1、常用设计模式
-
单例模式:懒汉式、饿汉式、双重校验锁、静态加载,内部类加载、枚举类加载。保证一个类仅有一个实例,并提供一个访问它的全局访问点。
-
代理模式:动态代理和静态代理,什么时候使用动态代理。
- https://www.cnblogs.com/daniels/p/8242592.html
-
适配器模式:将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
-
装饰者模式:动态给类加功能。
-
观察者模式:有时被称作发布/订阅模式,观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己。
-
策略模式:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
-
外观模式:为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
-
命令模式:将一个请求封装成一个对象,从而使您可以用不同的请求对客户进行参数化。
-
创建者模式:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
-
抽象工厂模式:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
2、基础知识
-
Java基本类型哪些,所占字节和范围
-
类型 存储要求 范围(包含) 默认值 包装类 整 int 4字节(32位) -231~ 231-1 0 Integer 数 short 2字节(16位) -215~215-1 0 Short 类 long 8字节(64位) -263~263-1 0 Long 型 byte 1字节(8位) -27~27-1 0 Byte 浮点 float 4字节(32位) -3.4e+38 ~ 3.4e+38 0.0f Float 类型 double 8字节(64位) -1.7e+308 ~ 1.7e+308 0 Double 字符 char 2字节(16位) u0000~uFFFF(‘’~‘?’) ‘0’ Character (0~216-1(65535)) 布尔 boolean 1/8字节(1位) true, false FALSE Boolean -
Set、List、Map的区别和联系
- Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap -
什么时候使用Hashmap
- HashMap和HashTable异同点及使用场景
- 线程安全不同
- 是否允许null值不同
- 继承实现方式不同(
HashMap继承于AbstractMap,而Hashtable继承于Dictionary。
- Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。 然而‘由于Hashtable也实现了Map接口,所以,它既支持Enumeration遍历,也支持Iterator遍历。
- )
- 初始容量和扩容策略不同(
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即capacity*2+1
) - 计算hash的方法不同
-
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
-
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸
- 使用场景
-
非并发场景使用HashMap,并发场景可以使用Hashtable,但是推荐使用ConcurrentHashMap(锁粒度更低、效率更高)。
-
另外使用在使用HashMap时要注意null值的判断,
Hashtable也要注意防止put null key和 null value。 -
HashMap提供对key的Set进行遍历,因此它是fail-fast的,但HashTable提供对key的Enumeration进行遍历,它不支持fail-fast
-
什么时候使用Linkedhashmap、Concurrenthashmap、Weakhashmap
- https://blog.csdn.net/yxy000/article/details/70214090
- https://blog.csdn.net/wxc880924/article/details/52683097
-
哪些集合类是线程安全的
-
Vector:就比Arraylist多了个同步化机制(线程安全)。
Hashtable:就比Hashmap多了个线程安全。
ConcurrentHashMap:是一种高效但是线程安全的集合。
Stack:栈,也是线程安全的,继承于Vector。
-
为什么Set、List、map不实现Cloneable和Serializable接口
- 克隆(cloning)或者序列化(serialization)的语义和含义是跟具体的实现相关的。因此应该由集合类的具体实现类来决定如何被克隆或者序列化
-
Concurrenthashmap的实现,1.7和1.8的实现
- https://blog.csdn.net/bolang789/article/details/79855053
-
Arrays.sort的实现
- 双轴排序算法https://blog.csdn.net/github_38838414/article/details/80642329
-
什么时候使用CopyOnWriteArrayList
- CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
- https://blog.csdn.net/sc313121000/article/details/50682064
-
volatile的使用
- volatile是一种轻量级的同步机制,它主要有两个特性:一是保证共享变量对所有线程的可见性;二是禁止指令重排序优化。同时需要注意的是,volatile对于单个的共享变量的读/写具有原子性,但是像num++这种复合操作,volatile无法保证其原子性,当然文中也提出了解决方案,就是使用并发包中的原子操作类,通过循环CAS地方式来保证num++操作的原子性。
-
synchronied的使用
- https://blog.csdn.net/luoweifu/article/details/46613015
-
reentrantlock的实现和Synchronied的区别
- 这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
- https://blog.csdn.net/chenchaofuck1/article/details/51045134
-
CAS的实现原理以及问题
-
AQS的实现原理
- https://www.cnblogs.com/waterystone/p/4920797.html
-
接口和抽象类的区别,什么时候使用
- https://blog.csdn.net/u012092924/article/details/78342193
-
类加载机制的步骤,每一步做了什么,static和final修改的成员变量的加载时机
-
双亲委派模型
-
反射机制:反射动态擦除泛型、反射动态调用方法等
-
动态绑定:父类引用指向子类对象
-
JVM内存管理机制:有哪些区域,每个区域做了什么
-
JVM垃圾回收机制:垃圾回收算法 垃圾回收器 垃圾回收策略
-
jvm参数的设置和jvm调优
-
什么情况产生年轻代内存溢出、什么情况产生年老代内存溢出
-
内部类:静态内部类和匿名内部类的使用和区别
-
内部类:
成员内部类可访问外部类所有的方法和成员变量。
不能有静态的方法和成员变量。
静态内部类:
只能访问外部类的静态成员变量与静态方法。
静态内部类的非静态成员可访问外部类的静态变量,而不可访问外部类的非静态变量。
匿名内部类:
没有类名,没有class关键字也没有extends和implements等关键字修饰。
类的定义和对象的实例化同时进行。
-
Redis和memcached:什么时候选择redis,什么时候选择memcached,内存模型和存储策略是什么样的
- https://www.cnblogs.com/timothy-lai/p/5786502.html
-
MySQL的基本操作 主从数据库一致性维护
-
mysql的优化策略有哪些
- https://blog.csdn.net/liuyanqiangpk/article/details/79827239
-
mysql索引的实现 B+树的实现原理
- https://blog.csdn.net/qq_23217629/article/details/52512041
-
什么情况索引不会命中,会造成全表扫描
- 索引失效的例子https://www.cnblogs.com/areyouready/p/7802885.html
-
java中bio nio aio的区别和联系
- https://blog.csdn.net/qq_24693837/article/details/70335491?locationNum=4&fps=1
-
为什么bio是阻塞的 nio是非阻塞的 nio是模型是什么样的
-
Java io的整体架构和使用的设计模式
-
Reactor模型和Proactor模型
-
http请求报文结构和内容
-
http三次握手和四次挥手
-
rpc相关:如何设计一个rpc框架,从io模型 传输协议 序列化方式综合考虑
-
Linux命令 统计,排序,前几问题等
- sort data | uniq -c | sort -k 1 -n -r | head 10
-
StringBuff 和StringBuilder的实现,底层实现是通过byte数据,外加数组的拷贝来实现的
-
cas操作的使用
- https://www.cnblogs.com/hupu-jr/p/7927635.html
-
内存缓存和数据库的一致性同步实现
-
微服务的优缺点
-
微服务优点
1、通过分解巨大单体式应用为多个服务方法解决了复杂性问题,每个微服务相对较小
2、每个单体应用不局限于固定的技术栈,开发者可以自由选择开发技术,提供API服务。
3、每个微服务独立的开发,部署
4、单一职责功能,每个服务都很简单,只关注于一个业务功能
5、易于规模化开发,多个开发团队可以并行开发,每个团队负责一项服务
6、改善故障隔离。一个服务宕机不会影响其他的服务
微服务缺点:
1.开发者需要应对创建分布式系统所产生的额外的复杂因素
l 目前的IDE主要面对的是单体工程程序,无法显示支持分布式应用的开发
l 测试工作更加困难
l 需要采用服务间的通讯机制
l 很难在不采用分布式事务的情况下跨服务实现功能
l 跨服务实现要求功能要求团队之间的紧密协作
2.部署复杂
3.内存占用量更高
-
线程池的参数问题
-
ip问题 如何判断ip是否在多个ip段中
-
判断数组两个中任意两个数之和是否为给定的值
-
乐观锁和悲观锁的实现
-
synchronized实现原理
-
你在项目中遇到的困难和怎么解决的
-
你在项目中完成的比较出色的亮点
-
消息队列广播模式和发布/订阅模式的区别
-
生产者消费者代码实现
-
死锁代码实现
- https://blog.csdn.net/jyy305/article/details/70077042
-
线程池:参数,每个参数的作用,几种不同线程池的比较,阻塞队列的使用,拒绝策略
-
Future和ListenableFuture 异步回调相关
-
算法相关:判断能否从数组中找出两个数字和为给定值,随机生成1~10000不重复并放入数组,求数组的子数组的最大和,二分查找算法的实现及其时间复杂计算
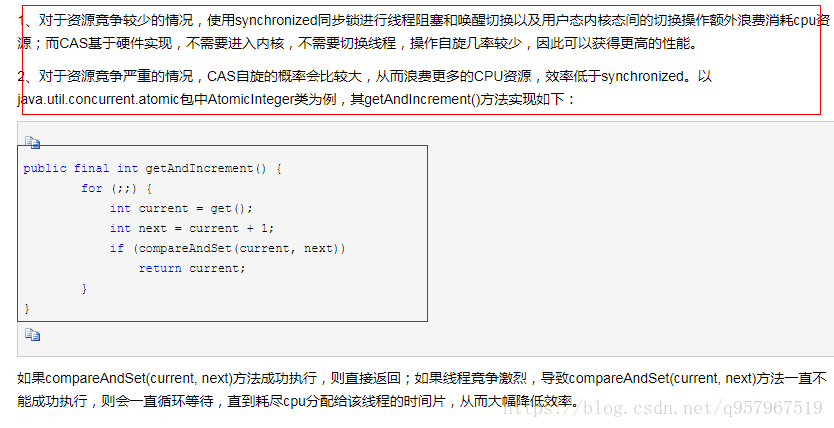
3、其它
-
算法:常用排序算法,二分查找,链表相关,数组相关,字符串相关,树相关等
-
常见序列化协议及其优缺点
-
memcached内存原理,为什么是基于块的存储
-
搭建一个rpc需要准备什么
-
如果线上服务器频繁地出现full gc ,如何去排查
- https://blog.csdn.net/wilsonpeng3/article/details/70064336
-
如果某一时刻线上机器突然量变得很大,服务扛不住了,怎么解决
-
LUR算法的实现
-
LinkedHashMap实现LRU
-
定义栈的数据结构,请在该类型中实现一个能够找到栈最小元素的min函数
-
海量数据处理的解决思路
-
reactor模型的演变
-
阻塞、非阻塞、同步、异步区别
-
Collection的子接口
-
jvm调优相关
-
zookeeper相关,节点类型,如何实现服务发现和服务注册
-
nginx负载均衡相关,让你去实现负载均衡,该怎么实现
-
linux命令,awk、cat、sort、cut、grep、uniq、wc、top等
-
压力测试相关,怎么分析,单接口压测和多情况下的压测
-
你觉得你的有点是什么,你的缺点是什么
-
spring mvc的实现原理
-
netty底层实现,IO模型,ChannelPipeline的实现和原理
-
缓存的设计和优化
-
缓存和数据库一致性同步解决方案
-
你所在项目的系统架构,谈谈整体实现
-
消息队列的使用场景
-
ActiveMQ、RabbitMQ、Kafka的区别