版权声明:如有侵权,请联系作者删除该文件! https://blog.csdn.net/Programmer_huangtao/article/details/83012321
选取一个浏览器,小白,网上得出结论谷歌浏览器OK!不是不让用了吗?怎么还用谷歌??
为什么爬虫要用Chrome?
- 为什么大家似乎都值得header应该怎么写?
- 为什么大家都知道怎么爬取网页的路线?
- 为什么....
如果你也跟我一样,有过上面类似的疑问,那么我觉得,这篇文章你可能值得看一下。
1. 设置谷歌
打开设置--->有一个设置--->打开设置
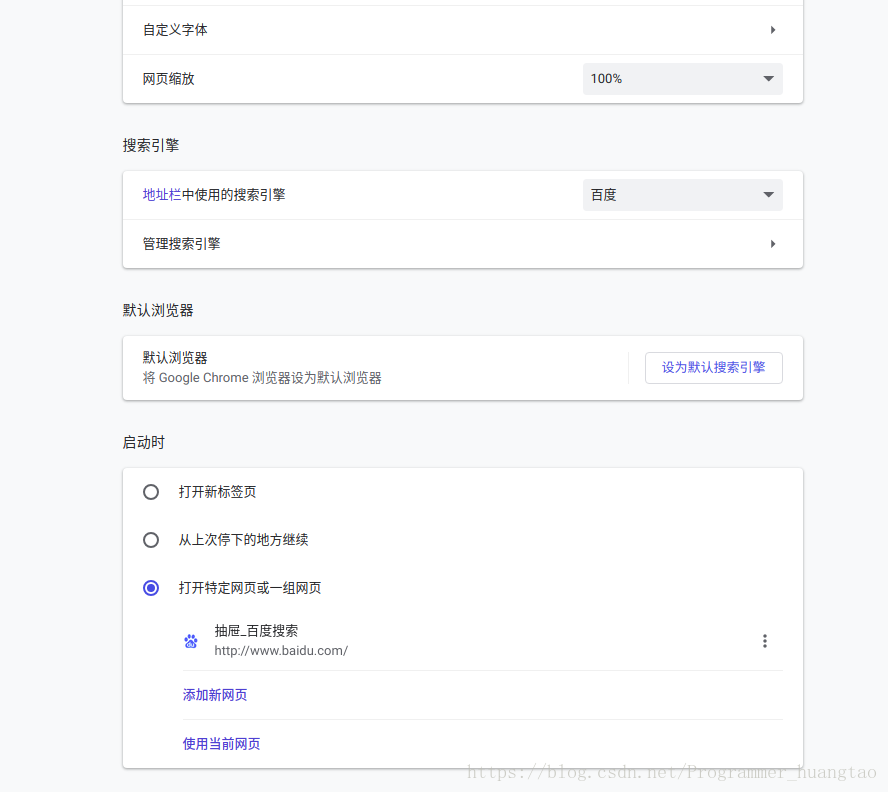
设置下滑到搜索引擎选择不是谷歌的,建议百度,把它设置成其他的引擎就行了,爬虫用的是这个谷歌浏览器程序的功能,又不是谷歌浏览器界面对吧.
2.使用谷歌
用Chrome很容易看到网页的源码轻松右键 -> 检查,就可以看到这个源代码.

通过浏览器得到加载的数据
检查中还可以看网页从服务器上不断加载包,虽然一开始我们点开的时候,网页其实已经加载好了。对于所谓的静态网页在这个地方其实已经加载好了。(百度的首页,一般会被认为是静态网页),但是还可以通过这个来看。 比如: 刷新一下网页~~~~~不过,在那之前,我们要点之前检查的最上面的 network,一般默认是选中All模式的,在中间偏上的部分。点好之后,我们就可以刷新了

比如:我们可以检查之前的那个包,就可以看那些包的具体信息。那样,我们就可以得到了所有很多重要的信息了

比如像上面的我们可以看到这个信息,是通过上面header拿到的。不过这个,有些会把这个给隐藏掉。但基本是没有问题的,一般我们只要知道一个就好了。还有其他的骚操作,比如:看看这个包是怎么拿下来的,这样我们就可以特定地拿数据了。

通过这个,我们可以看到这个,用的是https://www.baidu.com/img/bd_logo1.png这个url,请求的方法是get,还可以得到对方的服务器地址。

最后还可以通过最后的tim来看一下这个东西下载所用的时间
(可以算是测测速?)
