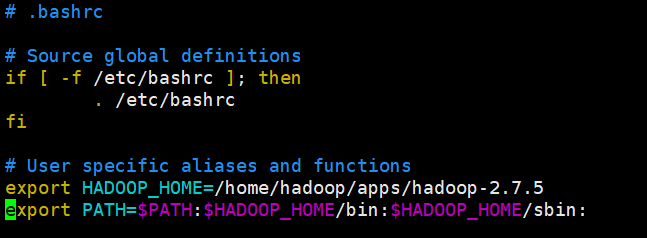
使环境变量生效
[hadoop@hadoop1 bin]$ source ~/.bashrc (6)查看hadoop版本
[hadoop@hadoop4 ~]$ hadoop version
Hadoop 2.7.5
Subversion Unknown -r Unknown
Compiled by root on 2017-12-24T05:30Z
Compiled with protoc 2.5.0
From source with checksum 9f118f95f47043332d51891e37f736e9
This command was run using /home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar
[hadoop@hadoop4 ~]$ 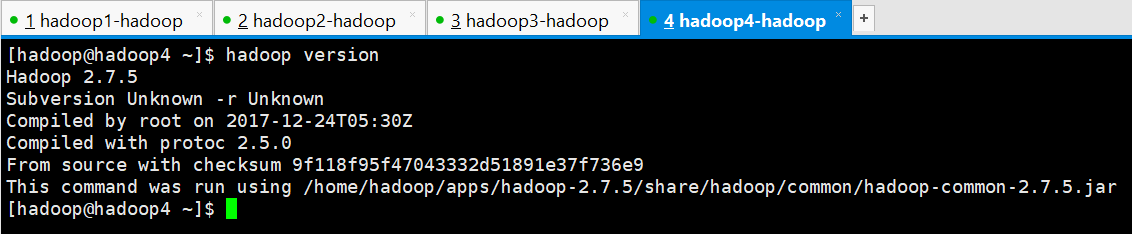
Hadoop HA集群的初始化
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
重点强调:一定要按照以下步骤逐步进行操作
1、启动ZooKeeper
启动4台服务器上的zookeeper服务
hadoop1
[hadoop@hadoop1 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop1 conf]$ jps
2674 Jps
2647 QuorumPeerMain
[hadoop@hadoop1 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop1 conf]$ hadoop2
[hadoop@hadoop2 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop2 conf]$ jps
2592 QuorumPeerMain
2619 Jps
[hadoop@hadoop2 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop2 conf]$ hadoop3
[hadoop@hadoop3 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop3 conf]$ jps
16612 QuorumPeerMain
16647 Jps
[hadoop@hadoop3 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[hadoop@hadoop3 conf]$ hadoop4
[hadoop@hadoop4 conf]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop4 conf]$ jps
3596 Jps
3567 QuorumPeerMain
[hadoop@hadoop4 conf]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: observer
[hadoop@hadoop4 conf]$ 2、在你配置的各个journalnode节点启动该进程
按照之前的规划,我的是在hadoop1、hadoop2、hadoop3上进行启动,启动命令如下
hadoop1
[hadoop@hadoop1 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop1.out
[hadoop@hadoop1 conf]$ jps
2739 JournalNode
2788 Jps
2647 QuorumPeerMain
[hadoop@hadoop1 conf]$ hadoop2
[hadoop@hadoop2 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop2.out
[hadoop@hadoop2 conf]$ jps
2592 QuorumPeerMain
3049 JournalNode
3102 Jps
[hadoop@hadoop2 conf]$ hadoop3
[hadoop@hadoop3 conf]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop3.out
[hadoop@hadoop3 conf]$ jps
16612 QuorumPeerMain
16712 JournalNode
16766 Jps
[hadoop@hadoop3 conf]$ 3、格式化namenode
先选取一个namenode(hadoop1)节点进行格式化
[hadoop@hadoop1 ~]$ hadoop namenode -format
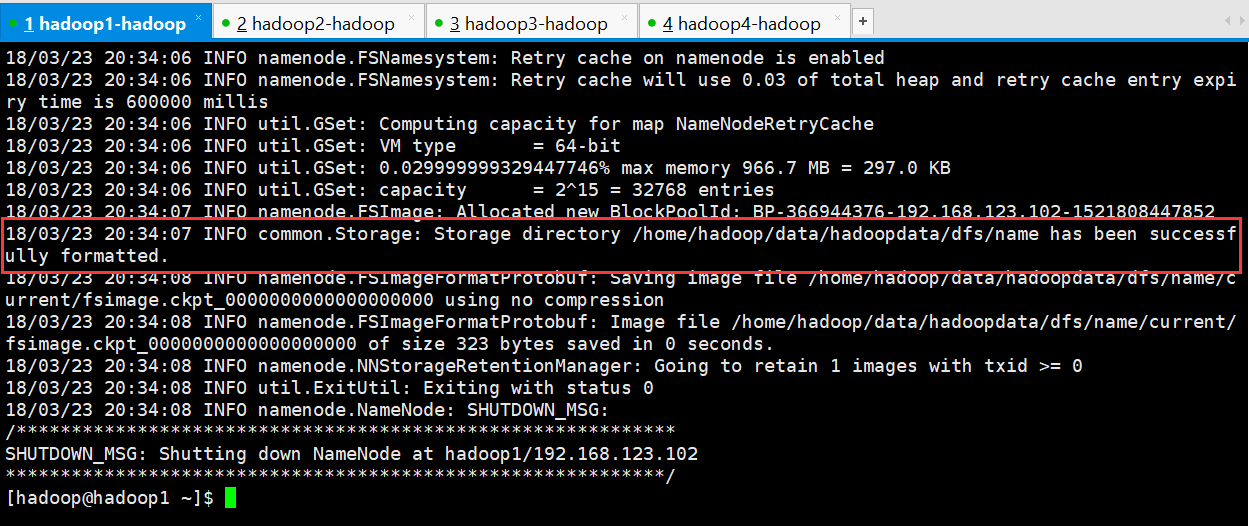
4、要把在hadoop1节点上生成的元数据 给复制到 另一个namenode(hadoop2)节点上
[hadoop@hadoop1 ~]$ cd data/
[hadoop@hadoop1 data]$ ls
hadoopdata journaldata zkdata
[hadoop@hadoop1 data]$ scp -r hadoopdata/ hadoop2:$PWD
VERSION 100% 206 0.2KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
fsimage_0000000000000000000 100% 323 0.3KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
[hadoop@hadoop1 data]$

5、格式化zkfc
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
重点强调:只能在nameonde节点进行
[hadoop@hadoop1 data]$ hdfs zkfc -formatZK
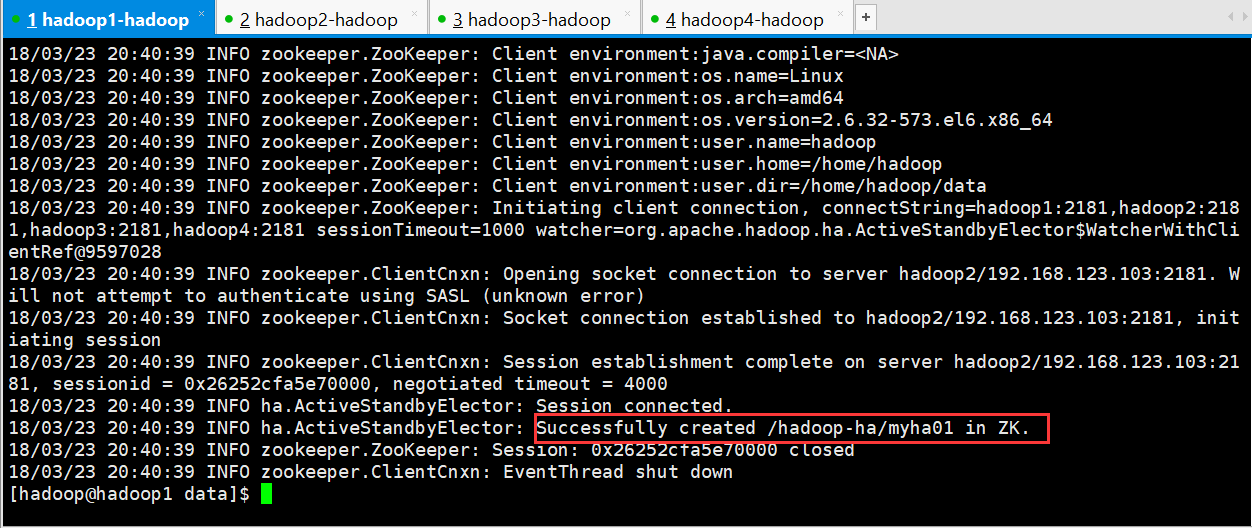
启动集群
1、启动HDFS
可以从启动输出日志里面看到启动了哪些进程
[hadoop@hadoop1 ~]$ start-dfs.sh
Starting namenodes on [hadoop1 hadoop2]
hadoop2: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop2.out
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop3.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop4.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop2.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop1.out
Starting journal nodes [hadoop1 hadoop2 hadoop3]
hadoop3: journalnode running as process 16712. Stop it first.
hadoop2: journalnode running as process 3049. Stop it first.
hadoop1: journalnode running as process 2739. Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop2.out
hadoop1: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop1.out
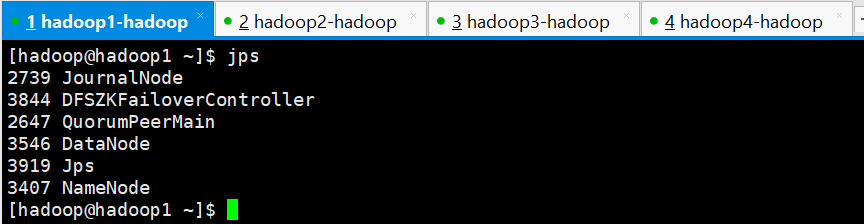
[hadoop@hadoop1 ~]$ 查看各节点进程是否正常
hadoop1
hadoop2

hadoop3
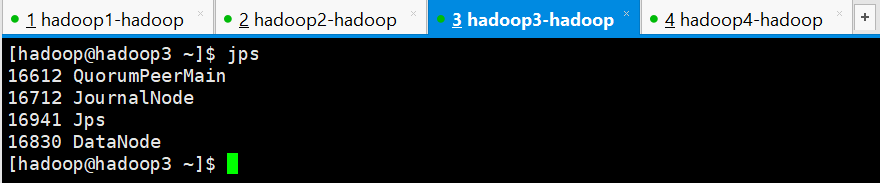
hadoop4

2、启动YARN
在主备 resourcemanager 中随便选择一台进行启动
[hadoop@hadoop4 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-resourcemanager-hadoop4.out
hadoop3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop4: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-hadoop1.out
[hadoop@hadoop4 ~]$ 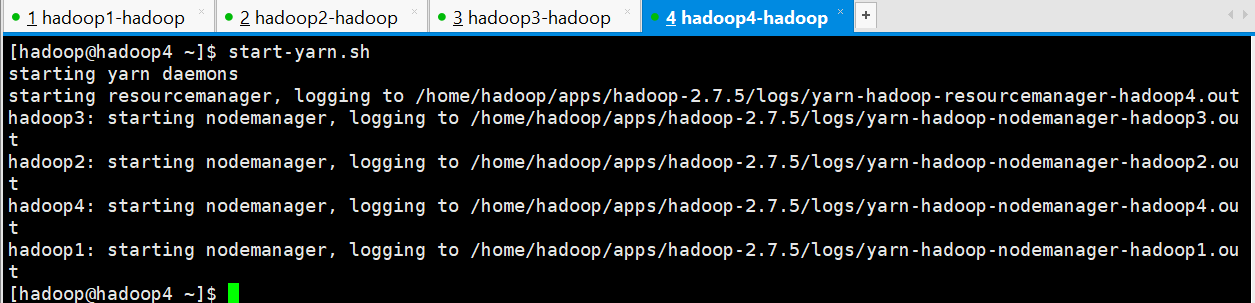
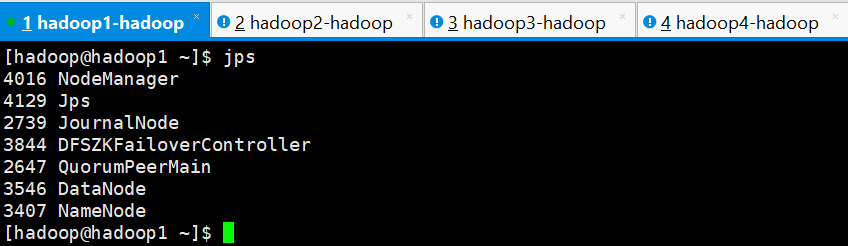
正常启动之后,检查各节点的进程
hadoop1
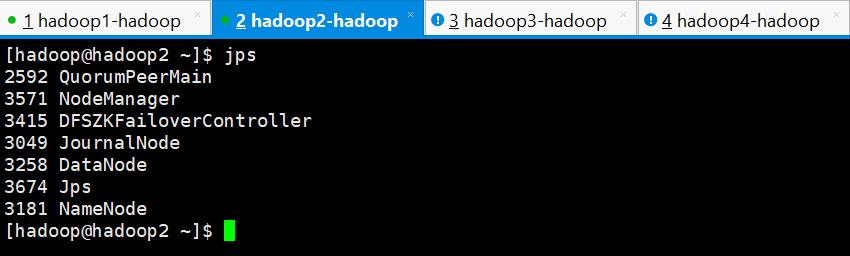
hadoop2
hadoop3

hadoop4

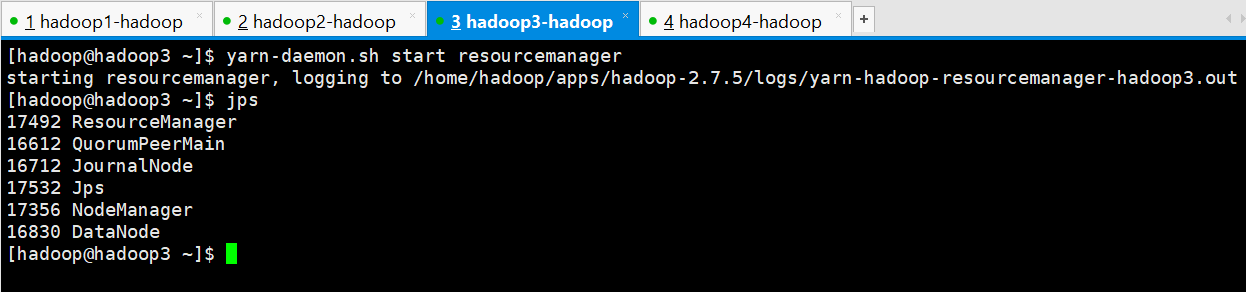
若备用节点的 resourcemanager 没有启动起来,则手动启动起来,在hadoop3上进行手动启动
[hadoop@hadoop3 ~]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7.5/logs/yarn-hadoop-resourcemanager-hadoop3.out
[hadoop@hadoop3 ~]$ jps
17492 ResourceManager
16612 QuorumPeerMain
16712 JournalNode
17532 Jps
17356 NodeManager
16830 DataNode
[hadoop@hadoop3 ~]$
3、启动 mapreduce 任务历史服务器
[hadoop@hadoop1 ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/apps/hadoop-2.7.5/logs/mapred-hadoop-historyserver-hadoop1.out
[hadoop@hadoop1 ~]$ jps
4016 NodeManager
2739 JournalNode
4259 Jps
3844 DFSZKFailoverController
2647 QuorumPeerMain
3546 DataNode
4221 JobHistoryServer
3407 NameNode
[hadoop@hadoop1 ~]$ 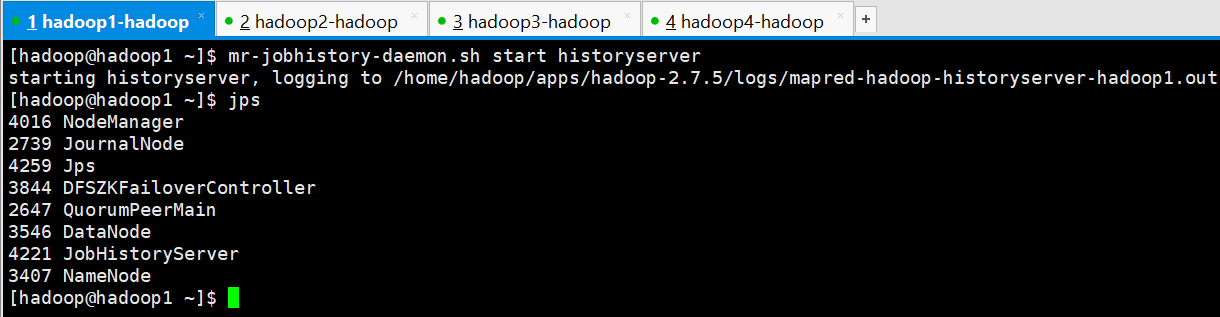
4、查看各主节点的状态
HDFS
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop1 ~]$ hdfs haadmin -getServiceState nn2
active
[hadoop@hadoop1 ~]$ 
YARN
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm1
standby
[hadoop@hadoop4 ~]$ yarn rmadmin -getServiceState rm2
active
[hadoop@hadoop4 ~]$ 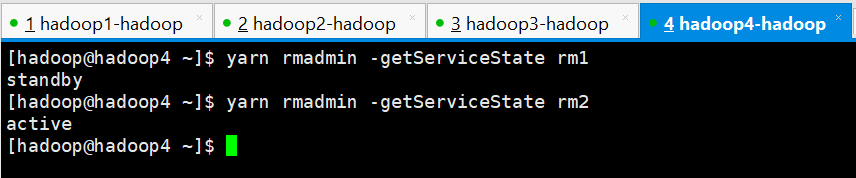
5、WEB界面进行查看
HDFS
hadoop1
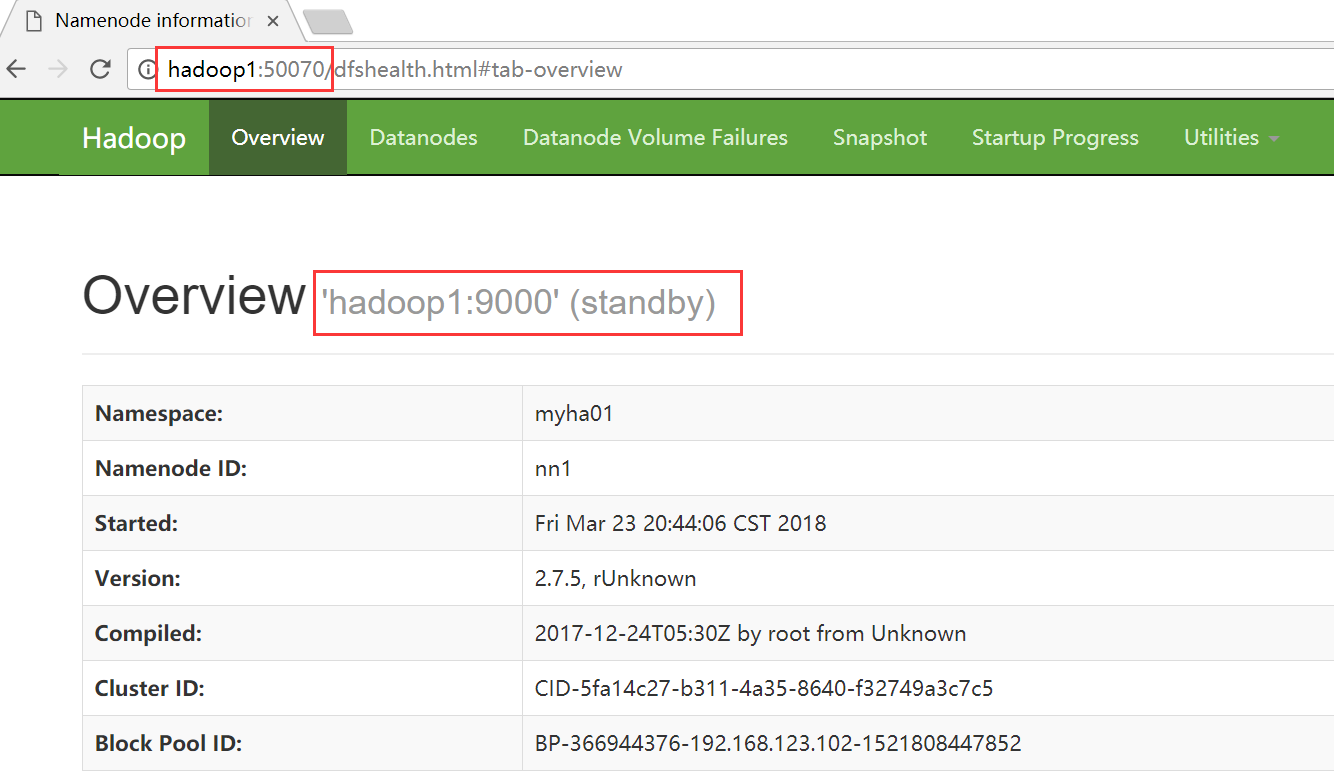
hadoop2
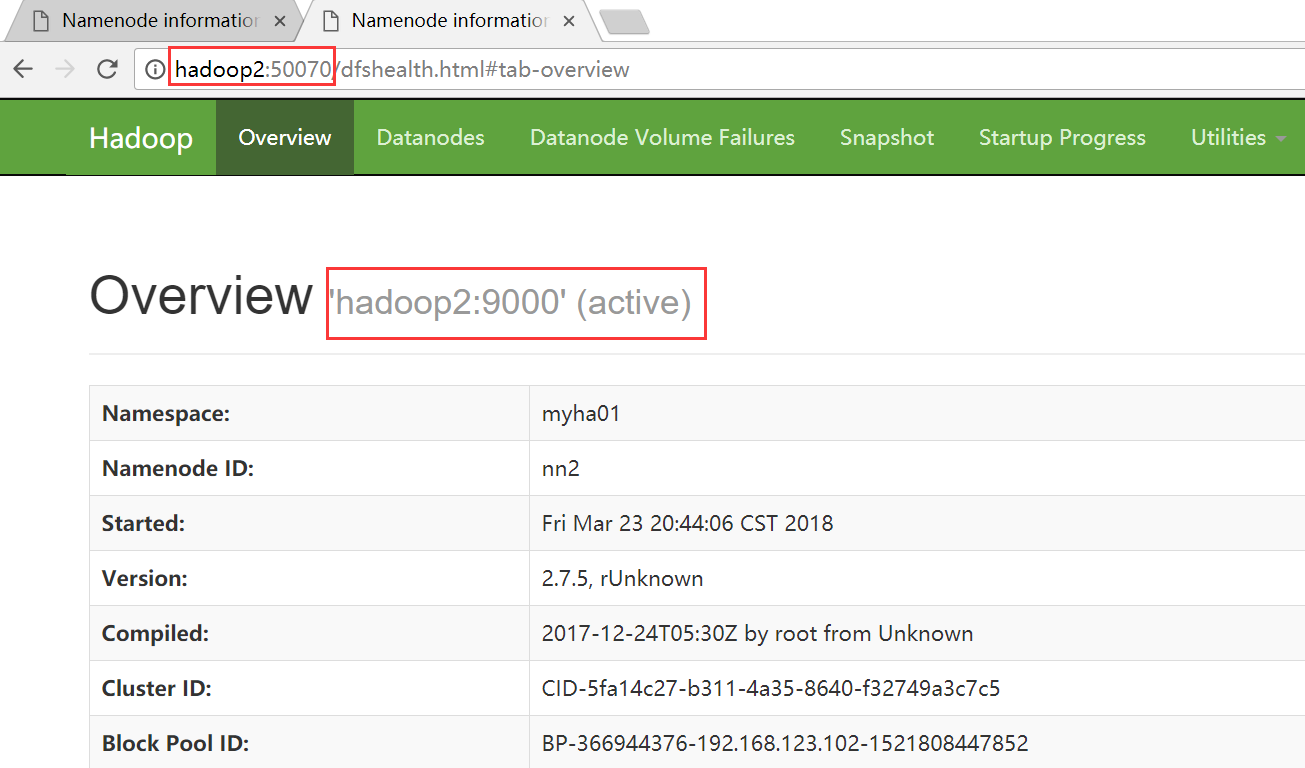
YARN
standby节点会自动跳到avtive节点
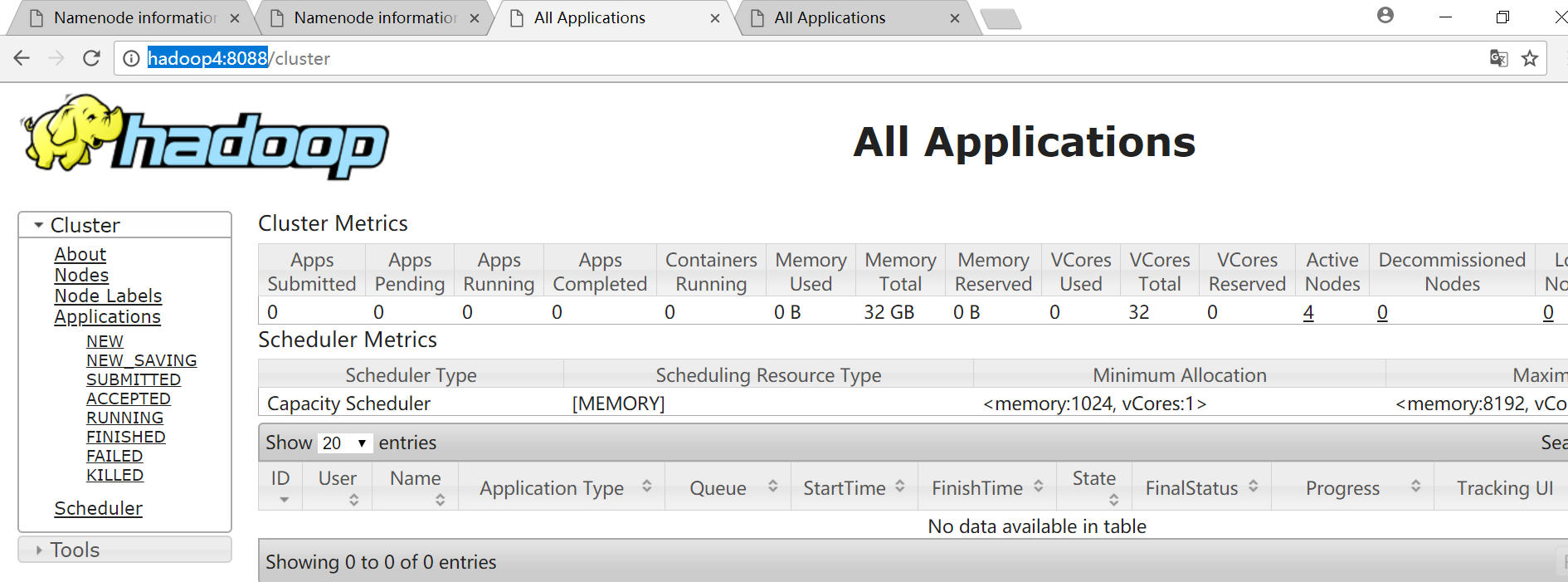
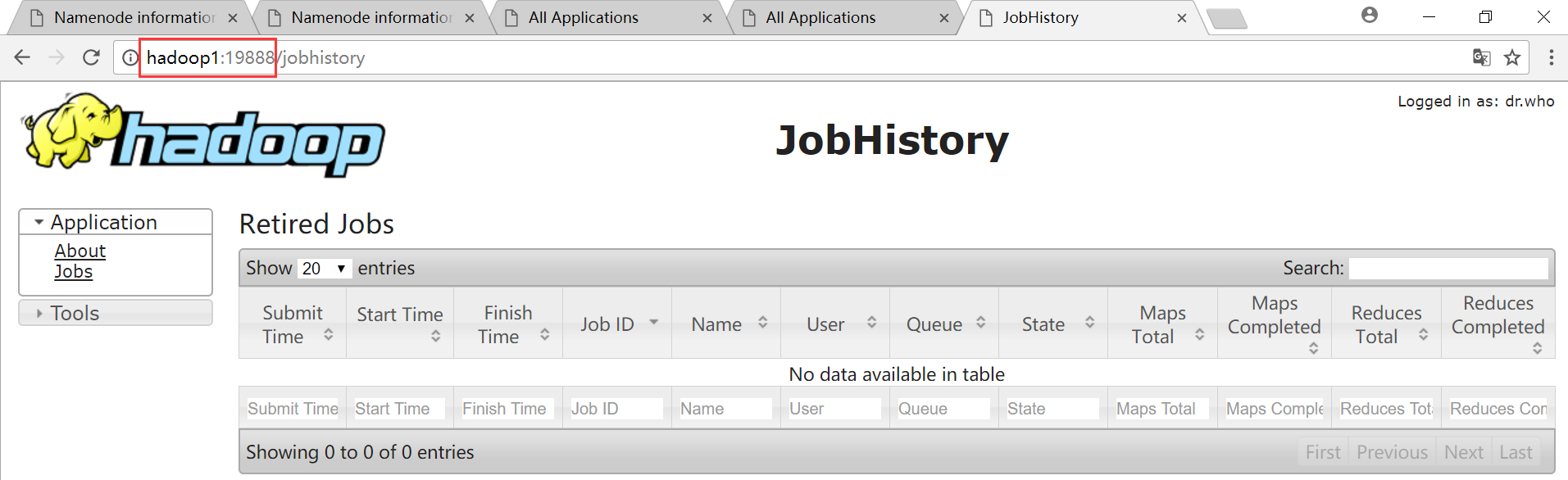
MapReduce历史服务器web界面
集群性能测试
1、干掉 active namenode, 看看集群有什么变化
目前hadoop2上的namenode节点是active状态,干掉他的进程看看hadoop1上的standby状态的namenode能否自动切换成active状态
[hadoop@hadoop2 ~]$ jps
4032 QuorumPeerMain
4400 DFSZKFailoverController
4546 NodeManager
4198 DataNode
4745 Jps
4122 NameNode
4298 JournalNode
[hadoop@hadoop2 ~]$ kill -9 4122