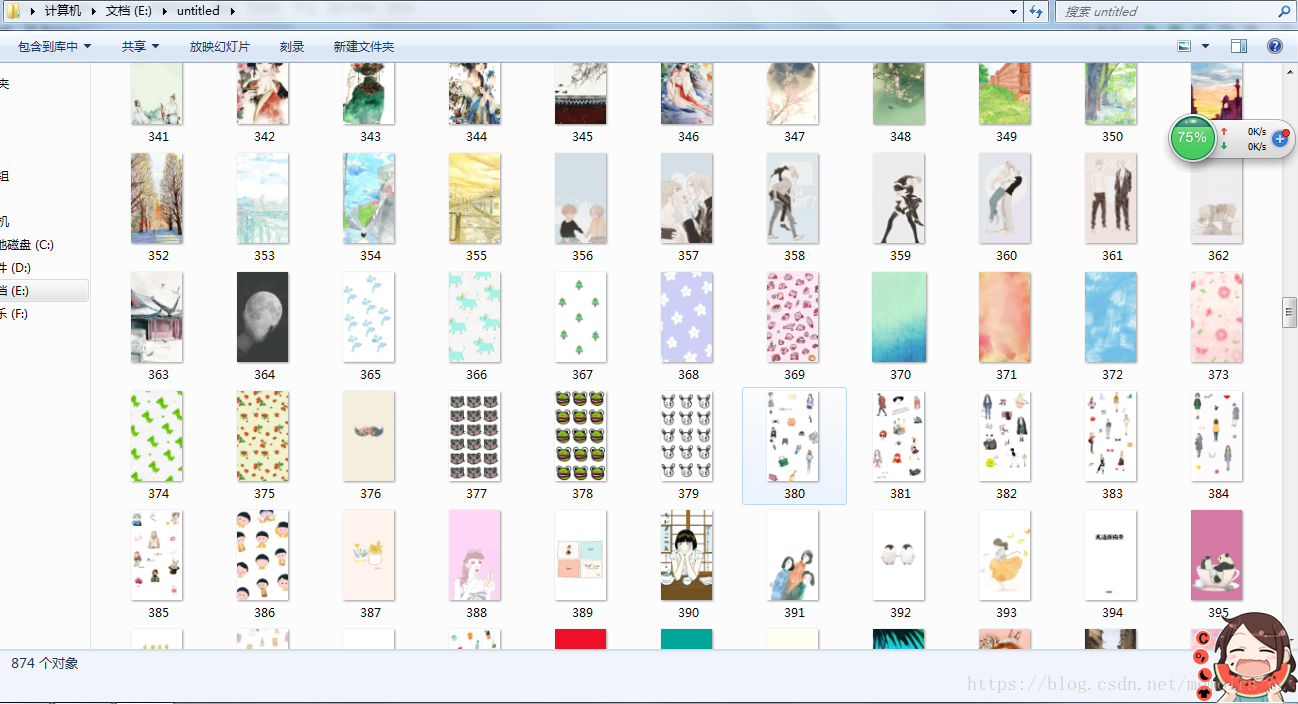
Python爬取百度贴吧图片
Python2.7.15
当我们需要从网页上大量下载东西时,Python是我们很好的帮手,这次我们以爬取壁纸吧的壁纸图片为例。
一.获取网址
首先从壁纸吧中选一个你喜欢的帖子打开,复制它的网址

二.获取它的HTML源码
首先,我们要引入对应模块
import re
import urllib
import sys
reload(sys)
sys.setdefaultencoding('utf8')
re是正则表达式模块,用来匹配图片地址。
urllib模块用来获取HTML源码。
重新加载sys模块将编码设置为utf8,python在安装时,默认的编码是ascii。
然后用urllib模块的函数来获取源码。
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
运行一下,返回该网页的源码
三、用正则匹配源码中图片地址并下载
从源码中我们可以看到壁纸图片的格式是统一的
都是以src=开头,以jpg结尾,由此设置正则,并进行匹配


reg = r'src="(https://imgsa.baidu.com/forum/w%3D580/sign=.*?\.jpg)"'
imgre = re.compile(reg)
imList = re.findall(reg, html)
其中,()表示 我们只取括号中的内容,不要之外的; ‘\ .’ 是 ‘.’的 转义
for i in imList:
#print(i)
print x
urllib.urlretrieve(i, '%s.jpg' % x)
x += 1
return x
使用for循环遍历匹配到你内容并放入i中,以x命名,并以jpg格式存储
这里返回x是为下一页的循环准备,以便每一页能接上
这里说一下页数问题
贴吧帖子一般都很长,会有好几十页,我们在爬取的时候如何翻页呢?这就要看它的格式了,比如这次的壁纸帖子,就是在原地址后加了个pn=,这样我们可以用for循环来翻页

for k in range(1,89):
ul = url+ str(k)
print ul
html = getHtml(ul)
print html
四.完整代码与结果
import re
import urllib
import sys
reload(sys)
sys.setdefaultencoding('utf8')
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html, x):
reg = r'src="(https://imgsa.baidu.com/forum/w%3D580/sign=.*?\.jpg)"'
imList = re.findall(reg, html)
for i in imList:
print x
urllib.urlretrieve(i, '%s.jpg' % x)
x += 1
return x
x = 1
url = "https://tieba.baidu.com/p/4364768066?pn="
for k in range(1,89):
ul = url+ str(k)
print ul
html = getHtml(ul)
x = getImg(html, x)
实在太多爬到八百多我就停了