开发环境:Hadoop+HBASE+Phoenix+flum+kafka+spark+MySQL
默认配置好了Hadoop的开发环境,并且已经安装好HBASE等组件。
下面通过一个简单的案例进行整合:
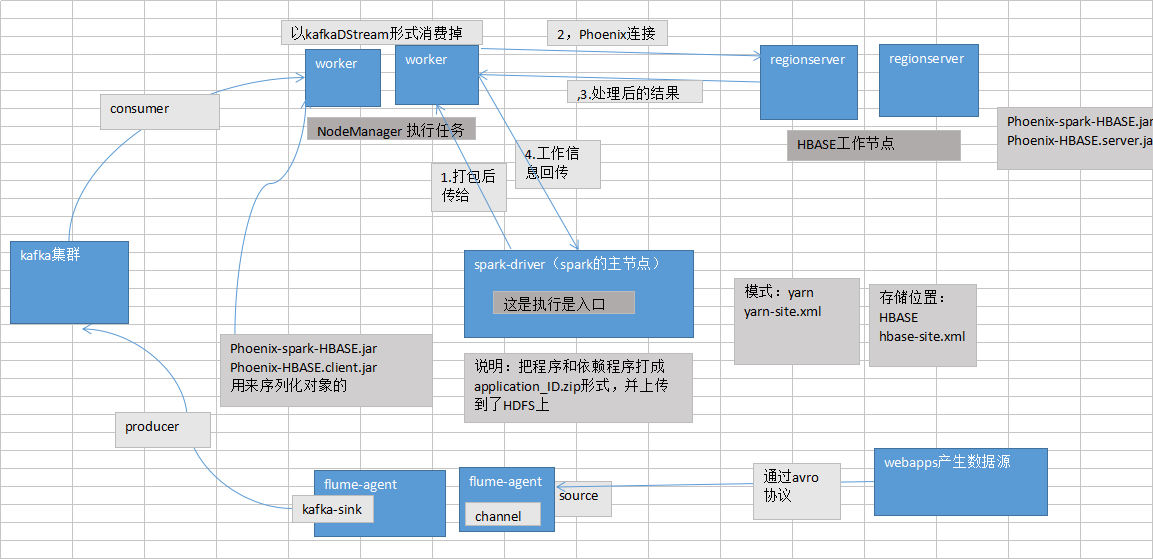
这是整个工作的流程图:
第一步:获取数据源
由于外部埋点获取资源较为繁琐,因此,自己写了个自动生成类似数据代码:
import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; public class Genlog { static String[] srcurls={"http://www.baidu.com","http://www.sougou.com", "http://www.360.com","http://www.taobao.com"}; static String[] oss={"android","ios","mac","win","linux"}; static String[] sexs={"f","m"}; public static void main(String[] args) throws InterruptedException { //http://xxxxx?refurl=http://www.baidu.com&pid=xx&os=andriod&sex=f/m&wx=abc Logger logger=LogManager.getLogger(Genlog.class); while(true){ String srcurl=srcurls[(int) (Math.random()*srcurls.length)]; String os=oss[(int) (Math.random()*oss.length)]; String sex=sexs[(int) (Math.random()*sexs.length)]; String url=String.format("http://xxxxx?refurl=%s&pid=xx&os=%s&wx=abc&sex=%s/m",srcurl,os,sex); logger.info(url); Thread.sleep(300); } } }
这部分代码表示,在启动程序后,将会不断生成类似文中注释类型的数据,这样flume的source端就可以源源不断的获取到数据。
pom.xml文件就是关于log4j的依赖api core 和flum-ng即可,不再赘述。
同时,在项目中,要编写连接虚拟机的配置文件,放在resource下,配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> </Console> <Flume name ="hi" compress="false" type="avro"> <agent host ="192.168.110.101" port="44444"></agent> </Flume> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="Console"/> <AppenderRef ref="hi"></AppenderRef> </Root> </Loggers> </Configuration>
这样,我们的配置数据源的项目就已经完成了,当然,在实际生产中,肯定要比这复杂的多。
第二步:配置flume
配置flume/config/a1.conf,文件可以直接touch创建,配置如下:
# 定义资源 管道 目的地 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 设置源的属性 a1.sources.r1.type =avro a1.sources.r1.bind=192.168.110.101 a1.sources.r1.port=44444 # 设置目的地属性 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.producer.acks = 0 a1.sinks.k1.kafka.topic = mylog a1.sinks.k1.kafka.bootstrap.servers = 192.168.110.101:9092 # 管道属性 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 把源通过管道连接到目的地 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
注意更换自己的IP地址,同时,根据需求更改acks的结果,如1、-1、0,具体介绍看官网即可。此时flume是依赖kafka的。所以启动顺序请先启动kafka,否则会报错。
第三步:编写spark stream项目
项目目标主要是将kafka中的数据拉取下来消费,通过内部逻辑,将数据转变为DataFrame格式,通过Phoenix存储在HBASE上,以方便对数据进行分析。
项目配置文件pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.yzhl</groupId> <artifactId>spark-streaming-phoneix-kafkademo</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.2.1</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>2.11.12</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.2.1</version> <scope>provided</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> </plugin> </plugins> </build> </project>
逻辑代码如下:
import org.apache.kafka.clients.consumer.ConsumerConfig import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.sql.SparkSession import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} object LogSave extends App { //定义brokers, groupId, topics /** * 关于driver和worker的执行位置的代码 */ val Array(brokers, groupId, topics) = Array("192.168.86.128:9092","mylog","mylog")//driver //spark上下文对象相当于connection val spark = SparkSession.builder().appName("mylog").getOrCreate()//driver //创建spark streaming 上下文 val ssc = new StreamingContext(spark.sparkContext, Seconds(5))//driver val topicsSet = topics.split(",").toSet//driver //定义kafka配置属性 val kafkaParams = Map[String, Object]( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers, ConsumerConfig.GROUP_ID_CONFIG -> groupId, ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer], ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])//driver //使用KafkaUtils工具来的createDirectStream静态方法创建DStream对象 val messages = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))//driver //messages中的每一条数据都是一个(key,value) 其中value指的是log中的一行数据 val lines = messages.map(_.value)//worker import spark.implicits._//driver worker //在driver端编译成了class,之后上传到worker中 case class MyRecord(id:String,time:String,srcUrl:String,os:String,sex:String) //为记录产生ID lines.print(5)//driver //foreachRDD在driver上执行, lines.foreachRDD((rdd,t) =>{ val props = scala.collection.mutable.Map[String,String]()//driver props += "table" -> "tb_mylog" props += "zkUrl" -> "jdbc:phoenix:hadoop" //从下面到toDF.都会放在worker上执行 rdd.zipWithUniqueId().map( x =>{ val p =""".+(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}).+refurl=(.*)&.+&os=(.+)&.+&sex=(.+)""".r x._1 match { case p(time,srcUrl,os,sex) => MyRecord(t.toString()+x._2,time,srcUrl,os,sex) case _ => MyRecord(null,null,null,null,null) } }).filter(_.id !=null).toDF().write.format("org.apache.phoenix.spark") .mode("overwrite") .options(props).save();//todf--save之间都是在worker上执行,save()是在driver上 }) ssc.start()//driver ssc.awaitTermination()//driver /** * spark的所有上下文的创建都在driver上执行 * spark的所有action都在driver上执行 * spark的所有transformation都在worker上执行 * */ }
这部分代码可以将拉取的数据进行格式化 的存储。其中正则表达式是对数据行的拆分,并通过Phoenix存储到HBASE上。
第四步:项目打包
我用的idea,打包很简单,maven-->plugins-->scala:compile(编译)-->Lifecycle的package 即可打包完成,可在target目录下查看。
eclipse的打包也很简单,网上一大堆。
到此,在代码阶段的操作基本完成,接下来就是在集群上的运行过程。
第五步:启动各个进程
本次的部署是在yarn上的,所以肯定有yarn的启动。我们按照顺序启动。
1,启动HDFS:start-dfs.sh
2.启动yarn:start-yarn.sh
3.启动zookeeper:如果是自己安装的zookeeper,可以直接用./zkServer.sh start
如果是用kafka自带的zookeeper,启动命令:bin/zookeeper-server-start.sh config/zookeeper.properties
4.启动kafka:bin/kafka-server-start.sh config/server.properties
5.启动flume:bin/flume-ng agent -n a1 -c conf -f conf/a1.conf 此时可以启动数据源的生成项目运行
6.启动kafka的消费者consumer:bin/kafka-console-consumer.sh --bootstrap-server 192.168.110.101:9092 --topic mylog
7.启动HBASE:start-hbase.sh
8.启动Phoenix: ./sqlline.py localhost
第六步:以上进程都启动成功后,可以将打包好的jar包上传到系统路径
此时有一个问题一定要注意,不然肯定会报错,列如空指针的异常,但无法查询错误具体信息,根本原因是缺少对于的依赖包。
在下载依赖包的时候,我们还需要将两个必须的依赖包导入到spark的jars文件中,因为我们打包的瘦包,无法包含所有的依赖包。
这两包是:spark-streaming-kafka-0-10_2.11和他的依赖包kafka_2.11。根据你自己的版本不同,找到对应的版本依赖包,否则会报出版本依赖的异常信息。
添加方法:cd到spark的jars目录先,在maven官网,右键点击相应的依赖包的jar,复制路径,运用命令 ”wget 复制的路径”,也可以自己下载到本地后上传。
接着,在启动的Phoenix中,创建我们自己的表,在编码中的表名为tb_mylog,所以创建表:
!create table tb_mylog(id varchar(255) primary key,time varchar(255),srcUrl varchar(255),os varchar(255),sex varchar(20));
此时!tables里面就会存在了tb_mylog个表。
第七步:运行上传的jar包,处理数据
运行命令:spark-submit --master yarn --deploy-mode client --class 包名 jar包
运行后,可以看到数据在不断的写入,spark Stream在不断的获取,此时,进入Phoenix中,
select * from tb_mylog,可以看到数据在表中存在,并不断的增长,如果机器性能不是很好,建议运行一段时间后,可以停掉源数据的生成。
对于关闭HBASE,需要注意,不可直接stop掉HBASE,这样数据就会丢失或者出发预写机制,无法将数据完全的保存到HDFS上,所以停掉HBASE的最好方式是:先运行hbase-daemon.sh stop master,然后在运行stop-hbase.sh. 这样既可。
由于是基于yarn模式,所以要读取到yarn-site.xml文件,所以在spark-env.sh中配置HADOOP_CONF-DIR=Hadoop路径,或者YARN_CONF_DIR=yarn路径。
注意:
如果用Phoenix连接spark,那么需要Phoenix里的Phoenix-spark-hbase.jar和Phoenix-HBASE-client.jar。
且,worker节点通过Phoenix连接HBASE时,自己有了客户端,那么HBASE的regionserver端需要Phoenix-HBASE-server.jar和Phoenix-spark-hbase.jar两个包。
flume通信数据源:通过通信协议avro. 给到flume的source处,通过配置channel后,得到下沉的位置,即得到kafka的producer,然后通过worker节点进行消费,消费形式是kafkaDStream。
接下来是数据的分析,然后存储到MySQL中。
第八步:存储到数据库中的编码
新建项目:
import org.apache.spark.sql.{SaveMode, SparkSession} object ETLSparkSql extends App { val spark = SparkSession.builder().appName("from-hbase-etl-to-mysql using spark+phoenix").getOrCreate()//driver val props = scala.collection.mutable.Map[String,String]() //driver props += "table" -> "tb_mylog" props += "zkUrl" -> "hadoop:2181" val df = spark.read.format("org.apache.phoenix.spark").options(props).load(); df.createOrReplaceTempView("tb_mylog") val df2 = spark.sql("select srcUrl,count(1) as count_nums from tb_mylog group by srcUrl"); df2.createOrReplaceTempView("tb_url_count") val sql = """ |select | case when srcUrl = 'http://www.baidu.com' then count_nums | else 0 end as baidu, | case when srcUrl = 'http://www.souguo.com' then count_nums | else 0 end as souguo, | case when srcUrl = 'http://www.360.com' then count_nums | else 0 end as `360`, | case when srcUrl = 'http://www.taobao.com' then count_nums | else 0 end as `taobao`, | case when srcUrl not in ('http://www.baidu.com','http://www.souguo.com','http://www.taobao.com','http://www.360.com') then count_nums | else 0 end as `qita` | from tb_url_count """.stripMargin val df3 = spark.sql(sql) df3.createOrReplaceTempView("tb_case") val jdbcops = scala.collection.mutable.Map[String,String]() //driver props += "table" -> "tb_log_count" props += "url" -> "jdbc:mysql://192.168.86.1:3306/logdb" props += "user" -> "root" props += "password" -> "root" props += "driver" -> "com.mysql.jdbc.Driver" spark.sql("select sum(baidu),sum(souguo),sum(`360`),sum(taobao),sum(qita) from tb_case").write.format("jdbc").mode(SaveMode.Append).options(jdbcops).save() println("任务提交,等待结果") }
第九步:创建数据库和表
创建logdb的数据库,创建表tb_log_count,列名分别为id,baidu,souguo,360,taobao,qita。
然后对项目进行编译和打包,上传到客户端driver上,
启动HDFS,启动yarn,启动HBASE,同时可以执行编译运行语句:
spark-submit --master yarn --deploy-mode client ETLSparkSql 包名
到此为止,我们的数据的获取,数据的处理,数据的存储,数据的存库都已经完成,可以在MySQL数据库中查看结果了。
新手上路,有不对的地方还请指正。