版权声明:本文为博主原创文章,请随意转载。 https://blog.csdn.net/a_hui_tai_lang/article/details/83040522
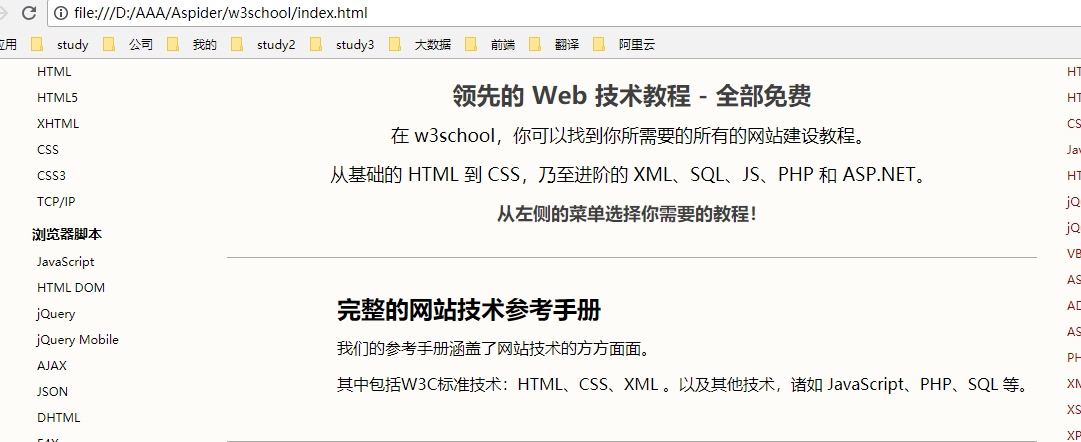
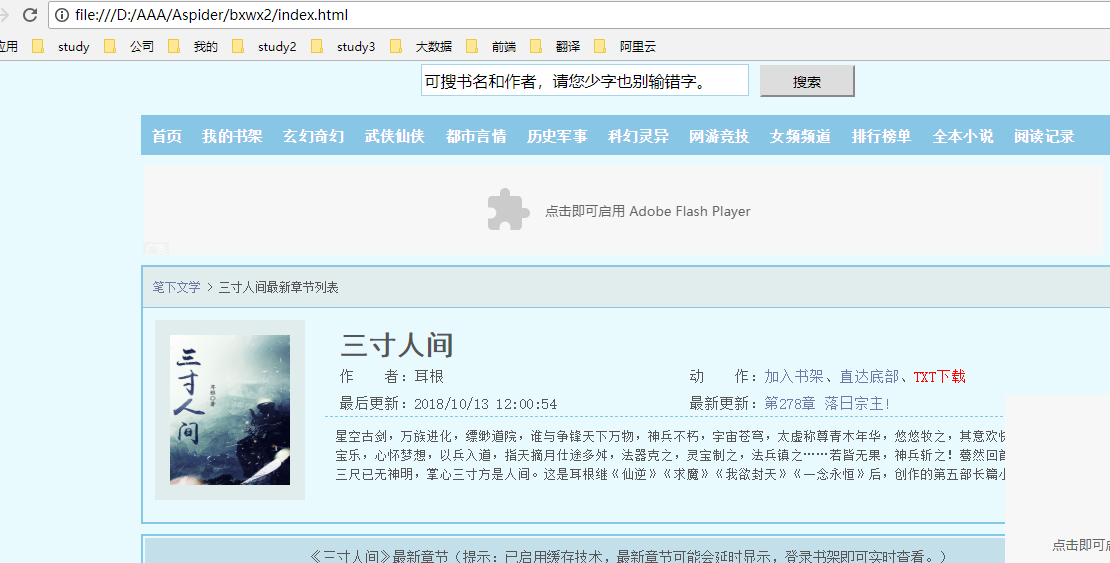
每每看到一些漂亮的网页就忍不住想把它下载下来,查看的HTML源码、调试、改造。因此就根据自己的想法制作了一个扒取网页到本地python爬虫代码,爬取一般的网页,效果还行,真是前端,UI必备神器。先看看我爬取到本地的网页,显示效果如下:
代码如下:
#coding=utf-8
import ssl
import urllib
import urllib2
import os
from lxml import etree
import traceback
def mkdir(path):
'''
可以创建多级目录
:param path:
:return:
'''
path = path.strip().rstrip("\\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
print path + ' 创建成功'
return True
else:
print path + ' 目录已存在'
return False
class staticSpider():
'''
静态页面的爬取类
默认图片放在img/下,js放在scripts/下,css放在css/下
'''
def __init__(self,baseUrl, url,basePath):
'''
目录必须带'/',
baseUrl是指http://域名/,baseUrl必须以'/'结尾
url是指需要下载的页面,如http://域名/xx/yy.html
basePath是指要保存到哪个目录下面,必须以'/'结尾
'''
self.baseUrl = baseUrl
self.basePath = basePath
self.url=url
self.html=''
self.mode=0
self.urlDic={}
def getAbsoluteUrl(self,url):
'''
一个网页url可能是相对路径
这个方法可以根据url来获取一个可以访问的url
:param url:
:return:
'''
if url.startswith('/'):
return urllib.basejoin(self.baseUrl,url)
else:
return urllib.basejoin(self.url,url)
def getSourceCode(self, url):
'''
根据url获取网页源码,即HTML
:param url:
:return:
'''
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
context = ssl._create_unverified_context()
request = urllib2.Request(url, headers=headers)
print url
return urllib2.urlopen(request,context=context).read()
def writePage(self, html, filename, mode='w'):
"""
作用:将html内容写入到本地
html:服务器相应文件内容
"""
print "正在保存 " + filename
# 文件写入
with open(filename, mode) as f:
f.write(html)
print "-" * 30
def writePicture(self, url, filename=''):
'''
根据url获取图片并保存到本地
:param url:
:param filename:
:return:
'''
if filename == '':
filename = self.getFileName(url)
abUrl=self.getAbsoluteUrl(url)
pic=self.getSourceCode(abUrl)
self.writePage(pic, filename, 'wb')
def downloadUrl(self, url, filename='',mode='w'):
'''
直接根据url下载HTML,保存到本地
:param url:
:param filename:
:param mode:
:return:
'''
if filename == '':
filename = self.getFileName(url)
abUrl=self.getAbsoluteUrl(url)
try:
pic=self.getSourceCode(abUrl)
self.writePage(pic, filename, mode)
except Exception:
traceback.print_exc()
def getFileName(self,url):
'''
给个url获取对应的保存到本地文件名
:param url:
:return:
'''
url=url.rstrip('\\').rstrip('/')
index = url.rfind('\\')
index1 = url.rfind('/')
if index<index1:
index=index1
filename = url[index+1:]
if filename=='':
filename='index.html'
return filename
def parseUrl(self,url):
self.html = self.getSourceCode(url)
return self.html
def downloadByType(self, savePath, getList, url='', mode='w'):
'''
这个是一个比较灵活的方法,可以传一个getList方法获取一系列需要爬取的url,
然后将url对应的源码或者文件爬取,下载到本地
:param savePath:
:param getList: 这是一个方法,需要传一个参数(HTML源码),返回一个url列表,比如:urlList = getList(html)
:param url:
:param mode:
:return:
'''
if url == '':
html = self.html
else:
html = self.getSourceCode(url)
urlList = getList(html)
print 'downloadByType', urlList
for eUrl in urlList:
filename = self.getFileName(eUrl)
self.html = self.html.replace(eUrl, savePath[len(self.basePath):] + filename)
print self.getAbsoluteUrl(eUrl)
try:
css = self.getSourceCode(self.getAbsoluteUrl(eUrl))
self.writePage(css, savePath + filename, mode)
except Exception:
traceback.print_exc()
def downloadPicture(self, url=''):
'''
下载页面所需要的图片,保存到img/下
:param url:
:return:
'''
basePath = self.basePath.rstrip("/")
def getPicList(html):
selector = etree.HTML(self.html)
imgList = selector.xpath("//img/@src")
imgList2 = selector.xpath("//link[contains(@href,'.')]/@href")
urlSet=set(imgList+imgList2)
return [img for img in urlSet if (img.endswith('.png') or img.endswith('.jpg') or img.endswith('.jpeg') or img.endswith('.gif') or img.endswith('.ico')) ]
mkdir(basePath + 'img/')
self.downloadByType(self.basePath + 'img/', getPicList, url=url,mode='wb')
def downloadJs(self, url='', filename=''):
'''
下载页面所需要的图片,保存到script/下
:param url:
:param filename:
:return:
'''
basePath = self.basePath.rstrip("/")
def getCssList(html):
selector = etree.HTML(self.html)
jsList=selector.xpath("//script[contains(@src,'.js')]/@src")
return [i for i in jsList if i.endswith('.js')]
mkdir(basePath + 'script/')
self.downloadByType(self.basePath + 'script/', getCssList, url=url)
def downloadCss(self, url='', filename=''):
'''
下载页面所需要的css,保存到css/下
:param url:
:param filename:
:return:
'''
basePath = self.basePath.rstrip("/")
def getCssList(html):
selector = etree.HTML(self.html)
cssList = selector.xpath("//link[contains(@href,'.css')]/@href")
return [i for i in cssList if i.endswith('.css')]
mkdir(basePath+'css/')
self.downloadByType(self.basePath+'css/',getCssList,url=url)
def download(self,url,filename='index.html'):
'''
下载静态页面,以及相关的css,js,默认保存的页面文件名为index.html
:param url:
:param filename:
:return:
'''
self.parseUrl(self.url)
self.downloadCss(url)
self.downloadJs(url)
self.downloadPicture(url)
self.writePage(self.html,self.basePath+filename)
url='https://www.bxwx.la/b/53/53693/'
spider=staticSpider('https://www.bxwx.la/',url,'D:\\AAA\\Aspider\\bxwx2\\')
spider.download(url)
代码主要用来爬取单个静态页面,有些地方我希望写的灵活点,有点函数式编程的味道,这个类也是可以扩展的,可以通过继承这个类改写其中的一些方法,实现一个定制的页面爬取。
download()方法是一个通用的下载,会把网页,css,js都下载下来,如果还有一些比较特殊的css或js没有下载下来,可以使用downloadUrl单独下载。
代码放在GitHub上,python-learning
以上具体代码在目录crawler/static_web/web_common.py
我的GitHub
我建了一个大数据的学习交流群
QQ:2541692705
Q群:882855741
邮箱:[email protected]
微信公众号:程序国度
