余弦计算相似度度量
相似度度量(Similarity),即计算个体间的相似程度,相似度度量的值越小,说明个体间相似度越小,相似度的值越大说明个体差异越大。
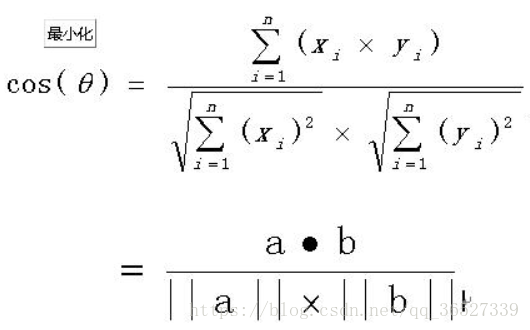
文本相似度计算的处理流程是:
(1)找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)(字面)
是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。(一个词在文章中出现次数越多,同时在所有文档中出现次数越少, 越能够代表该文章,越能反应文章的特性,是我们所需要的关键词)
词频(TF):指一个词在文章中出现的次数

逆文档频率(IDF):IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。

停用词(word stop):出现次数最多的是“的”,“是”,“在”,“我”等等,这类词对结果毫无帮助,必须过滤掉的词
将TF和IDF进行相乘,得到一个词的TF-IDF值,某个词对文章重要性越高,该值越大,于是排在前面几个词,就是这篇文章的关键词TF

TF-IDF与一个词在文档中的出现次数成正比,与包含该词的文档数成反比
实践:
有500多篇文章,利用MapReduce实现TF-IDF值
首先这是508篇文章
其中一篇文章内容,算文本相似度的前提需要对其进行中文分词

由于文件多,所以需要将其整合到一个大的文件,变成一行是一篇文章,将508篇独立文章变成508行。编辑convert.py进行整合
convert.py
import os
import sys
file_path_dir = sys.argv[1]
def read_file_handler(f):
fd = open(f, 'r')
return fd
file_name = 0
for fd in os.listdir(file_path_dir):
file_path = file_path_dir + '/' + fd
content_list = []
file_fd = read_file_handler(file_path)
for line in file_fd:
content_list.append(line.strip())
print '\t'.join([str(file_name), ' '.join(content_list)])
file_name += 1 整合后的效果,以两篇为例(idf_input.data)

run.sh,通过MR框架算出IDF
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1//share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH="/idf_input.data"
OUTPUT_PATH="/tfidf_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.pymap.py,将整合完的文件通过MR框架进行标准输入,根据“\t”分割,然后判断将一些脏数据去掉。分成一个文件名和一个文件内容,根据IDF公式我们需要知道某个词在哪几篇文章中包括,然后在map函数中需要同一片文章中某个词重复出现进行去重,所以将数组word_list利用set()函数进行去重,然后循环遍历打印
import sys
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
file_name, file_content = ss
word_list = file_content.strip().split(' ')
word_set = set(word_list)
for word in word_set:
print '\t'.join([word, '1'])red.py,根据map的输出,然后传入red中对其"\t"分割,去脏数据,循环算出idf
import sys
import math
current_word = None
sum = 0
docs_cnt = 508
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word, val = ss
if current_word == None:
current_word = word
if current_word != word:
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])
current_word = word
sum = 0
sum += int(val)
idf = math.log(float(docs_cnt) / (float(sum) + 1.0))
print '\t'.join([current_word, str(idf)])通过MR跑出来的数据储存在HDFS中,将结果下载到本地part-00000

然后算TF-IDF,单机执行,传入part-00000 idf_input.data 文件名 某个词
tfidf.demo.py,首先对part-00000进行“\t”分割,切割成token,idf,保存到字典idf_dict中;然后对idf_input.data进行“\t”分割,分割成文件名,content,对content进行“ ”分割,循环遍历分割后的数组,如果不在字典tf_dict中,那么添加到字典中,若存在则tf_dict[token] +=1。当输入的token不在这两个字典中,就退出,否则进行tf-idf计算。
import sys
input_idf_dict_path = sys.argv[1]
input_docs_path = sys.argv[2]
input_docid = sys.argv[3]
input_token = sys.argv[4]
idf_dict = {}
with open(input_idf_dict_path,'r') as fd:
for line in fd:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
token,idf=ss
idf_dict[token] = idf
tf_dict = {}
content_size = 0
with open(input_docs_path,'r') as fd:
for line in fd:
ss = line.strip().split('\t')
if len(ss) !=2:
continue
docid,content = ss
if docid != input_docid:
continue
for token in content.strip().split(' '):
if token not in tf_dict:
tf_dict[token] = 1
else:
tf_dict[token] += 1
content_size += 1-
if input_token not in idf_dict or input_token not in tf_dict:
print 'no found token'
sys.exit(-1)
tfidf = float(idf_dict[input_token]) * float(tf_dict[input_token]) / float(content_size)
print '\t'.join([input_docid,input_token,str(tfidf)])查询第9篇里的酷派