1. 理解基础图像分类、数据驱动方法和流程
understand the basic Image Classification pipeline and the data-driven approach (train/predict stages)
1.1 图像分类(Image Classification)
图像分类问题,即输入一张图像,将图像从已有分类中,进行分类,给出分类标签
计算机看到的图像和人所看到的图像是不一样的,计算机看到的只是一连串的数据
一张图片,在计算机里表示为一个三维数组(长、高、三个颜色通道RGB)
计算机视觉算法在图像识别方面的困难:
- 视角变化 (Viewpoint variation): 同一个物体,摄像机从不同角度观察到是不一样的表现
- 大小变化 (Scale variation): 物体可视大小会变化
- 形变 (Deformation): 很多物体的形状会改变
- 遮挡 (Occlusion): 物体可能会被遮挡,只有一小部分可见(可能只有几个像素)
- 光线条件 (Illumination conditions): 光照对像素的影响很大
- 背景干扰 (Background clutter): 背景会影响辨认物体
- 类内差异 (Intra-class variation): 同一类物体之间也会有很大的差异
1.2 数据驱动方法(data-driven approach)
- 收集大量图像数据,并将图像数据分好类
- 使用机器学习去训练图像分类器
- 使用测试图像去评估图像分类器
代码中有两个部分,训练和预测:
def train (train_images, train_labels):
return model
def predict (model, test_images)
return test_labels2. 理解如何分割训练集得到验证集,来对超参数调优
understand the train/val/test splits and the use of validation data for hyperparameter tuning.
先通过Nearest Neighbor分类器来得到超参数的概念
2.1 Nearest Neighbor分类器
为了不用费劲去找到大量的图片并对其分类,使用一个图像分类数据集:CIFAR-10
CIFAR-10数据集中有60000张32*32的图像,每张图像属于10种分类标签的一种,分为50000张训练集和10000张测试集
Nearest Neighbor算法会用测试图片和训练集中每一张图片去比较,选择最相似的那张训练集中的图片的标签作为自己的标签
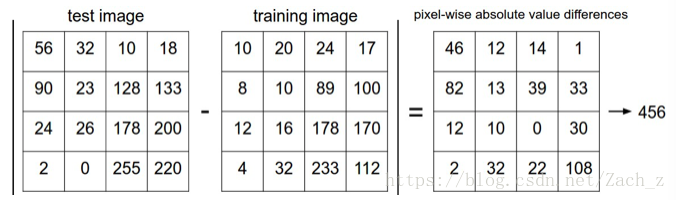
比较方法: 将 长32 高32 颜色通道为3 的像素块逐个比较,将差异值加起来
2.2 距离选择
逐个像素块比较有很多方法:
- L1距离(Mangattan distance):
d_1(I_1,I_2) = \sum_p |I_1^p-I_2^p|即取每个像素差值的绝对值之和
- L2距离 (Euclidean distance):
d_2(I_1,I_2) = \sqrt{\sum_p (I_1^p-I_2^p)^2}即取每个像素差值平方的和再开方
2.3 k-Nearest Neighbor分类器
刚才Nearest Neighbor分类器只用最相似的一张图片的标签作为测试图像的标签,如果选出k张与测试图像最相近的训练集中图像,选择当中标签最多的,便是k-Nearest Neighbor分类器
k-Nearest Neighbor分类器的抗干扰性更好,使测试更泛化,但是如何选择k值?
到底是选择3张最近似图像,还是5张,7张
2.4 超参数调优
==类似L1、L2、k这些参数,称为超参数==
我们需要得到使算法性能更加良好的超参数,则需要来调整超参数
首先规定一点:不能用测试集来调优,如果使用测试集调优,算法实际的应用便不能达到预期效果
选取验证集:
- 可以从训练集中分出一部分作为验证集,比如50000张训练集分成49000张训练集和1000张验证集
- 如果训练集数量较小,还可以使用交叉验证方法,把训练集平分成5份,4份用来训练,1份用来验证,循环测试5次取平均值
3. 使用numpy库来写高效的向量化代码
develop proficiency in writing efficient vectorized code with numpy
4. 实现一个(kNN)分类器
implement and apply a k-Nearest Neighbor (kNN) classifier
- 包含相关库
import random
import numpy as np
import matplotlib.pyplot as plt
from six.moves import cPickle as pickle
import os
import platform- 读出训练集和测试集工具函数
def load_pickle(f):
version = platform.python_version_tuple() #将当前python版本输出成一个元祖 3.6.3 = ('3', '6', '3')
if version[0] == '2':
return pickle.load(f) # 将f中的对象序列化读出
elif version[0] == '3':
return pickle.load(f, encoding='latin1')
raise ValueError("invalid python version: {}".format(version))
def load_CIFAR_batch(filename):
with open(filename, 'rb') as f: #二进制读方式打开文件
datadict = load_pickle(f) # 将f中的对象序列化读出
X = datadict['data'] # 取出字典里 键值为data
Y = datadict['labels'] # 取出字典里 键值为 labels
X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float") # X变为4维FLOAT数组,并且调整维度位置 (10000,32,32,3)
Y = np.array(Y) # Y 转换为数组
return X, Y
def load_CIFAR10(ROOT):
xs = []
ys = []
for b in range(1,6):
f = os.path.join(ROOT, 'data_batch_%d' % (b, )) # 将 ROOT 和 ‘data_batch_x' x=1,2...5 组成新目录f
X, Y = load_CIFAR_batch(f) # 得到 X =
xs.append(X) #
ys.append(Y)
Xtr = np.concatenate(xs) # 将多个数组进行连接 得到 训练集 图像数据
Ytr = np.concatenate(ys) # 将多个数组进行连接 得到 训练集 分类标签
del X, Y
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch')) #得到测试组的 图像数据 和 分类标签 数组
return Xtr, Ytr, Xte, Yte- 读取图像数据,并显示每个标签分类的前七张:
plt.rcParams['figure.figsize'] = (10.0, 8.0) # 设置figure_size尺寸,即设置像素
plt.rcParams['image.interpolation'] = 'nearest' # 设置差值法为nearest
plt.rcParams['image.cmap'] = 'gray' #设置颜色风格为gay
cifar10_dir = 'cifar-10-batches-py'
# 清除之前加载数据产生的变量
try:
del X_train, y_train
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
# 加载出来训练集的 图像数据和标签 测试集的图像数据和标签
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
classes = ['plane', 'car', 'brid', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7 #显示前七张图像
for y, cls in enumerate(classes): # 循环遍历classes
idxs = np.flatnonzero(y_train == y) # 找出 训练集中标签分类 == y (y是classes下标 ,训练集中标签按照1——7标志分类,可以print(y_test)看到
idxs = np.random.choice(idxs, samples_per_class, replace=False) # 从idxs中随机选出 samples_per_class个
for i, idx in enumerate(idxs):
plt_idx = i * num_classes +y +1 # 第 i 行 y 列 图像
plt.subplot(samples_per_class, num_classes, plt_idx) # samples_per_class: 行 num_classes: 列 plt_idx: 指定所在区域
plt.imshow(X_train[idx].astype('uint8')) # 显示索引为 plt_idx的图像
plt.axis('off') #关闭坐标轴
if i == 0:
plt.title(cls) # 小标题显示 classes[y]
plt.show() # 显示图片- 取出5000张作为训练数据,500张作为测试数据:
#取训练集中50000张图片中的前5000张
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
#取测试集中5000张图片中的前500张
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# 把训练集和测试集的图像数据,由四维数组变成二维数组, 32*32*3 ==》 3072
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0],-1))
print(X_train.shape, X_test.shape)- KNN分类器类:
class KNearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X, k=1, num_loops=0):
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops ==1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dosts = self.compute_distance_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k = k)
def compute_distances_two_loops(self, X): #两次循环计算
num_test = X.shape[0] #测试组数目
num_train = self.X_train.shape[0] #训练集数目
dists = np.zeros((num_test, num_train)) #创建一个二维数组
for i in range(num_test): # 500个测试图像
for j in range(num_train): #5000个训练图像
dists[i][j] = np.sqrt(np.sum((X[i] - self.X_train[j]) ** 2)) # 开方(像素之差求和((测试每个像素-训练每个像素)^2))
return dists
def compute_distances_one_loop(self, X): #一次循环计算
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros ((num_test, num_train))
for i in range(num_test):
dists[i] = np.sqrt(np.sum((self.X_train - X[i]) ** 2, 1)) # 下面数字指行列的数量:
# [5000,3072] - [1,3072] = [5000,3072]
#sum([5000,3072], axis=1) = [1, 5000]
# dist = [500, 5000]
return dists
def compute_distances_no_loops(self, X):# 不用循环计算
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros ((num_test, num_train))
dists += np.sum(self.X_train ** 2, axis = 1).reshape(1, num_train) # [1,5000] 一行 5000列
dists += np.sum(X ** 2, axis=1).reshape(num_test, 1) # [1,500].reshape[500,1] 500行 1列
dists -= 2 * np.dot(X, self.X_train.T) # 矩阵点积 相当于 (a-b)^2 = a^2+b^2-2ab
dists = np.sqrt(dists) #
return dists
def predict_labels(self, dists, k=1):
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = []
closest_y = self.y_train[np.argsort(dists[i])[0:k]] # argsort : 得到从小到大排序后的下标,取训练集分类标签从小到大0——k下标里标签
y_pred[i] = np.bincount(closest_y).argmax() # 取出最近分类标签 bincount:计数0——7数字出现次数 argmax:返回的是最大数的索引
return y_pred- 实例化KNN类,并训练和测试数据,并且得到优化算法的时间等:
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)
dists = classifier.compute_distances_two_loops(X_test)
print (dists.shape)
plt.imshow(dists, interpolation='none')
plt.show()
# 画图出来会有一些横竖的白线(距离越远颜色越白)
# 横的白线是因为测试图像跟大部分的训练图像差距都很大
# 竖的白线是因为这一训练图像跟大部分测试图像差别都很大
y_test_pred = classifier.predict_labels(dists, k=1)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print ('k=1: Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
y_test_pred = classifier.predict_labels(dists, k=5)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print ('k=5: Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
dists_one = classifier.compute_distances_one_loop(X_test)
difference = np.linalg.norm(dists - dists_one, ord='fro') #两个矩阵之差的范数
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different')
dists_two = classifier.compute_distances_no_loops(X_test)
difference = np.linalg.norm(dists - dists_two, ord='fro')
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different')
def time_function(f, *args): # 计算函数执行完所需时间
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print('Two loop version took %f seconds' % two_loop_time)
one_loop_time = time_function(classifier.compute_distances_one_loop, X_test)
print('One loop version took %f seconds' % one_loop_time)
no_loop_time = time_function(classifier.compute_distances_no_loops, X_test)
print('No loop version took %f seconds' % no_loop_time)- 用Cross-validation来进行超参数调优
# Cross-validation 来进行超参数调优
for k_ in k_choices:
k_to_accuracies.setdefault(k_, [])
for i in range(num_folds):
classifier = KNearestNeighbor()
X_val_train = np.vstack(X_train_folds[0:i] + X_train_folds[i+1:])
y_val_train = np.vstack(y_train_folds[0:i] + y_train_folds[i+1:])
y_val_train = y_val_train[:,0]
classifier.train(X_val_train, y_val_train)
for k_ in k_choices:
y_val_pred = classifier.predict(X_train_folds[i], k=k_)
num_correct = np.sum(y_val_pred == y_train_folds[i][:,0])
accuracy = float(num_correct) / len(y_val_pred)
k_to_accuracies[k_] = k_to_accuracies[k_] + [accuracy]
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies)
# 把不同k值的准确率 图表显示出来
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
best_k = 10
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)
y_test_pred = classifier.predict(X_test, k=best_k)
# Compute and display the accuracy
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))