背景
- 要解决中文分词准确度问题,是否可以提供一个免费版本的通用分词程序
--像分词这种自然语言处理领域的问题,很难彻底完全解决
--每个行业或业务侧重不同,分词工具设计策略也是不一样的
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
- 字符匹配法分词
1)正向最大匹配法(由左到右的方向)
2)逆向最大匹配法(由右到左的方向)
3)最少切分(使每一句中切出的词数最小)
4)双向最大匹配法(进行由左到右、由右到左两次扫描)
5)复杂最大匹配法- 理解分词(HMM、MEMM、CRF)
- 统计分词方法
最常见的分词方法是基于词典匹配
- 最大长度查找(前向查找,后向查找)
切分方案
• -方案一:切开的开始位置对应位是1,否则对应位是0,来表示“这/苹果不大/好吃”的bit内
容是:1100010
• -方案二:还可以用一个分词节点序列来表示切分方案,例如“这/苹果不大/好吃”的分词节点
序列是{0,1,5,7}

数据结构
- 为了提高效率,不要逐个匹配词典中的词
- 查找词典所占时间可能占总的分词时间的1/3左右,为了保证切分速度,需要选择一个好的查找词典的方法
- Trie树常用于加速分词查找词典问题
朴素贝叶斯公式
• P(C)只是一个用来归一化的固定值
• 另外:从词串恢复到汉字串的概率只有唯一的一种方式,所以P(C|S)=1。
• 所以:比较P(S1|C)和P(S2|C)的大小变成比较P(S1)和P(S2) 的大小
• 因为P(S1)=P(南京市,长江,大桥)=P(南京市)*P(长江)*P(大桥)> P(S2)=P(南京,市
长,江大桥),所以选择切分方案S1。• 为了容易实现,假设每个词之间的概率是上下文无关的,则:
取log是为了防止向下溢出,如果一个数太小,例如
0.000000000000000000000000000001 可能会向下溢出。
• 如果这些对数值事前已经算出来了,则结果直接用加法就可以得到,而加法比乘
法速度更快。
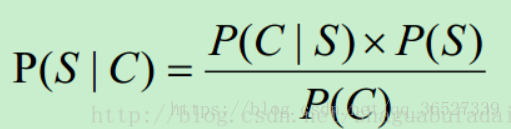
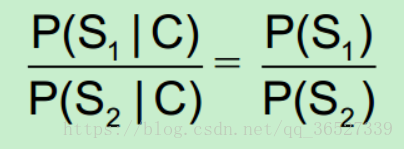
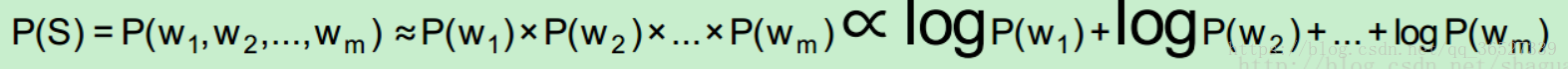
- 一元模型:如果一个词的出现不依赖于它前面出现的词。
- 二元模型:如果简化成一个词的出现仅依赖于它前面出现的一个词。
- 三元模型:如果简化成一个词的出现仅依赖于它前面出现的两个词。
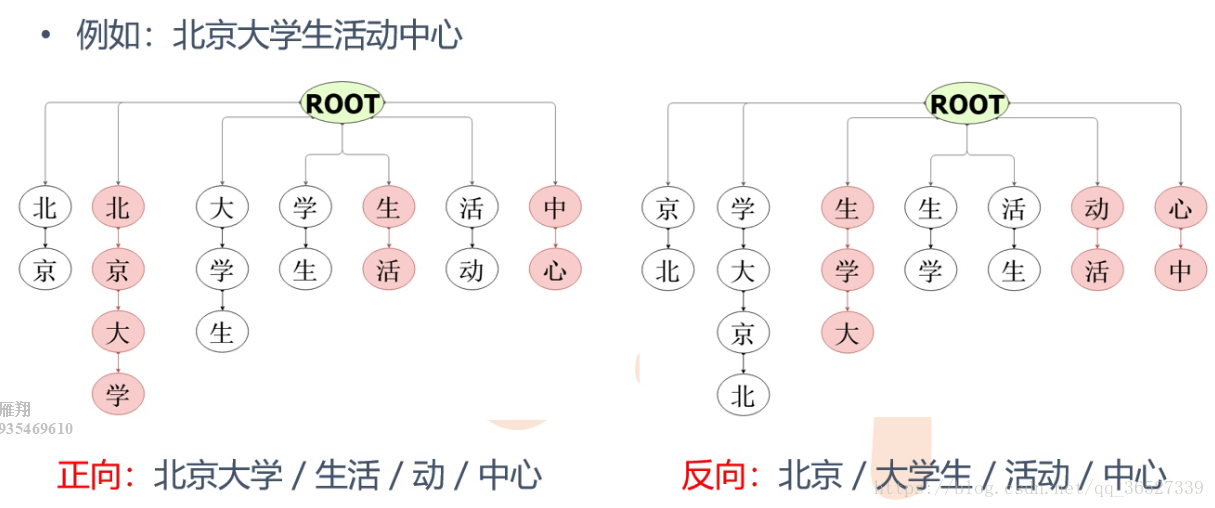
例子:
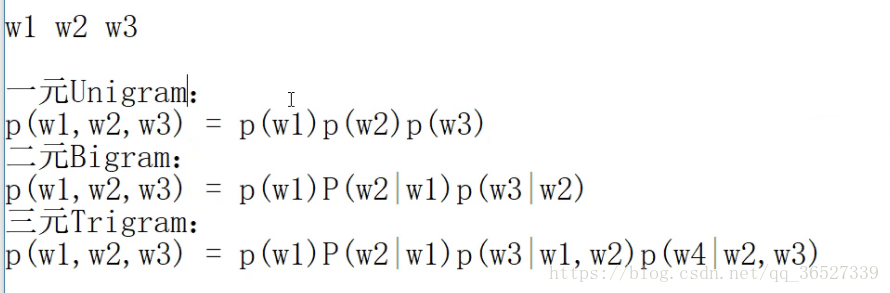
工具为结巴分词,具体内容下篇讲解
中文分词常见方法:https://blog.csdn.net/m0_37710823/article/details/76064408